







 本文介绍了二叉树的基本概念,包括其定义、不同类型以及深度优先搜索(DFS)和广度优先搜索(BFS)的遍历方式。还详细讲解了如何通过中序遍历、后序遍历或先序遍历构建二叉树的过程。
本文介绍了二叉树的基本概念,包括其定义、不同类型以及深度优先搜索(DFS)和广度优先搜索(BFS)的遍历方式。还详细讲解了如何通过中序遍历、后序遍历或先序遍历构建二叉树的过程。
一、概念
在了解二叉树前首先要知道树的概念。
1、树
首先树属于非线性结构,其结构类似与族谱,即一个元素有多个孩子(子节点),但是只能有一个父亲(结点),但始祖是没有父亲的(根节点没有前驱)。
由此我们得到树的定义:
1、有且只有一个成为根的节点
2、其余节点分为m个互不相交的有限集合,每个集合又构成一颗树
具体如图:
2、二叉树
二叉树是一种特殊的树,其每个节点最多有两个子树,一般称之为左子树和右子树。
根据其子树的分布不同又可分为几类二叉树:
空树:无节点
满二叉树:每个节点都有两棵子树(除最后一层外)
完全二叉树:除最后一层外,每个节点都填满了
平衡二叉树:每个节点的左右两个子树的高度差的绝对值不超过 1
单分枝树:所有节点都没有右孩子或者左孩子
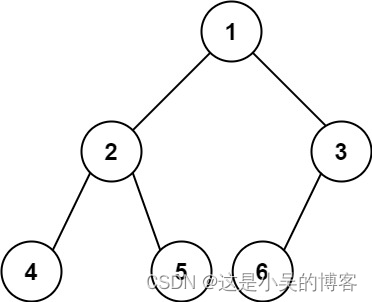
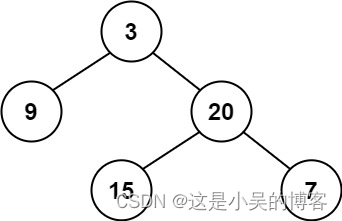
二、二叉树的遍历方式
1、深度优先搜索(DFS)
自上而下或者自下而上的遍历二叉树
常见的有三种遍历顺序:先序遍历:根、左、右,中序遍历:左、根、右,后序遍历:左、右、根。
实现方法:迭代(使用栈存储)和递归。
实现代码(以先序遍历为例子):
//递归
public List<Integer> preorderTraversal1(TreeNode root) {
List<Integer> pre = new ArrayList<Integer>();
dfs(root,pre);
return pre;
}
public void dfs(TreeNode root,List<Integer> pre){
if(root == null) return;
pre.add(root.val);//根
preorder(root.left,pre);//左
preorder(root.right,pre);//右
}
// 栈实现二叉树的前序遍历
public List<Integer> preorderTraversal2(TreeNode root) {
List<Integer> res = new ArrayList<>();
if(root == null) return res;
//因为栈是后进先出的,使用入栈顺序为:根右左
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while(!stack.isEmpty()){
TreeNode node = stack.pop();
res.add(node.val);
if(node.right != null){
stack.push(node.right);
}
if(node.left != null) {
stack.push(node.left);
}
}
return res;
}实战
2、广度优先搜索(BFS)
自上而下,从左往右层级遍历,借助队列存储每层的元素值。
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<List<Integer>>();
if(root == null) return res;
Queue<TreeNode> queue = new ArrayDeque<>();
queue.add(root);
while(!queue.isEmpty()){
int n = queue.size();
List<Integer> pre = new ArrayList<>();
for(int i = 0; i < n; i++){
TreeNode node = queue.poll();
pre.add(node.val);
if(node.left != null) queue.add(node.left);
if(node.right != null) queue.add(node.right);
}
res.add(pre);
}
return res;
}三、构造二叉树
1、已知中序遍历顺序和后序遍历顺序
思路:首先我们从根节点来看两种排序后的二叉树组成结构
中序遍历:左子树 根节点 右子树
