







这些API你不知道,真别刷算法了反正是个垃圾!
还有一些 API 接口设计规范,目的是提供给研发人员做参考。
规范是死的,人是活的,希望自己定的规范,不要被打脸。
路由命名规范
| 动作 | 前缀 | 备注 |
|---|---|---|
| 获取 | get | get{XXX} |
| 获取 | get | get{XXX}List |
| 新增 | add | add{XXX} |
| 修改 | update | update{XXX} |
| 保存 | save | save{XXX} |
| 删除 | delete | delete{XXX} |
| 上传 | upload | upload{XXX} |
| 发送 | send | send{XXX} |
请求方式
| 请求方式 | 描述 |
|---|---|
| GET | 获取数据 |
| POST | 新增数据 |
| PUT | 更新数据 |
| DELETE | 删除数据 |
请求参数
Query
url?后面的参数,存放请求接口的参数数据。
Header
请求头,存放公共参数、requestId、token、加密字段等。
Body
Body 体,存放请求接口的参数数据。
公共参数
APP 端请求
| 参数 | 说明 | 备注 |
|---|---|---|
| network | 网络 | WIFI、4G |
| operator | 运营商 | 中国联通/移动 |
| platform | 平台 | iOS、Android |
| system | 系统 | ios 13.3、android 9 |
| device | 设备型号 | iPhone XR、小米9 |
| udid | 设备唯一标示 | |
| apiVersion | API 版本号 | v1.1、v1.2 |
WEB 端请求
| 参数 | 说明 | 备注 |
|---|---|---|
| appKey | 授权Key | 字符串 |
调用方需向服务方申请 appKey(请求时使用) 和 secretKey(加密时使用)。
安全规范
敏感参数加密处理
登录密码、支付密码,需加密后传输,建议使用非对称加密。
其他规范
- 参数命名规范 建议使用驼峰命名,首字母小写。
- requestId 建议携带唯一标示追踪问题。
返回参数
| 参数 | 类型 | 说明 | 备注 |
|---|---|---|---|
| code | Number | 结果码 | 成功=1 |
失败=-1
未登录=401
无权限=403 |
| showMsg | String | 显示信息 | 系统繁忙,稍后重试 |
| errorMsg | String | 错误信息 | 便于研发定位问题 |
| data | Object | 数据 | JSON 格式 |
若有分页数据返回的,格式如下:
{
"code": 1,
"showMsg": "success",
"errorMsg": "",
"data": {
"list": [],
"pagination": {
"total": 100,
"currentPage": 1,
"prePageCount": 10
}
}
}
复制代码
安全规范
敏感数据脱敏处理
用户手机号、用户邮箱、身份证号、支付账号、邮寄地址等要进行脱敏,部分数据加 * 号处理。
其他规范
- 属性名命名时,建议使用驼峰命名,首字母小写。
- 属性值为空时,严格按类型返回默认值。
- 金额类型/时间日期类型的属性值,如果仅用来显示,建议后端返回可以显示的字符串。
- 业务逻辑的状态码和对应的文案,建议后端两者都返回。
- 调用方不需要的属性,不要返回。
签名设计
签名验证没有确定的规范,自己制定就行,可以选择使用 对称加密、非对称加密、单向散列加密 等,分享下原来写的签名验证,供参考。
日志平台设计
日志平台有利于故障定位和日志统计分析。
日志平台的搭建可以使用的是 ELK 组件,使用 Logstash 进行收集日志文件,使用 Elasticsearch 引擎进行搜索分析,最终在 Kibana 平台展示出来。
幂等性设计
我们无法保证接口的每一次调用都是有返回结果的,要考虑到出现网络异常的情况。
举个例子,订单创建时,我们需要去减库存,这时接口发生了超时,调用方进行了重试,这时是否会多扣一次库存?
解决这类问题有 2 种方案:
一、服务方提供相应的查询接口,调用方在请求超时后进行查询,如果查到了,表示请求处理成功了,没查到就走失败流程。
二、调用方只管重试,服务方保证一次和多次的请求结果是一样的。
对于第二种方案,就需要服务方的接口支持幂等性。
大致设计思路是这样的:
- 调用接口前,先获取一个全局唯一的令牌(Token)
- 调用接口时,将 Token 放到 Header 头中
- 解析 Header 头,验证是否为有效 Token,无效直接返回失败
- 完成业务逻辑后,将业务结果与 Token 进行关联存储,设置失效时间
- 重试时不要重新获取 Token,用要上次的 Token
小结
限流设计、熔断设计、降级设计,这些就不多说了,因为大部分都用不到,当用上了基本上也都在网关中加这些功能。
暂时就想到这么多,规范这东西不是一成不变的,发现有不妥的及时调整吧。
你们接口的输入输出 Key,命名是用驼峰还是下划线?欢迎留言。
集合
在刷题中,各种数据结构是我们常常用到的,例如栈实现迭代、哈希存储键值对等等,我们来看看常用集合和相关api。
| 类/接口 | 描述 | 方法 |
|---|---|---|
| String | 字符串 | charAt toCharArray split substring indexOf lastIndexOf replace length |
| List | 列表 | add remove get size subList |
| Stack | 栈 | push pop peek isEmpty size |
| Queue | 队列 | offer poll peek isEmpty size |
| Deque | 双向队列 | offerFirst offerLast pollFirst pollLast peekFirst peekLast isEmpty size |
| PriorityQueue | 优先队列 | offer poll peek isEmpty size |
