









第一章算法概述
估算运行次数
1、

2、
复杂度分析
(1)时间复杂度
定义:



习题:
递归算法的时间复杂度分析

空间复杂度


2、请分析算法4的时间复杂度和空间复杂度,并给出一个更好的求解方法及求解步骤。
算法4: nQueens (int t)
{
if (t==n)
print(x);
else{
for(i=0;i<n;i++)
{x[t]=i;
if(OK(t))
nQueens(t+1);
}
}
时间复杂度 O(n!)
空间复杂度:O(n^2)
算法改进:利用约束条件和限界条件判断是否为可行解,从而避免了无效搜索。
3、(10分)请分析算法5的时间复杂度和空间复杂度,并给出算法5的非递归算法。
算法5:
Def backtrack( t){//地图着色问题
Global colors,x,sum1,n,m,a
if(t>n){ //到达叶子,找到一个着色方案
sum1+=1
colors.append(x[:])
else:
for I in range(1,m+1):
x[t]=i
if(Ok(t)):
backtrack(t+1)
时间复杂度:O(nm^n)
非递归程序代码
void BackTrack(int n)
{
color[1] = 1; //第一个点先染色
for (int t = 2; t <= n; t++) //从第二个点开始染色
{
int f = 0; //假设t点与染色点都有联系
for (int j = 1; j < t; j++) // t点之前的都已经染色,查找t点与染色点是否有联系
{
if (graph[t][j] != 1) //有个点与t点无联系
{
f = 1; //假设失败
color[t] = color[j]; //无联系则颜色可以相同
break;
}
}
if (f == 0) //假设成功
{
color[t] = m + 1; //都有联系只能染新颜色
m++;
}
}
for (int i = 1; i <= n; i++) //输出各点颜色
{
cout << color[i] << " ";
}
cout << endl;
}
三、复杂度分析及创新:(每题10分,共 30 分)
1、分析算法3的时间复杂度和空间复杂度。
算法3:
int partition(int r[], int low, int high){
int i=low, j=high, pivot=r[low];
while(i<j){
while(i<j && r[j]>pivot) j--; //从右向左扫描
if(i<j)
swap(r[i++], r[j]);
while(i<j && r[i]<=pivot) i++; //从左向右扫描
if(i<j)
swap(r[i], r[j--]);
}
return i;
}
时间复杂度:
最坏: O ( n * n )
最好: T ( n )= o (1) n <=1
2T( n /2)+ O ( n ) n >1
由主方法得 O ( nlogn )
空间复杂度:
最坏: o ( n )
最好: O ( logn )
(13分)游艇俱乐部在长江上设置了n个游艇出租站,游客可以在上游的出租站租用游艇,在下游的任何一个游艇出租站归还游艇。游艇出租站i到出租站j(i<j)之间的租金为r(i, j)。求解从游艇出租站1到游艇出租站n所需的最少的租金。
(1)写出选用的算法策略(2分)。
(2)写出该算法策略的思想(4分)。
(3)写出求解问题所用的数据结构(2分)。
(4)写出求解问题的算法步骤(可以选择自然语言、伪码、流程图、程序设计语言中的任何一种形式描述)(5分)。
(5)分析算法的时间复杂度和空间复杂度(2分)。
思路:本题的思路和矩阵链相乘思路一样,但递推方程不一样 1:首先判断是否用动态规划:从1到最后的站N,那么这个求解的过程是跳跃性的
可以从1到2 然后从2到 N,或则从1到3,从3到N,其是跳跃性的,判断其是动态规划2:回归本题我们在考虑的时候,其中涉及到划分问题,比如从2到N,可以从2到3,然后从 3到N,那么的我们可以找类似的思路,那就是矩阵连相乘
3: 总结出递归方程:m[i][j] = m[i][k]+m[k][j] 这里和矩阵链相乘有区别
(1)动态规划算法
(2)基本思想是将原问题分解成若干个子问题。其分解出的子问题往往不是相互独立的。动态规划法在求解过程中把所有已解决的子问题的答案保存起来,从而避免对子问题重复求解。
