







分库分表
MySQL 作为单机数据库,随着请求量和数据量的增加一定会走分库分表之路。
什么场景需要分库分表?
分库解决什么问题?分表解决什么问题?
分库分表后会产生什么问题?
分库分表有什么实现方式?
拆分表
当表 的数据量大到一定程度时, 分区也不太好解决问题,此时就要拆分表结构,把一张表拆分成多张表,查询的时候根据拆分表的方式去相应的表中查询数据。
拆分表分为水平拆分和垂直拆分
- 水平拆分:根据某个列的值范围来划分数据是将一张表的数据,根据某个字段(主键或时间)分为多个表,每个表中的字段都是相同的 ,查询的时候根据拆分的字段找到相应的表去查询。
- 垂直拆分 : 减少单表的字段量,把一部分字段放到另一张表用字段关联上,有些查询可能不用到另一张表的字段就不用连表查询,减少表中一行的数据大小,这样一个数据页能放更多的行数据,查询起来更快。
分库分表的应用场景
案例场景:
数据库数据会随着业务的发展不断增多,单个表的数据量太大。简单一条count语句,在1000w数据量下,也需要运行几秒甚至超过十秒。一次查询扫描 10W 和 1000W 的数据,查询速度差距很大的。
单个数据库的连接数有限,当访问连接数过大时,就会连接失败。同时对大量数据访问集中在一台数据库上,对磁盘 IO 和 CPU 负载都会产生巨大的压力,会直接影响业务操作的性能。
- 分表解决数据过大的问题,提高数据处理的效率。
- 分库解决高并发的问题,目的就是为了缓解数据库的压力。
- 一般情况下,单表数据量过大,数据库高并发,会同时出现,然后采用分库分表。
这里参考阿里巴巴的《Java 开发手册》中数据库部分的建表规约:
单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
一般小于这个数据体量我们优先选择优化而不是分库分表。
分库分表原理和策略
- 分库:是把一个数据库,按实际场景切分多个库,再将数据表分散到多个库中。
- 分表(分片):是把一个数据库中的一个表拆分成多个表,防止单表过大。
- 策略:
-
- 分库分表的实现方式有两种:垂直拆分,水平拆分
垂直拆分
垂直拆分一般是按照业务和功能的维度进行拆分,把数据分别放到不同的数据库中。

