







- 参考书籍《MySql从入门到精通》
- 学习视频【韩顺平讲MySQL】零基础一周学会MySQL -sql mysql教程 mysql视频 mysql入门_哔哩哔哩_bilibili
- 萌新入门,如有错误恳请各位大佬指点,不甚感激
目录
自增长
在某张表中,存在一个id列(整数) ,我们希望在添加记录的时候,该列从1开始,自动的增长。

先创建一个t34表
CREATE TABLE t34(
id INT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(32) NOT NULL DEFAULT ' ',
`name` VARCHAR(32) NOT NULL DEFAULT ' ');
添加数据:
INSERT INTO t34
VALUES(NULL,'tom.com','tom');
INSERT INTO t34
(email,`name`) VALUES('hsp.com','hsp');
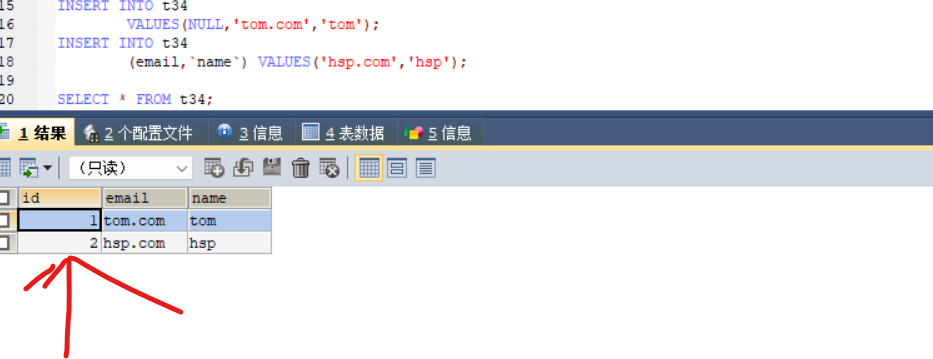
这里第二行的id->2是自动加的(自增长)
使用细节:
- 一般来说自增长是和primary key 配合使用的
- 自增长也可以单独使用[但是需要配合一个unique]
- 自增长修饰的字段为整数型的(虽然小数也可以但是非常非常少这样使用)
- 自增长默认从1开始,你也可以通过如下命令修改alter table 表名 auto_increment =新的值
- 如果你添加数据时,给自增长字段(列)指定的有值,则以指定的值为准,如果指定了自增长,一般来说,就按照自增长的规则来添加数据
修改默认的自增长初始值
ALTER TABLE t33 AUTO_INCREMENT =100
CREATE TABLE t33(
id INT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(32) NOT NULL DEFAULT ' ',
`name` VARCHAR(32) NOT NULL DEFAULT ' ');
INSERT INTO t33
VALUES(NULL,'tom.com','tom');
INSERT INTO t33
(email,`name`) VALUES('hsp.com','hsp');
SELECT * FROM t33;
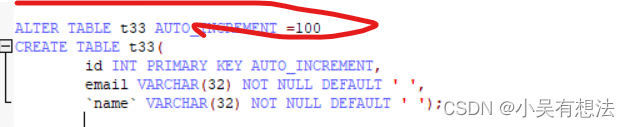