后序遍历:左子树 右子树 根节点
而后左右子树又可继续细分为相同的结构,在此我们使用递归完成这个重复操作
在递归前我们首先要找出根节点在中序遍历中的位置,而后分割左右子树,定义左右子树边界条件,在后序遍历中同理定义分割左右子树的边界。
请看手绘图:
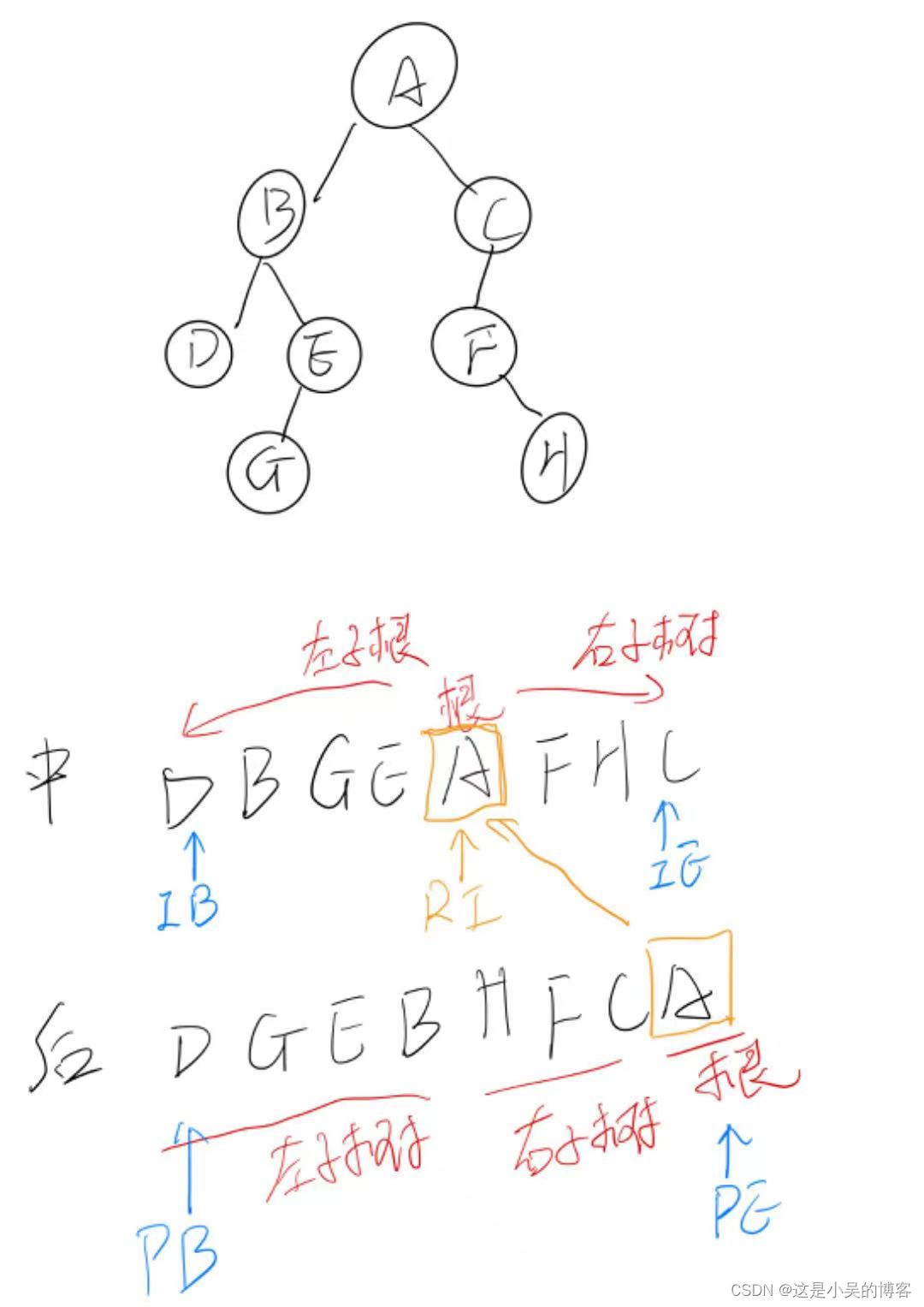
//中:左根右,后:左右根
Map<Integer,Integer> map;
public TreeNode buildTree(int[] inorder, int[] postorder) {
map = new HashMap<>();
for(int i = 0; i < inorder.length; i++){
map.put(inorder[i],i);
}
return findNode(inorder, 0, inorder.length, postorder, 0, postorder.length);
}
public TreeNode findNode(int[] inorder, int inBegin, int inEnd, int[] postorder, int postBegin, int postEnd){
//以根节点为中心,左边为左子树,右边为右子树
//两边越过中心,不存在子树
if(inBegin >= inEnd || postBegin >= postEnd) return null;
//在post order中取根节点,在inorder中标记,中序遍历分割点
int rootIndex = map.get(postorder[postEnd - 1]);
//构建新节点
TreeNode root = new TreeNode(inorder[rootIndex]);
//后续遍历分割点
int lenOfLeft = rootIndex - inBegin;
//左子树
root.left = findNode(inorder, inBegin, rootIndex, postorder, postBegin, postBegin + lenOfLeft);
//右子树
root.right = findNode(inorder, rootIndex + 1, inEnd, postorder,postBegin + lenOfLeft, postEnd - 1);
//最后返回结果
return root;
}2、已知先序遍历顺序和中序遍历顺序
请模仿上一个例子。
Map<Integer,Integer> map;
public TreeNode buildTree(int[] preorder, int[] inorder) {
map = new HashMap<>();
for(int i = 0; i < inorder.length; i++) map.put(inorder[i],i);
return findTree(preorder, 0, preorder.length, inorder, 0, inorder.length);
}
public TreeNode findTree(int[] preorder, int preBegin, int preEnd, int[] inorder, int inBegin, int inEnd){
if(preBegin >= preEnd || inBegin >= inEnd) return null;
int rootIndext = map.get(preorder[preBegin]);
TreeNode root = new TreeNode(inorder[rootIndext]);
int leftIndext = rootIndext - inBegin;
//左子树
root.left = findTree(preorder, preBegin + 1, preBegin + leftIndext + 1, inorder, inBegin, rootIndext);
//右子树
root.right = findTree(preorder, preBegin + leftIndext + 1, preEnd, inorder, rootIndext + 1, inEnd);
return root;
}提问:为什么前序遍历和后序遍历不能确定唯一二叉树?
解答:有单分支树















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









