







文章目录
- 入门
- 共指消解任务定义
- Methods
-
- Hobbs’ naive algorithm (1976)
- 中心理论
- Knowledge-based Pronominal Coreference
- 对数线性模型
- Simple neural network
- Mention-Pair Model
- Mention Ranking
- End-to-end Neural Coreference Resolution (Lee et al., EMNLP 2017)
- Last Coreference Approach: Clustering-Bas/最后一种共指方法:聚类Bas
- A Large Unsupervised Corpus for Coreference Resolution(EMNLP, 2019)
- BERT for Coreference Resolution: Baselines and Analysis(EMNLP, 2019)
- 参考文献
入门
定义
共指消解:找出文本中指代同一实体的表述。
CS224N的定义:找到所有指向真实世界中同一entity的mention。
 上面这个例子中,Barack Obama,his,he均指代Barack Obama,而Hillary Rodham Clinton、secretary of state、her、she、First Lady均指代Hillary Rodham Clinton。
上面这个例子中,Barack Obama,his,he均指代Barack Obama,而Hillary Rodham Clinton、secretary of state、her、she、First Lady均指代Hillary Rodham Clinton。
术语


- mention:文档中的实体的不同指代(表述),它可以是代词、也可以是命名实体、还可以是名词短语,其实也可以理解成文档中所有实体,为了和entity加以区别。
- antecedent:前指(先行词),前面那个mention,前指表示的是具体的实体,图1中 “Sally” 和 “she ” 具有共指关系,它们都表示“Sally”这个人。“Sally” 是具体化的实体,“she"是抽象化实体,即“Sally” 是“she”的前指,图二中"Barack Obama” 和 "he"也是如此。
- coreferent :共指关系,图中 “Sally” 和 “she ” 具有共指关系,它们都表示“Sally”这个人。
- cluster :同一mention的簇,就类似聚类中的簇,聚类是将同一类事务聚到一起,共指消解就是将文本中具有共指关系的mention 聚到一起。图中 “Sally” 和 “she ” 为一个簇, “John” 和 “him” 为一个簇, “violin”为一个簇。也比如{Barack Obama,his,he}也是一个簇。
- anapnoric :回指,回指表示的是抽象化的实体;指代称为照应(anaphor),也就是后面那个mention,图1中“Sally” 是具体化的实体,“she"是抽象化实体,即“she” 是“Sally”的回指,图二中"Barack Obama” 和 "he"也是如此。
- non-anapnoric:没有回指;即图中"violin"只有具体化的实体(它本身),没有抽象化的实体。
- span:一个句子中的短语或者子串。
- singleton:没有共指单独出现的 mention,和上面的non-anapnoric是一个意思.
- Cataphora:下指,和anapnoric 相反
并非所有的回指或下指都是共指关系。
理解mention:
Entity Mention:span of text referring to some entity,具体包括代词(pronouns)、命名实体(named entities)、名词短语(noun phrases)以及其它。
代词:可以通过词性标注工具来获取
命名实体:可以通过NER工具来获取
名词短语:parser,例如 a constituency parser
但是值得注意的是,并不是所有的代词、命名实体以及名词短语都是好的mention,例如:
(1)It is sunny
(2)Every student
(3)No student
(4)The best donut in the world
(5)100 miles
在上述例子中,这些mention指代的是一种抽象概念,而不是具体的事物。对于这些指代,可以通过训练一个分类器来过滤掉,但更常见的方法是将其视为候选指代。
理解span:
比如 小明和小李 这个文本段中,“小明 ” 、“小李” 、小明和小李 这都为mention ,假如这个文本后续的文本中出现 他们 这个mention ,那么 他们 和 小明和小李 就有共指关系。由于不知到具体哪个文本段为mention,所以一般都考虑所有的span(span 也就是序列),比如文本段小明和小李,他的span为 小 、小明 、小明和、小明和小、小明和小李、明。。。一段文本由T个word组成,那么span的数目为 T 2 T^{2} T2,把这些span都当作潜在的mention,这样的话计算量太大,后续需要修剪。
分类
在CS224N中分成 回指 和 下指
下指(Cataphora):指后照应,顺向照应(语言单位由下文加以说明),与回指的区别在于先行词通常在指代词的后面。
回指(anapnoric),即下文的词返指或代替上文的词。其中,被指代的上文中的词称之为先行词(antecedent),指代称为照应(anaphor)。

回指又可以分为两种:代词回指(pronominal anaphora),以及桥接回指(bridging anaphora)。
代词回指:照应通常是代词,需要找到代词对应的先行词。
桥接回指:在桥接回指中,照应和先行词都是具体指代,但是这两个指代之间存在一定的照应,或者说解释关系,例如下文中的“a concert”和“The tickets”:

在回指中,照应的解释在一定程度上依赖于先行词,重点在于找到指代对应的先行词;而对于共指,指代的解释取决于指代本身,重点在于判断指代之间是否具有共指关系,如图所示:
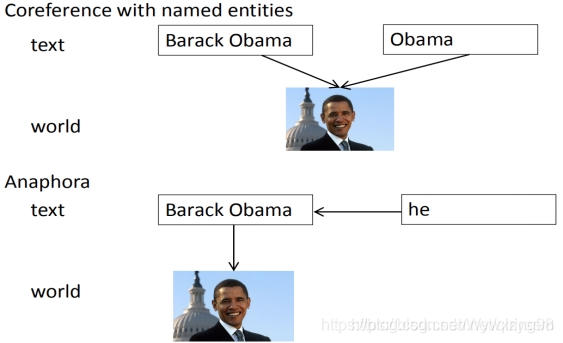 共指与回指之间存在一定的重叠关系,如图所示:
共指与回指之间存在一定的重叠关系,如图所示:

Four Kinds of Coreference Models/四种共指模式
基于规则的(代词回指解析)\提对\提及排名\聚类
其他文章中的分类解析:
从文强师兄学位论文中可以概括出其在冲突消解方面的主要工作包括:实体共指消解(resolving entity coreference)、模式匹配(schema matching)、宾语冲突消解(object conflicts resolution)。
实体解析(Entity Resolution)与共指消解的定义基本相同,实体匹配(Entity Matching)和实体对齐(Entity Alignment)主要侧重于不同的数据源之间是否指向同一实体。
共指消解可以作为实体链接的一部分:
step1:命名实体识别
step2:共指消解
step3:实体消歧
面向实体共指消解的机器学习综述
本节主要概括Vincent Ng 于2017年发表于AAAI会议的文章:Machine Learning for Entity Coreference Resolution: A Retrospective Look at Two Decades of Research. 本节将该论文讲述的利用机器学习解决实体共指的方法概括如下图: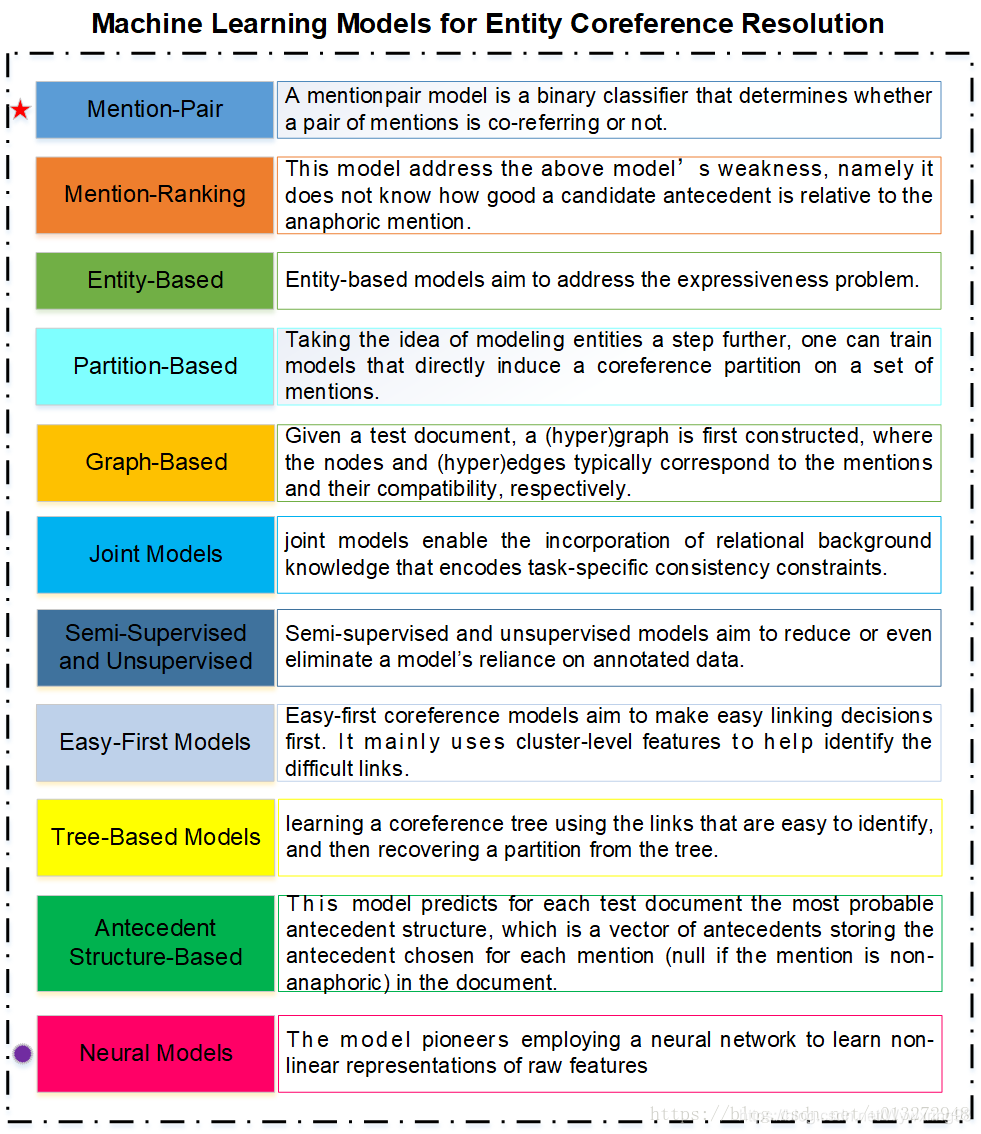 根据该文所述,Mention—Pair 模型为最具影响力的模型,Neural Models为值得深入研究的模型。
根据该文所述,Mention—Pair 模型为最具影响力的模型,Neural Models为值得深入研究的模型。
另一个文章“共指消解(一)”对现状的总结:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









