






1.背景介绍
在本篇文章中,我们将探讨NLP在安全领域的应用,特别关注网络安全与舆情监控。首先,我们将从背景介绍中了解NLP在安全领域的重要性,然后深入探讨核心概念与联系,接着详细讲解核心算法原理和具体操作步骤,并通过代码实例和详细解释说明,展示具体最佳实践。最后,我们将讨论实际应用场景、工具和资源推荐,并总结未来发展趋势与挑战。
1. 背景介绍
NLP(自然语言处理)是一门研究如何让计算机理解和生成人类自然语言的学科。在安全领域,NLP具有重要的应用价值,可以帮助我们更有效地处理和分析大量的安全相关信息。
网络安全与舆情监控是NLP在安全领域的两个重要应用领域。网络安全中,NLP可以用于检测网络攻击、识别恶意软件、分析网络流量等;舆情监控中,NLP可以用于实时分析社交媒体、新闻报道、论坛讨论等,以了解公众对某个话题的情感和态度。
2. 核心概念与联系
在网络安全领域,NLP的核心概念包括:
- 文本分类:根据文本内容将其分为不同类别,如正常流量、恶意流量等。
- 实体识别:从文本中提取有关实体(如IP地址、域名、用户名等)的信息。
- 关键词提取:从文本中提取与特定话题相关的关键词。
- 情感分析:根据文本内容判断作者的情感倾向。
在舆情监控领域,NLP的核心概念包括:
- 话题挖掘:从大量文本中自动发现相关话题。
- 情感分析:判断公众对某个话题的情感倾向。
- 关键词提取:提取与话题相关的关键词。
- 趋势分析:分析话题的发展趋势。
NLP在网络安全与舆情监控中的联系是,它可以帮助我们更有效地处理和分析大量的安全相关信息,从而提高安全工作的效率和准确性。
3. 核心算法原理和具体操作步骤
3.1 文本分类
文本分类是一种监督学习任务,需要训练一个分类器来将文本划分为不同的类别。常见的文本分类算法有:
- 朴素贝叶斯分类器
- 支持向量机
- 随机森林
- 深度学习(如卷积神经网络、循环神经网络等)
具体操作步骤如下:
- 数据预处理:对文本进行清洗、去除停用词、词汇化、词性标注等处理。
- 特征提取:将文本转换为向量,常用的方法有TF-IDF、Word2Vec、BERT等。
- 模型训练:使用训练集数据训练分类器。
- 模型评估:使用测试集数据评估分类器的性能。
- 模型优化:根据评估结果调整模型参数或选择不同的算法。
3.2 实体识别
实体识别是一种信息抽取任务,旨在从文本中识别和提取有关实体的信息。常见的实体识别算法有:
