






一、基础介绍
HDFS DataNode以Block的形式,保存用户的文件和目录,同时在NameNode中生成一个文件对象,对应DataNode中每个文件、目录和Block。
NameNode文件对象需要占用一定的内存,消耗内存大小随文件对象的生成而线性递增。DataNode实际保存的文件和目录越多,NameNode文件对象总量增加,需要消耗更多的内存,使集群现有硬件可能会难以满足业务需求,且导致集群难以扩展。
规划存储大量文件的HDFS系统容量,就是规划NameNode的容量规格和DataNode的容量规格,并根据容量设置参数。
二、容量规格
①NameNode容量规格
在NameNode中,每个文件对象对应DataNode中的一个文件、目录或Block。一个文件至少占用一个Block,默认每个Block大小为“134217728”即128MB,对应参数为“dfs.blocksize”。默认情况下一个文件小于128MB时,只占用一个Block;文件大于128MB时,占用Block数为:文件大小/128MB。目录不占用Block。
根据“dfs.blocksize”,NameNode的文件对象数计算方法如下:

②DataNode容量规格
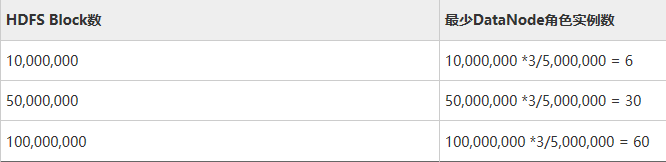
在HDFS中,Block以副本的形式存储在DataNode中,默认副本数为“3”,对应参数为“dfs.replication”。集群中所有DataNode角色实例保存的Block总数为:HDFS Block * 3。集群中每个DataNode实例平均保存的Blocks= HDFS Block * 3/DataNode节点数。
DataNode支持规格:
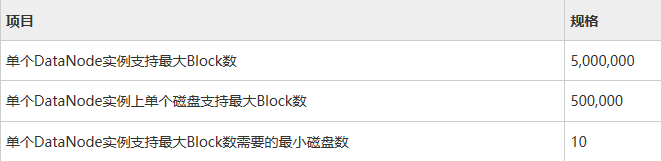
DataNode节点数规划:
三、内存参数设置
①NameNode JVM配置

②DataNode JVM配置
















 3222
3222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