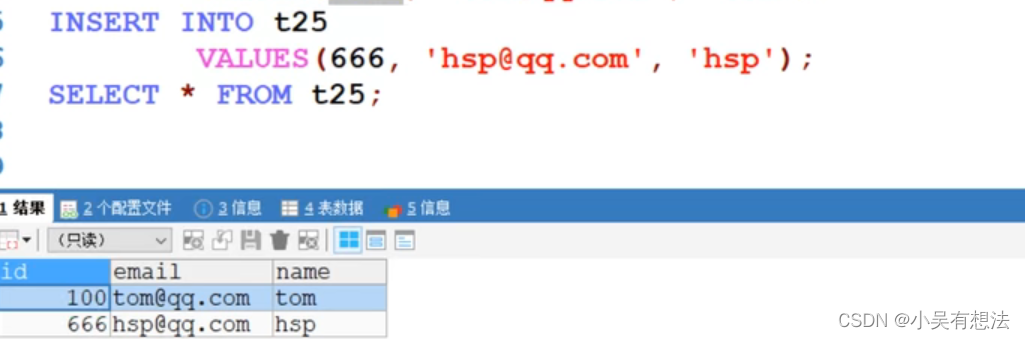
如果给第二条默认值改为666,则第二行是从666开始自增长(666优先级高一些),第三行一般情况就会是667
索引优化
说起提高数据库性能,索引是最物美价廉的东西了。不用加内存,不用改程序,不用调sql,查询速度就可能提高百倍千倍。
加入数据库里有800万个数据,在没有创建索引时,查询一条记录需要的时间相对来说比较长
由于得创建太多数据来演示一个例子不太方便,这里作为笔记直接记方法
如果查询emp数据库的数据empno,用索引的方法
先创建一个索引empno_index
CREATE INDEX empno_index ON emp(empno)
SELECT * FROM emp
WHERE empno=12345678;
然后写第二个语句即可
注意:
- 索引本身会占用空间
- 创建索引后,只对创建了索引的列有效
索引机制
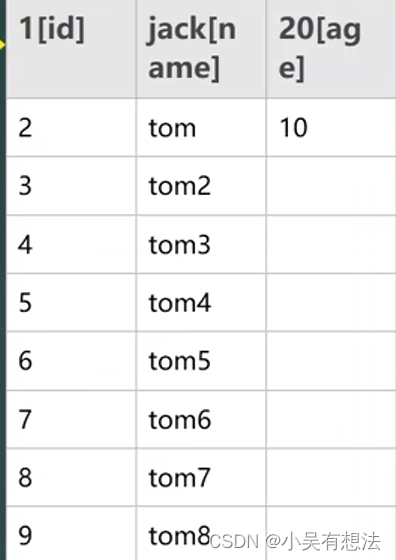
例如在这个表里查找id为1的数据,就算第一遍查找到了还是得继续查找,因为后面也可能有也可能没有,在没有创建索引的条件下查询很费时间。
如果创建了索引,就相当于一个在二叉搜索树里去查找
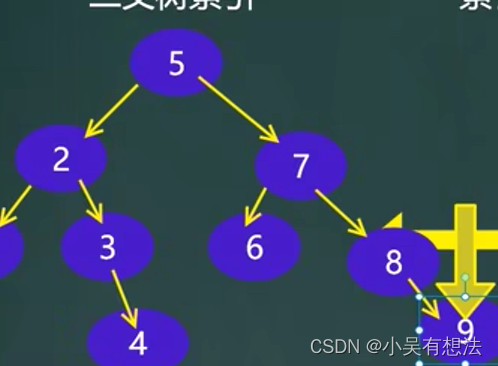
索引的代价:
- 磁盘占用(上面提到过)
- 对dml(update delete insert)语句的效率影响
索引的类型
1.主键索引
主键索引:主键自动的为主索引


2.唯一索引

3.普通索引

第二种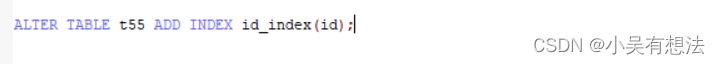
4.全文索引
全文索引(FULLTEXT)[适用于MylSAM]
开发中考虑使用:全文搜索 Solr 和 ElasticSearch (ES)
索引的使用
创建索引
CREATE TABLE t55
( id INT,
`name` VARCHAR(32));
-- 添加索引
-- 添加唯一索引
CREATE UNIQUE INDEX id_index ON t55(id);
SHOW INDEXES FROM t55;
这里的0代表否,非唯一索引吗->否,代表有唯一索引
![]()
如何选择?
- 如果某列的值,是不会重复的,则优先考虑使用unique索引,否则使用普通索引
删除索引


删除主键索引不用指定是哪一列,因为一张表最多一个主键索引
修改索引是先删除,在添加新的列
查询索引

总结:在哪些列上适合使用索引
- 较频繁的作为查询条件字段应该创建索引 select * from emp where empno=1
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件 select * from emp where sex=`男`
- 更新非常频繁的字段不适合创建索引
- 不会出现在WHERE子句中字段不该创建索引
以上为今天的视频笔记,如有侵权请联系我删除.
学习如逆水行舟,不进则退。和小吴一起加油吧!
















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