- 规则引擎
- 条件随机场
- 深度学习(如BiLSTM、CRF等)
具体操作步骤如下:
- 数据预处理:对文本进行清洗、去除停用词、词汇化、词性标注等处理。
- 特征提取:将文本转换为向量,常用的方法有TF-IDF、Word2Vec、BERT等。
- 模型训练:使用训练集数据训练实体识别模型。
- 模型评估:使用测试集数据评估模型的性能。
- 模型优化:根据评估结果调整模型参数或选择不同的算法。
3.3 关键词提取
关键词提取是一种信息抽取任务,旨在从文本中提取与特定话题相关的关键词。常见的关键词提取算法有:
- TF-IDF
- TextRank
- BERT
具体操作步骤如下:
- 数据预处理:对文本进行清洗、去除停用词、词汇化等处理。
- 特征提取:将文本转换为向量,常用的方法有TF-IDF、Word2Vec、BERT等。
- 关键词提取:根据特征向量计算关键词的相关性,选择最相关的关键词。
3.4 情感分析
情感分析是一种自然语言处理任务,旨在根据文本内容判断作者的情感倾向。常见的情感分析算法有:
- 支持向量机
- 随机森林
- 深度学习(如LSTM、GRU、BERT等)
具体操作步骤如下:
- 数据预处理:对文本进行清洗、去除停用词、词汇化等处理。
- 特征提取:将文本转换为向量,常用的方法有TF-IDF、Word2Vec、BERT等。
- 模型训练:使用训练集数据训练情感分析模型。
- 模型评估:使用测试集数据评估模型的性能。
- 模型优化:根据评估结果调整模型参数或选择不同的算法。
4. 具体最佳实践:代码实例和详细解释说明
4.1 文本分类
python
复制代码
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 数据集
texts = ["正常流量", "恶意流量", "正常流量", "网络攻击"]
labels = [0, 1, 0, 1]
# 数据预处理
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
# 训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 模型训练
clf = SVC()
clf.fit(X_train, y_train)
# 模型评估
y_pred = clf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