- 垂直分库:
-
- 垂直分库根据业务维度进行数据的分离,把一个库分为多个库。
- 垂直分表:
-
- 垂直分表是对业务上的字段比较多的大表进行的,一般把宽表中不常用或者较独立的字段拆分到单独的数据表中。
水平拆分
水平拆分是把相同的表结构分散到不同的数据库和不同数据表中,避免集中访问单个数据库或者单个数据表。
例如:
电商业务中的订单信息访问频繁,可以将订单表分散到多个数据库中,实现分库;
在每个数据库中,继续进行拆分到多个数据表中,实现分表。
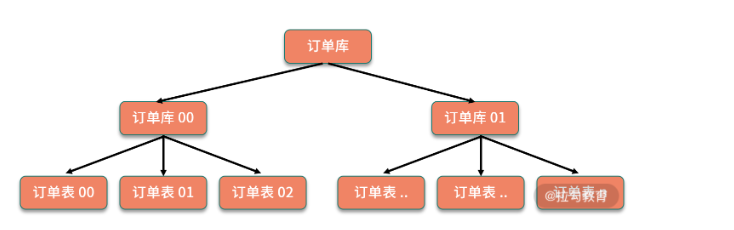
分表的字段选择
在分库分表的过程中,我们需要一个字段来进行分表。
比如:按照用户分表、按照时间分表、按照地区分表。那么这里的用户,时间,地区就是分表字段。
分表的算法
如何基于一个分表子段来准确的把数据分到某个表里?分表算法
但是不管什么算法,都要保证一个前提,那就是同一个分表字段,经过这个算法处理后,得到的结果一定是一致的,不可变的。
- 哈希取模算法
通过对某个字段的哈希值进行取模运算,将数据均匀的分不到不同的表中。
- 适用于:数据量大且分布均匀的场景,如用户中心等
- 优点:数据分布均匀,利于负载均衡。
- 缺点: 当扩容时,需要重新计算哈希值,导致数据迁移。
- 范围范围分区算法
根据某个字段的范围(如时间、ID等)将数据分布到不同的表中。
- 使用场景:适用于数据分布不均或需要按照一定顺序查询的场景,如订单中心等。
- 优点:
-
- 数据分区明确,便于管理和查询。
- 适用于按时间或ID等顺序查询的场景。
- 缺点:
-
- 如果数据分布不均匀,可能导致某些表的负载过重。
- 扩展性相对较差,因为可能需要重新调整分区范围。
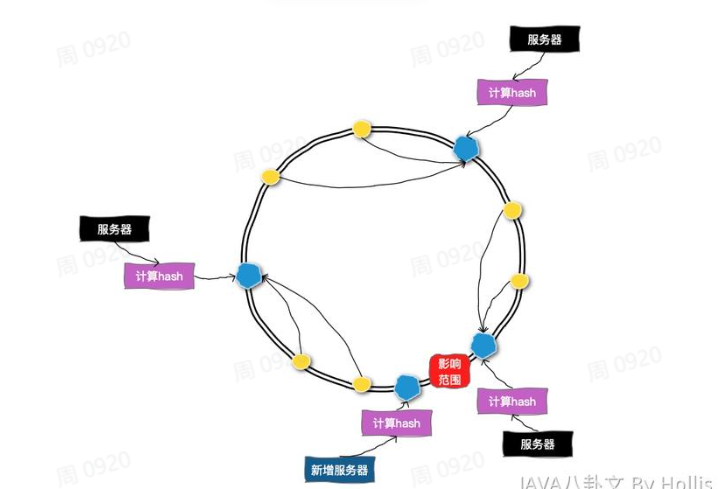
- 一致性哈希算法
一致性哈希可以将常用的 hash 算法来将对应的可以哈希到一个具有 2 的 32 次方个节点的空间中,形成一个顺时针收尾相接的闭合的环形。所以当添加一台新的数据库服务器时,只有增加服务器的 位置和逆时针方向第一台服务器之间的键会受影响。
- 优点:
-
- 数据分布均匀,系统容错性强
- 在节点增减时,对数据整体的影响较小
- 缺点:
-
- 当节点数据量变化较大时,然然会有数据迁移问题
- 维护成本高
- 雪花算法
雪花算法主要用于生成全局唯一的ID,也可以被视为一种特殊的分表算法,尤其是在需要按时间顺序分表时。
雪花算法通过生成包含时间戳、机器ID、服务ID和序列号等信息的唯一ID,可以在一定程度上指导数据的分布。
- 优点:
-
- 生成的ID全局唯一,且有序。
- 可以根据时间戳进行分表,便于管理和查询。
- 缺点:
-
- 需要额外的ID生成服务或算法实现。
全局 ID 如何生成问题
涉及到分库分表,就会引申出分布式系统中 唯一主键 id 的生成问题,因为在单表中我们可以用数据库主键做唯一 ID ,但是如果做了分库分表,多张单表中的自增主键就会发生冲突。那么就不会具备全局唯一性了。
如何生成一个全局 ID?
- UUID
可以做到全局唯一,生成方式也简单。
但是 UUID 太长了,其次字符串的查询效率很低,且没什么含义。
- 基于单个表做主键自增
所有的表都从一个表中获取 一个自增的 id,也可以做到全局唯一自增。
但是它存在单点问题,一旦挂了,那整个数据库都无法写入。
- 基于多个单表+ 步长做自增主键
实例 1 生成的 id 从 1000 开始 1999 结束。示例 2 生成的 id 从 2000 开始,到 2999 结束。实例 3 生成的 id 从 3000 开始 3999 结束。示例 4 生成的 id 从 4000 开始,到 4999 结束。
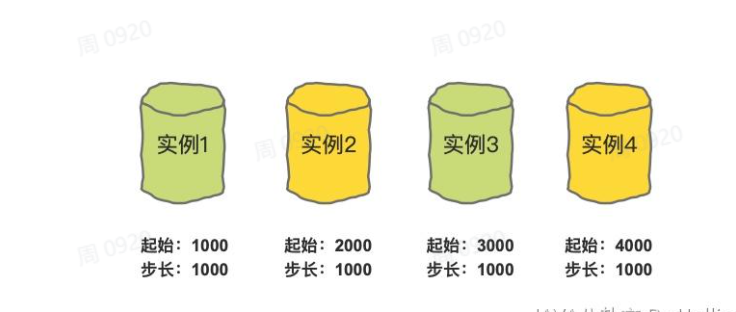
我们把步长设置为 1000,确保每一个单表中的主键起始值不一样,并且比当前的最大值相差 1000。
- 雪花算法
雪花算法是一种比较常用的分布式 id 生成方式,它具有全局唯一、递增、高可用的特点。
花算法通过生成包含时间戳、机器ID、服务ID和序列号等信息的唯一ID,可以在一定程度上指导数据的分布。
- 优点:
-
- 生成的ID全局唯一,且有序。
- 可以根据时间戳进行分表,便于管理和查询。
- 缺点:
-
- 需要额外的ID生成服务或算法实现
分表后产生的问题
- 垮库事务不支持
-
- 会产生数据一致性问题
- 做了分库分表,所有的读写操作,都需要带着分表字段,这样才知道去哪个库、那个表中查询数据。如果不带,就要支持全表扫描,单表的全表扫描很容易,分库分表就要扫描所有的物理表。
- 分库分表后,不能跨多表进行分页、排序。















 7491
7491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