动态规划常用于解决最优化问题。对一个最优化问题可否应用动态规划法,取决于该问题是否具有如下两个性质:
最优子结构性质:当问题的最优解包含其子问题的最优解时,称该问题具有最优子结构性质。
子问题重叠性质:子问题重叠性质是指由原问题分解出的子问题不是相互独立的,存在重叠现象。
(3)所用数据结构 r[i][j] 用来记录从出租站i到出租站j的最少租金
(4)
核心代码:
for(int l=2;l<=n;l++){
//出租站的长度
for(int i=1;i<=n-l+1;i++){
int j=i+l-1;
for(int k=i+1;k<j;k++){
int temp=r[i][k]+r[k][j];
if(temp<r[i][j])
r[i][j]=temp;
}
}
}
一辆汽车加满油后可行驶n公里。旅途中有若干个加油站。设计一个有效算法,指出应在哪些加油站停靠加油,使沿途加油次数最少。阅读程序1,回答问题。
6、汽车加油问题:
代码的输入和输出分别是:
输入:汽车加满油后可行驶n公里,且旅途中有 k个加油站
输出:输出最少加油次数。如果无法到达目的地,则输出“no way”
代码选用的数据结构是:数组
代码选用的算法设计策略是:贪心算法
阅读算法1,回答问题。
算法1 :
int BinarySearch(int s[],int x,int low,int high){
if(low>high) //递归结束条件
return -1;
int middle=(low+high)/2; //计算middle值(查找范围的中间值)
if(x==s[middle]) //x等于s[middle],查找成功
return middle;
else if(x<s[middle]) //x小于s[middle],则在前半部分查找
return BinarySearch(s,x,low,middle-1);
else //x大于s[middle],则在后半部分查找
return BinarySearch(s,x,middle+1,high);
}
(1)算法1的功能是什么?(3分)
(2)请你设计至少4组输入,验证算法1的正确性。(4分)
(3)请改用自然语言描述算法1。(3分)
算法功能:通过二分法实现查找
测试三组数据:
第一组:3 5 12 50 66 78 99
第二组:2 8 12 35 64 100 785
第三组:3 12 45 46 48 89 101
第四组:12 35 48 49 50 77 110
描述算法:二分查找有两个要求,一个是数列有序,另一个是数列使用顺序存储结构(数组)。每次比较的数列长度都会是之前数列的一半,直到找到相等元素的位置或者最终没有找到要找的元素。
- (13分)阿里巴巴走进了装满宝藏的藏宝洞。藏宝洞里面有N堆金币,第i堆金币的总重量和总价值分别是m,v。阿里巴巴有一个承重量为T的背包,但并不一定有办法将全部的金币都装进去。他想装走尽可能多价值的金币。所有金币都可以随意分割,分割完的金币重量价值比(也就是单位价格)不变。请问阿里巴巴最多可以拿走多少价值的金币?
(1)请给出存储已知数据的数据结构(2分)
(2)请给出你选择的算法策略(2分)
(3)请写出算法步骤(任选一种自然语言、伪代码、程序进行描述)(6分)
(4)假设背包里有4个物品,请自行设计一个算法,并给出输出结果(物品的重量、价值、背包容量自拟)(3分)
(1)存储已知数据的数据结构:结构体数组
(2)选择的算法策略:贪心
(3)代码程序:
struct node
{
double m, v; // m 为金币的重量,v 为金币的价值
} f[1005];
bool cmp(node a, node b)
{
return a.v / a.m > b.v / b.m; //计算单位价格
}
int main()
{
int n, t;
double sum = 0;
cin >> n >> t;
for (int i = 0; i < n; i++)
{
cin >> f[i].m >> f[i].v;
}
sort(f, f + n, cmp); // 排序
for (int i = 0; i < n; i++)
{
if (t > f[i].m)
{
sum += f[i].v;
t -= f[i].m;
}
else
{
sum += (f[i].v / f[i].m) * t;
break;
}
}
printf("%.2lf\n", sum);