4.2 实体识别
python
复制代码
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 数据集
texts = ["IP地址", "域名", "用户名", "正常文本"]
labels = [1, 1, 1, 0]
# 数据预处理
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
# 训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 模型训练
clf = LogisticRegression()
clf.fit(X_train, y_train)
# 模型评估
y_pred = clf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
4.3 关键词提取
python
复制代码
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_selection import SelectKBest, chi2
# 数据集
texts = ["网络安全是我们的重要任务", "我们应该关注网络安全问题"]
# 数据预处理
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
# 关键词提取
selector = SelectKBest(chi2, k=2)
X_new = selector.fit_transform(X, texts)
print(vectorizer.get_feature_names_out())
print(X_new.toarray())
4.4 情感分析
python
复制代码
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 数据集
texts = ["我很满意", "我很不满意", "我觉得很好", "我觉得很糟"]
labels = [1, 0, 1, 0]
# 数据预处理
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
# 训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 模型训练
clf = LogisticRegression()
clf.fit(X_train, y_train)
# 模型评估
y_pred = clf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
5. 实际应用场景
5.1 网络安全
- 识别网络攻击:通过文本分类算法,识别网络流量中的恶意流量,提高网络安全的防御能力。
- 识别恶意软件:通过实体识别算法,从软件描述、评论等文本中识别恶意软件的关键词,提高恶意软件的检测率。
- 分析网络流量:通过关键词提取算法,从网络流量中提取关键词,帮助安全人员快速定位问题。
5.2 舆情监控
- 话题挖掘:通过文本分类算法,从社交媒体、新闻报道、论坛讨论等文本中挖掘热门话题,了解公众关注的方向。
- 情感分析:通过情感分析算法,分析公众对某个话题的情感倾向,了解人们的心理状态和需求。
- 关键词提取:通过关键词提取算法,从舆情数据中提取关键词,帮助政府、企业等了解舆情的发展趋势。
6. 工具和资源推荐
6.1 工具
- NLTK:一个Python自然语言处理库,提供了大量的文本处理和分析功能。
- spaCy:一个高性能的自然语言处理库,提供了实体识别、关键词提取等功能。
- Gensim:一个Python自然语言处理库,提供了主题建模、词嵌入等功能。
6.2 资源
- 《自然语言处理入门》:这本书是自然语言处理领域的经典教材,对于初学者来说非常有帮助。
- 《深度学习与自然语言处理》:这本书介绍了深度学习在自然语言处理中的应用,对于深度学习爱好者来说非常有趣。
- 《舆情监测与分析》:这本书介绍了舆情监测和分析的理论和实践,对于舆情分析工作者来说非常有价值。
7. 总结:未来发展趋势与挑战
NLP在安全领域的应用已经取得了一定的成功,但仍然存在许多挑战。未来,我们需要继续研究和开发更高效、更准确的算法,以应对网络安全和舆情监控等领域的复杂需求。同时,我们还需要关注数据隐私和道德伦理等问题,确保NLP在安全领域的应用不会带来不良影响。
8. 附录:代码示例
8.1 文本分类
python
复制代码
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 数据集
texts = ["正常流量", "恶意流量", "正常流量", "网络攻击"]
labels = [0, 1, 0, 1]
