







这两天做项目时,遇到了很奇怪的问题,再对页面有相同的元素的数据进行分组去重时,再执行的SQL相同的情况下,我本地的查询结果和同事本地的查询结果居然显示的内容不同。
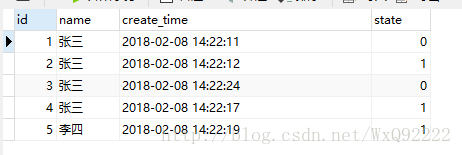
这是一张简单的表,只有id,name,state,create_time这四个属性。
现在我们的需求是:取出名称为张三和李四的两个人最新的数据。
再去重时,首先我们会想到使用 DISTINCT ,再者使用group by来进行分组去重。
因为工作年限的问题,在我使用distinct的过程中,主要都是用于计数。
下面来看一下使用group by如何实现拿到id为4和5的这两条数据:
select t.* from ( select * from test_table order by id desc )t group by t.name;
在使用客户提供的外网数据库时:查询出的结果为id=4和id=5的两条数据,没有任何问题,
但是当把这条SQL在本地执行时,运行结果却出人意料:
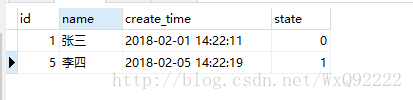
可以看到,执行之后的结果并不是4和5的记录,而是1和5的记录。怎么会这个样子?
原来,客户提供给我们的外网数据库使用的还是MySQL5.0的版本,在MySQL5.7版本之前,这样写
是没有任何问题的,在执行时:首先会执行子查询select * from test_table order by id desc,这时查到的结果为:
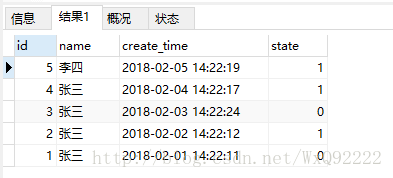
然后在使用group by进行分组时,默认取首条数据,所以查询结果为id为5和4的两条数据。
但是在5.7版本之后,MySQL对查询进行了优化,子查询中的order by再与group by连用时并不会生效,
那要怎么办呢?
解决办法:在MySQL5.7版本之后,如果要使用order by和group by,并使子查询中的order by生效,就必须加上
关键字 limit。
看一下正确的写法:
select t.* from ( select * from test_table order by id desc limit 0,10 )t group by t.name;
查询结果为:
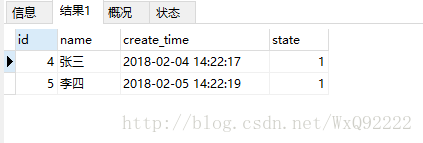
这样就达到了我们的目的。(加上limit之后,在老版本的数据库中仍然可以得到想要的结果)
说的有点啰嗦,最后说明一点:数据库一直在更新,为了防止客户把数据库进行了更新,所以我们还是按照最新
的标准来进行查询比较稳妥。















 3491
3491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