return 0;
(4)假设背包里有4个物品,请自行设计一个算法,并给出输出结果(物品的重量、价值、背包容量自拟)
输入:4 25
10 100
8 150
5 200
5 170
输出:590.00
第二章贪心算法
基本思路:在问题求解时总是做出在当前看来最优的选择,也就是局部最优解。
贪心法求解问题的特征:
1、贪心选择性质:所求问题的整体最优解可以通过一系列局部最优解的选择来达到。
2、最优子结构性质
一个问题的最优解包含其子问题的最优解,则称该问题具有最优子结构。
eg:会议安排问题
问题描述
设有n个活动的集合E={1, 2, …, n},其中每个活动都要求使用同一资源,而在同一时间内只有一个活动能使用这一资源。每个活动i都有一个要求使用该资源的起始时间si和一个结束时间fi,且si <fi 。如果选择了活动i,则它在半开时间区间[si, fi)内占用资源。若区间[si, fi)与区间[sj, fj)不相交,则称活动i与活动j是相容的。也就是说,当si≥fj或sj≥fi时,活动i与活动j相容。活动安排问题要求在所给的活动集合中选出最大的相容活动子集。
2.算法设计:
(1)初始化:按结束时间非递减排序,若结束时间相等,则按开始时间非递增排序。
(2)选中第一个具有最早结束时间的会议,用last记录时间。
(3)挑剩下的,若i的开始时间>last,则与会议i与已挑会议相容。
3.算法描述:
贪心法求解活动安排问题的关键是如何选择贪心策略,使得按照一定的顺序选择相容活动,并能安排尽量多的活动。
至少有两种看似合理的贪心策略:
⑴最早开始时间:可以增大资源的利用率。
⑵持续时间最短:可以尽可能多地安排会议。
(3)最早结束时间:可以使下一个活动尽早开始。
策略1中安排最早开始时间,若会议时间长,那么总会议次数必定减少;策略2中安排持续时间最短的,若会议安排时间较晚,则其他会议必定被耽误;那么我们可以选择安排开会较早且会议持续时间较短的会议,即结束时间较早。
所以我们选择策略3:每次从剩下未安排的会议中选择会议具有安排 具有最早结束时间且与已安排的会议相容 的会议安排,以尽快安排下一场会议。
4、伪代码详解:
(1)数据结构定义
struct Meet{
int beg; //会议开始的时间
int end;//会议结束的时间
}meet[1000];
(2)对会议按照结束时间非递减排序,结束时间相等时,按开始时间从大到小排序
bool cmp(Meet x,Meet y){
if(x.end == y.end)
return x.beg>y.begin;
return x.end<y.end
}
(3)会议安排问题的贪心算法求解
在第(2)步的基础上,定义变量last=0,ans=1。ans为会议安排的最大数量,选中第一个会议,用变量last记录被选中会议的结束时间,与下一个会议的开始时间进行比较,如last小于下一个会议的开始时间则选中下一个会议,更新last为最后被选中会议的结束时间,ans++,若last大于下一个会议的开始时间则继续考查下下一个会议,知道所有的会议考查完毕。
int ans=1,last=meet[0].end;
for(int i = 1;i < n;i++){
if(meet[i].beg > last){
last = meet[i].end;
ans++;
}
}
return ans;
5、算法的时间复杂度: sort排序函数的平均时间复杂度为O(nlogn)。 选择会议,需要n时间。
总的时间复杂度为O(n+nlogn)=O(nlogn)
哈夫曼树
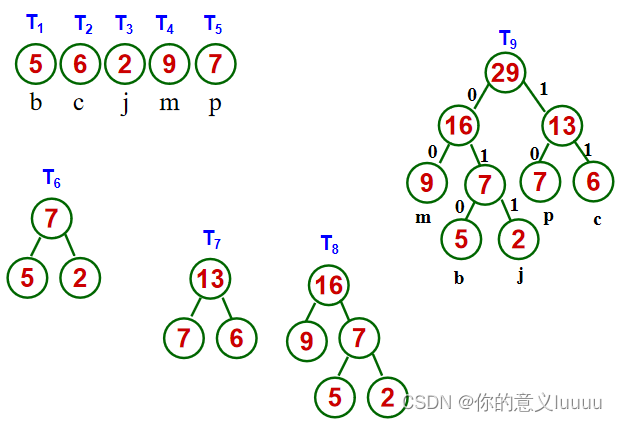
在构造哈夫曼树的过程中,首先给每个结点的双亲、做孩子、右孩子初始化为-1,找出所有节点中双亲为-1,权值最小的两个节点t1,t2合并为一颗二叉树,更新信息(双亲节点的权值为t1,t2权值之和,做孩子为权值最小的结点t1,右孩子为次小的结点t2,t1,t2的双亲为双亲节点的编号),重复此过程,构造一棵哈夫曼树。
(1)数据结构
typedef struct{
double weight;
char value;
int parent;
int lchild;
int rchild;
}HNodeType;
编码数组HcodeType
typedef HcodeType{
int bit[MAXBIT];//存储编码的数组
int start;//编码开始的下标
}HCodeType;

