






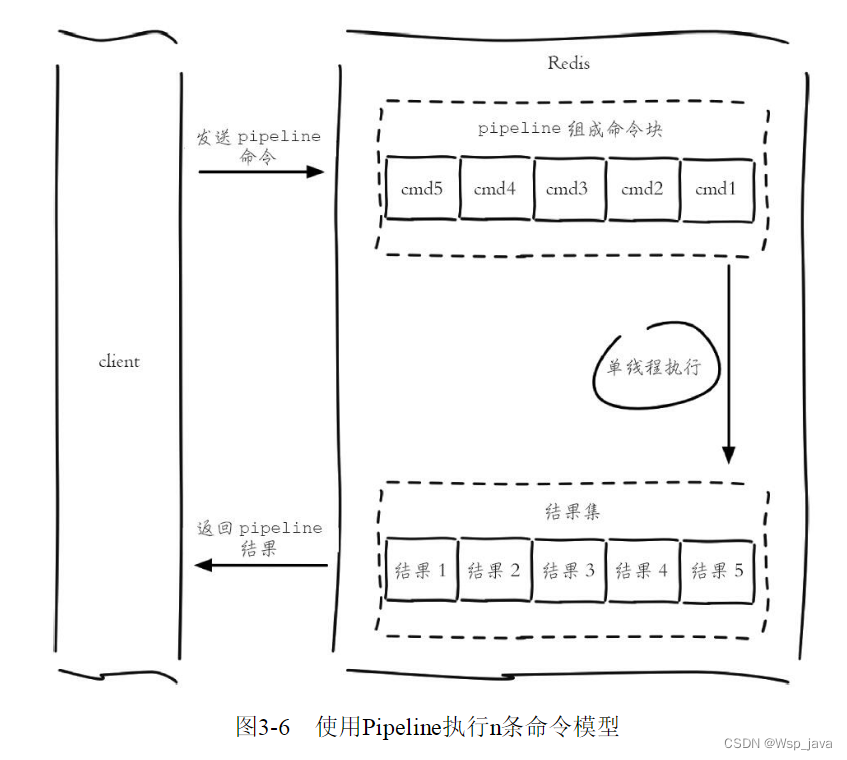
pipeline
该部分内容大都引用自《Redis开发与运维》付磊,张益军
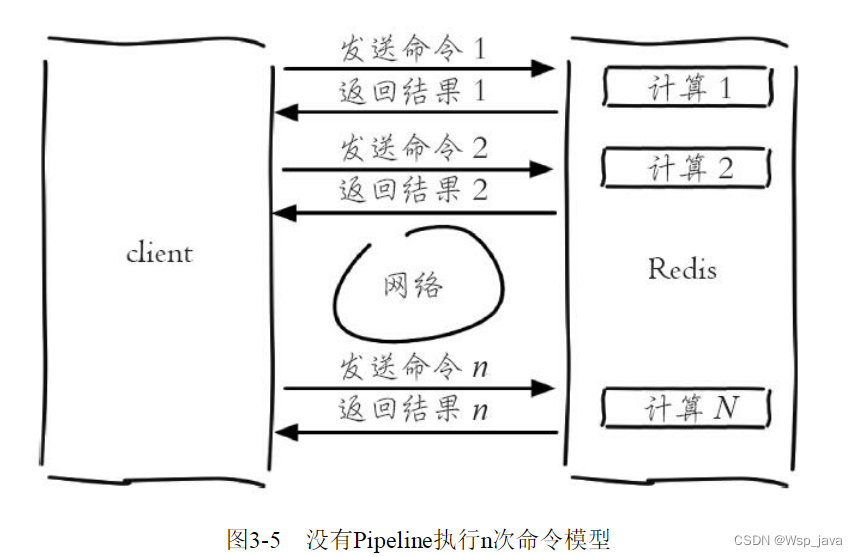
Redis客户端执行一条命令分为如下四个过程:
1)发送命令
2)命令排队
3)命令执行
4)返回结果
第1步和第4步称为Round Trip Time(RTT,往返时间)。
距离越远网络耗时越长
Redis服务端在上海,两地直线距离约为1300公里,那么1次RTT时间=1300×2/(300000×2/3)=13毫秒(光在真空中传输速度为每秒30万公里,这里假设光纤为光速的2/3),那么客户端在1秒内大约只能执行80次左右的命令,这个和Redis的高并发高吞吐特性背道而驰。
结论:同机房和同机器会比较快,跨机房跨地区会比较慢。
pipeline与非pipeline的命令模式图示:
《Redis开发与运维》性能压测
仅能作为参考,说明pipeline对性能的提升

pipeline与原生批量命令的区别
可以使用Pipeline模拟出批量操作的效果,但是在使用时要注意它与原生批量命令的区别,具体包含以下几点:
·原生批量命令是原子的,Pipeline是非原子的。
·原生批量命令是一个命令对应多个key,Pipeline支持多个命令。
·原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户端的共同实现。
最佳实践
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成。Pipeline只能操作一个Redis实例,但是即使在分布式Redis场景中,也可以作为批量操作的重要优化手段。
Jedis中Pipeline的使用
sync()没有返回值
syncAndReturnAll存在返回值
package redis;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import java.util.List;
public class UseJedisPipeline {
@Test
public void pipelineUsageWithoutResult() {
Jedis jedis = null;
try {
jedis = new Jedis("192.168.42.111", 6379);
if (!"PONG".equals(jedis.ping())) {
throw new RuntimeException("连接失败");
}
Pipeline pipeline = jedis.pipelined();
for (int i = 0; i < 100; i++){
pipeline.set("n" + i, String.valueOf(i));
}
pipeline.sync();
} finally {
if (jedis != null) {
jedis.close();
}
}
}
@Test
public void pipelineUsageWithResult() {
Jedis jedis = null;
try {
jedis = new Jedis("192.168.42.111", 6379);
if (!"PONG".equals(jedis.ping())) {
throw new RuntimeException("连接失败");
}
Pipeline pipeline = jedis.pipelined();
for (int i = 0; i < 100; i++){
pipeline.set("n" + i, String.valueOf(i));
}
for (int i = 0; i < 100; i++){
pipeline.get("n" + i);
}
List<Object> results = pipeline.syncAndReturnAll();
for(Object result:results){
System.out.println(result);
}
} finally {
if (jedis != null) {
jedis.close();
}
}
}
}














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