# 数据预处理
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
# 训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 模型训练
clf = SVC()
clf.fit(X_train, y_train)
# 模型评估
y_pred = clf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
8.2 实体识别
python
复制代码
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 数据集
texts = ["IP地址", "域名", "用户名", "正常文本"]
labels = [1, 1, 1, 0]
# 数据预处理
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
# 训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 模型训练
clf = LogisticRegression()
clf.fit(X_train, y_train)
# 模型评估
y_pred = clf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
8.3 关键词提取
python
复制代码
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_selection import SelectKBest, chi2
# 数据集
texts = ["网络安全是我们的重要任务", "我们应该关注网络安全问题"]
# 数据预处理
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
# 关键词提取
selector = SelectKBest(chi2, k=2)
X_new = selector.fit_transform(X, texts)
print(vectorizer.get_feature_names_out())
print(X_new.toarray())
8.4 情感分析
python
复制代码
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 数据集
texts = ["我很满意", "我很不满意", "我觉得很好", "我觉得很糟"]
labels = [1, 0, 1, 0]
# 数据预处理
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
# 训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 模型训练
clf = LogisticRegression()
clf.fit(X_train, y_train)
# 模型评估
y_pred = clf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
最后
为了帮助大家更好的学习网络安全,小编给大家准备了一份网络安全入门/进阶学习资料,里面的内容都是适合零基础小白的笔记和资料,不懂编程也能听懂、看懂,所有资料共282G,朋友们如果有需要全套网络安全入门+进阶学习资源包,可以点击免费领取(如遇扫码问题,可以在评论区留言领取哦)~
😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓

1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
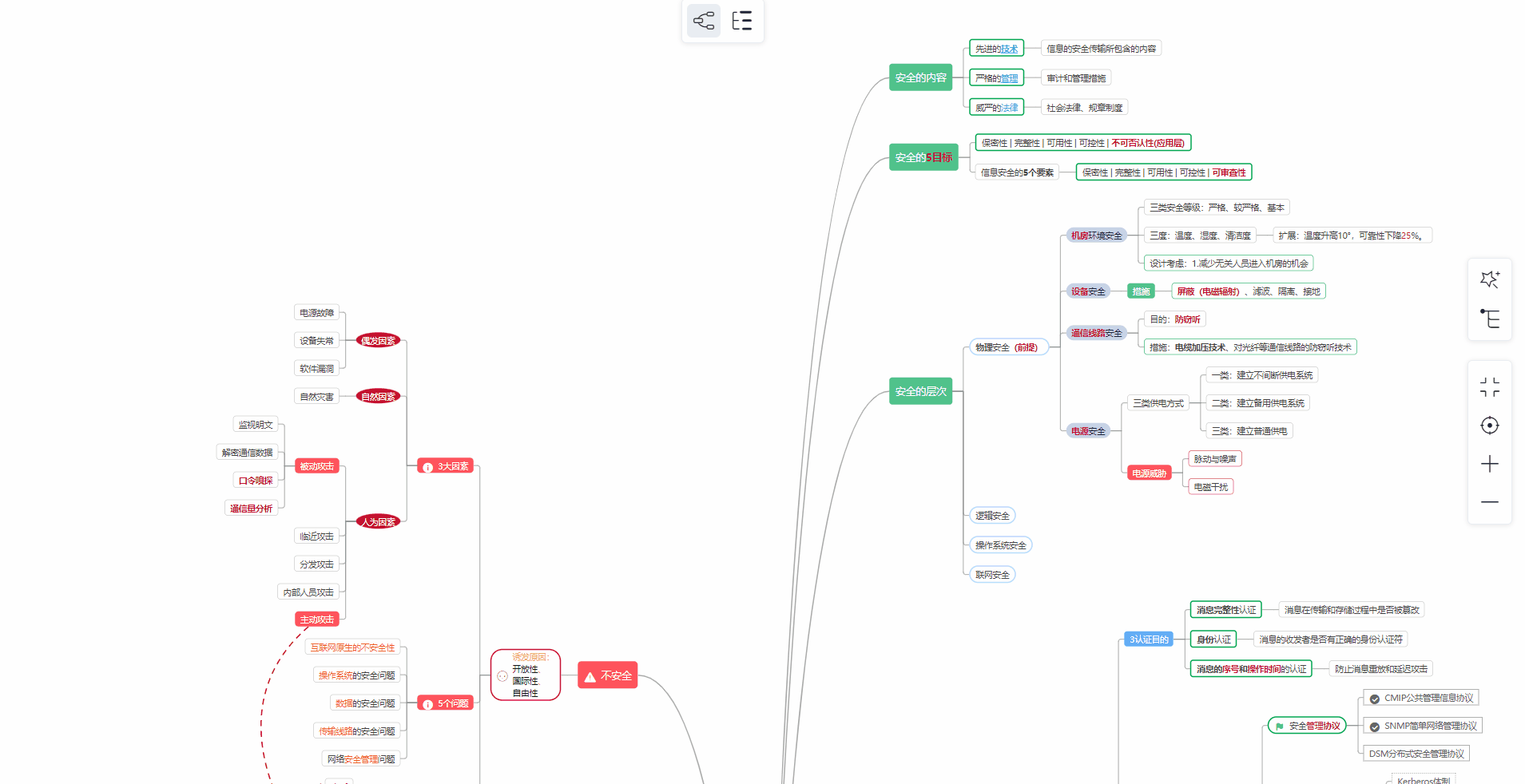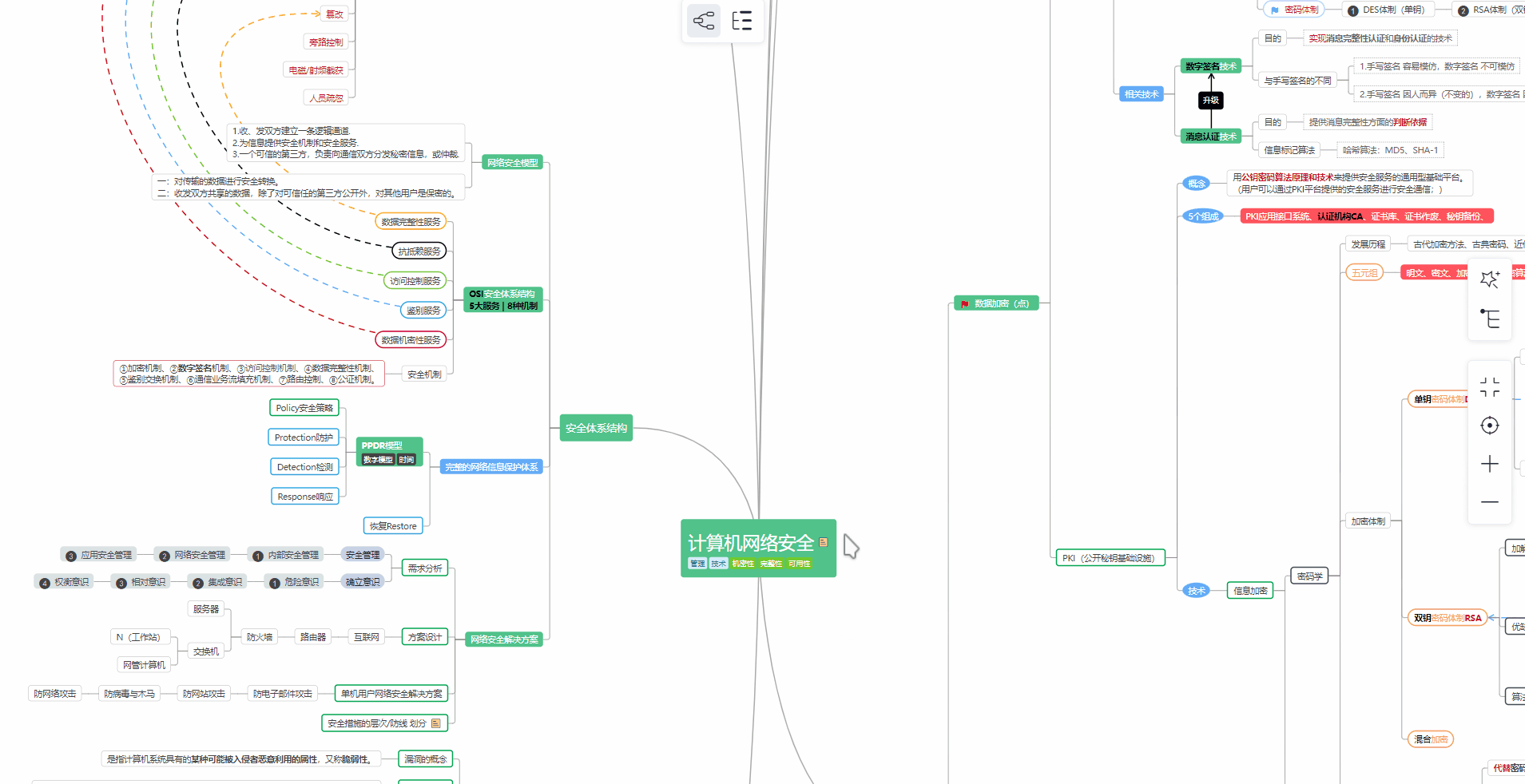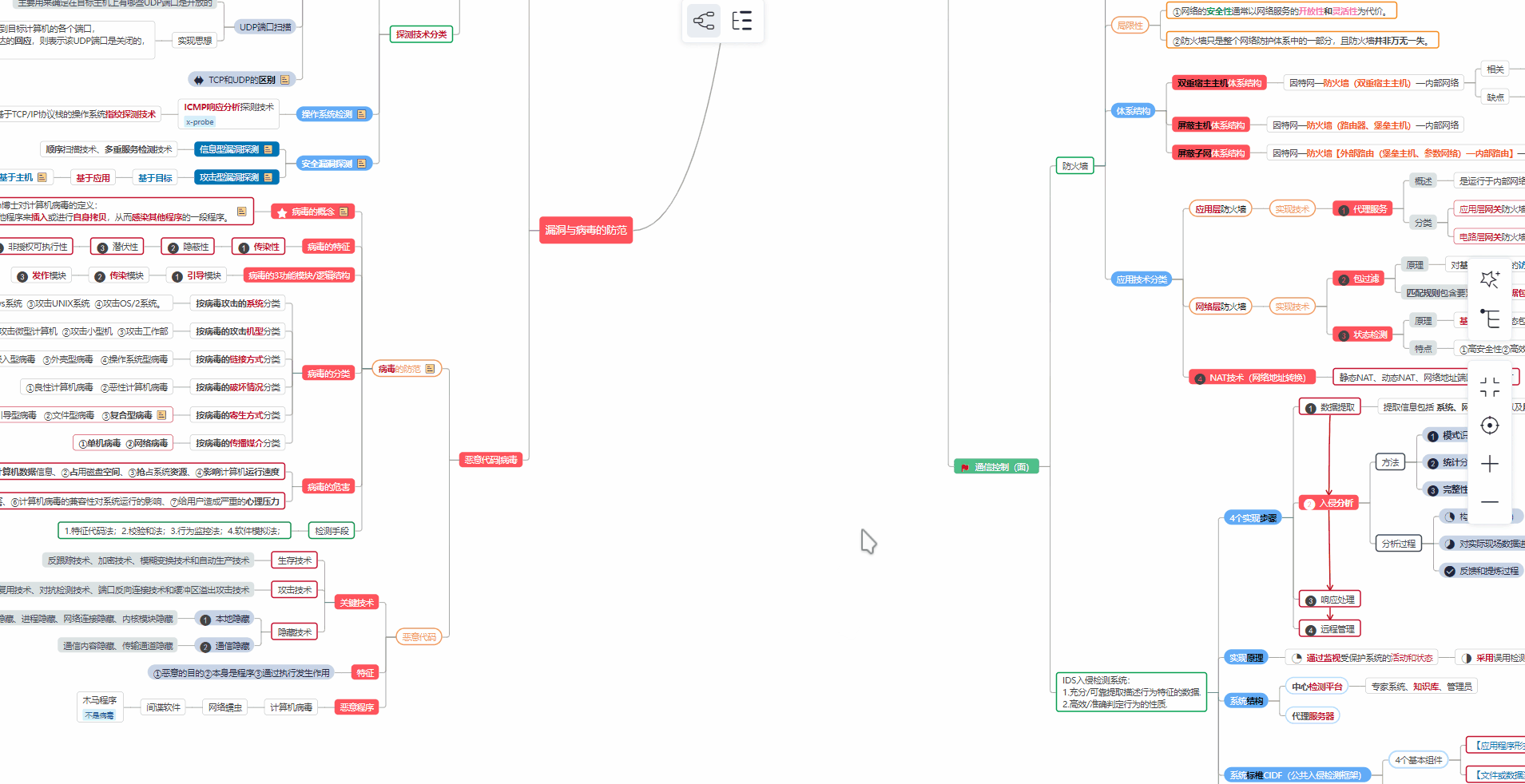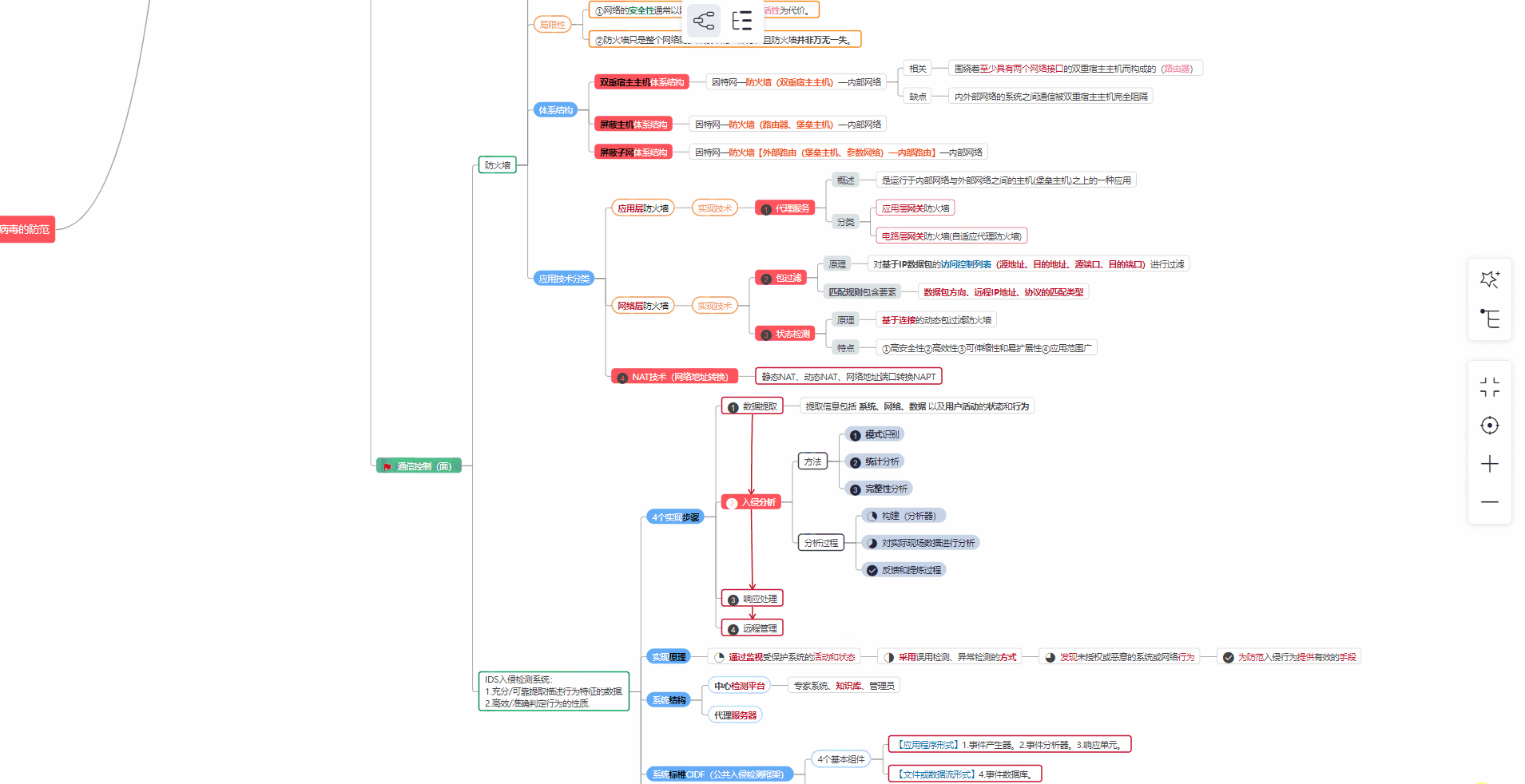
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:
因篇幅有限,仅展示部分资料
2️⃣视频配套资料&国内外网安书籍、文档
① 文档和书籍资料
② 黑客技术

因篇幅有限,仅展示部分资料
3️⃣网络安全源码合集+工具包
4️⃣网络安全面试题

5️⃣汇总
所有资料 ⚡️ ,朋友们如果有需要全套 《网络安全入门+进阶学习资源包》,扫码获取~















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