(2)初始化
初始化存放哈夫曼树数组的HuffNode[]中的结点
for(int i = 0;i < 2*n-1;i++){
HuffNode[i].parent=-1;
HuffNode[i].lchild=-1;
HuffNode[i].rchild = -1;
HuffNode[i].weight=0;
}
输入n个叶子结点的权值和字符
for(int i = 0;i<n;i++){
cin >> HuffNode[i].weight >> HuffNode[i].value;
}
(3)找出所有节点中双亲为-1,权值最小的两个节点t1,t2合并为一颗二叉树,更新信息(双亲节点的权值为t1,t2权值之和,做孩子为权值最小的结点t1,右孩子为次小的结点t2,t1,t2的双亲为双亲节点的编号),重复此过程,构造一棵哈夫曼树。
int x1,x2;
double m1,m2;
for(int i = 0;i<n-1;i++){
m1=m2=MAXVALUE;
X1=X2=-1;
for(j = 0;j<n+1;j++){
if(HuffNode[j].weight < m1 &&HuffNode[j].parent=-1){
m2=m1;
x2=x1;
m1=HuffNode[j].weight;
x1=j;
}
else if(HuffNode[j].weight < m2 &&HuffNode[j].parent=-1){
m2=HuffNode[j].weight;
x2=j;
}
}
HuffNode[x1].parent=n+i;
HuffNode[x2].parent=n+i;
HuffNode[n+i].weight=m1+m2;
HuffNode[n+i].lchild=x1;
HuffNode[n+i].rchild=x2;
}
时间复杂度 外层i和内层j构成双重for循环 O(n的平方)
空间复杂度:所需存储空间为结点结构体数组和编码结构体数组,则该算法空间复杂度为O(N*MAXBIT) 算法优化:
构造哈夫曼树时找两个权值最小结点时使用优先队列,时间复杂度为logn,执行n-1次,总时间复杂度为O(nlogn)
哈夫曼树组HuffNode可以顶一个动态分配空间的线性表来存储编码,每个线性表的长度为实际的编码长度,大大节省空间。
最小生成树问题
问题分析:找出能够连接n个城市交通图的道路修建党发,且所需费用最小,这就需要找到带权的最小生成树。
算法分析:一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边。最小生成树可以用kruskal(克鲁斯卡尔)算法或prim(普里姆)算法求出求解最小生成树。两个算法均属于贪心算法。
算法特征分析:
Prim算法特点: 将顶点归并,与边数无关,适于稠密网。
满足贪心选择特征:每次选择U和V-U之间最短的边。
满足最优子结构特征:每次所选的边为最小生成树上的边。
Kruskal算法特点:将边归并,适于求稀疏网的最小生成树。
满足贪心选择特征:每次不产生回路的最短边。
满足最优子结构特征:每次所选的边为最小生成树上的边。
选择Prim算法进行实验,算法选择理由如下:
1为了避免浪费大量的时间输入大量的数据,实验数据采用随机法生成;
2为了保证生成的随机图是连通的,采用生成完全图的方法,避免连通图判断的繁琐细节;
3完全图属于稠密图,所以选择prim算法比较高效。
五、算法设计及编码实现
Prim算法步骤和实现原理
(1)初始状态:U ={u0 },( u0∈V), TE={ },uo可以是任何一个结点,因为最小生成树包含所有结点,所以从那个节点出发都可以得到最小生成树,不影响最终结果,TE为选中的边集。
(2)做贪心选择:选取连接U和V-U的所有边的最短边。
从E中选择顶点分别属于U、V-U两个集合、且权值最小的边( u0, v0),将顶点v0归并到集合U中,边(u0, v0)归并到TE中;
(3)直到U=V为止。此时TE中必有n-1条边,T=(V,{TE})就是最小生成树。
伪代码:
(1)初始化。s[1]=true 初始化数组closet,除了















 5390
5390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