| Set | add remove contains isEmpty size first(TreeSet) last(TreeSet) | |
| Map | put get getOrDefault containsKey containsValue keySet values isEmpty size |
数组
数组就不用多说什么了,大家最熟悉的数据结构。
Arrays
Arrays是比较常用的数组工具类,可以完成排序、拷贝等功能。
- 从小到大排序:Arrays.sort(int[] arr)Arrays.sort(int[] arr, int fromIndex, int toIndex)
Arrays.sort(int[] arr, int fromIndex, int toIndex, 比较器); //一定是需要泛型
Arrays.sort(arr, (o1, o2) -> o2 - o1); //数组全部 从大到小排序 跟Collections.sort()一样
Arrays.sort(arr, 0, 3, (o1, o2) -> o2 - o1); //从大到小排序,只排序[0, 3)
- 拷贝:Array.copyOf
int[] a = new int[5];
int[] newA = Array.copyOf(a, 5);
列表
列表主要有两种实现,分别是顺序表和链表。
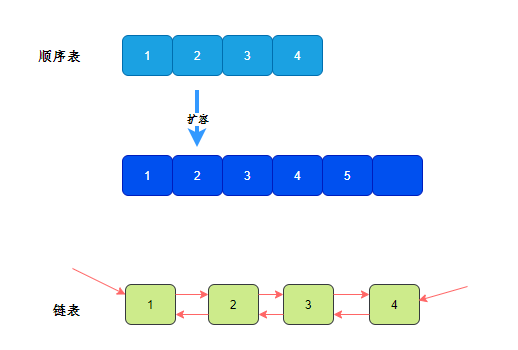
顺序表本质是一个可以动态扩容的数组,在Java中的实现是ArrayList。
链表是一个双向链表,Java中链表的实现为LinkedList。LinkedList在Java中可谓是非常强大的一个集合类,它还可以作为双向队列、栈来使用。
注意,ArrayList的扩容需要将旧的数组的元素复制到新的数组,时间复杂度为O(n)。
基本方法
- 构造
List<Integer> array = new ArrayList<>(); // 顺序表
// Set<Integer> a = new HashSet....
List<Integer> b = new ArrayList<>(a); //接受一个集合容器
- get
get(int index) // 返回元素位置在index的元素e --- array O(1), list O(n)
size() // 返回数组/链表长度 --- O(1)
- add
add(E e) // 在尾部添加一个元素e --- O(1)
add(int index, E e) // 在index位置插一个元素e --- O(n)
- remove
.remove(int index) // 删除位于index的元素,并返回删除元素e --- 删除最后元素为O(1), 其余为O(n)
//删除最后元素 list.remove(list.size() - 1);
- subList
.subList(int from, int to) // 相当于返回原数组的一个片段,但不要对其进行改动,改动会影响原数组 --- O(1)
// List<Integer> list, 对原来的list和返回的list做的“非结构性修改”(non-structural changes),
//都会影响到彼此对方. 如果你在调用了sublist返回了子list之后,如果修改了原list的大小,那么之前产生的子list将会失效,变得不可使用
复制代码
集合工具
Collections是集合工具类,提供了一些操作集合的方法。
- 排序
Collections.sort(list); 从小到大排序
Collections.sort(list, (o1, o2) -> o2 - o1); 从大到小排序, 第二个参数为一个比较器
复制代码
两种实现,ArrayList利于查找,LinkedList利于增删。
大概对比如下:
| 操作 | ArrayList | LinkedList |
|---|---|---|
| get(int index) | O(1) | O(n),平均 n / 4步 |
| add(E element) | 最坏情况(扩容)O(n) ,平均O(1) | O(1) |
| add(int index, E element) | O(n) ,平均n / 2步 | O(n),平均 n / 4步 |
| remove(int index) | O(n) 平均n /2步 | O(n),平均 n / 4步 |
栈
Java中定义了Stack接口,实现类是Vector。Vector是一个祖传集合类,不推荐使用。
那应该用什么呢?
Deque接口实现了完善堆栈操作集合,它有一个我们熟悉的实现类LinkedList。
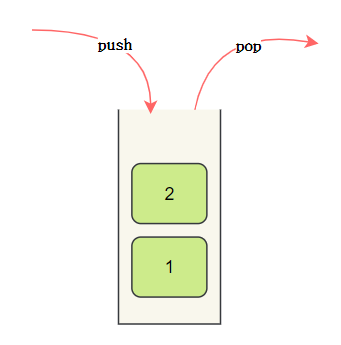
- 构造
Deque<Integer> stack=new LinkedList<>();
- push
push(E e); // 入栈元素e, 返回值为元素e --- O(1)
- pop
.pop(); // 出栈一个元素,返回出栈元素e --- O(1)
- peek
peek(); // 查看栈顶元素, 返回值为栈顶元素e --- O(1)
- isEmpty
isEmpty() // 若栈空返回true, 否则返回false --- O(1)
- size
size() // 返回栈中元素个数 --- O(1)
队列
队列s是一种先进先出的结构,在Java中的接口定义是Queue,具体实现还是我们的老朋友LinkedList。
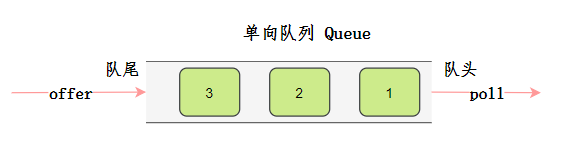
- 构造
Queue<Integer> q = new LinkedList<>();
- offer
offer(E e); // 队尾加入元素e。 若成功入队返回值true,否则返回false --- O(1)
- poll
poll(); // 出队头,返回出队元素e --- O(1)
- peek
peek(); // 查看队头元素, 返回值队首元素e --- O(1)
- isEmpty
isEmpty() // 若队空返回true, 否则返回false --- O(1)
- size
size() // 返回队中元素个数 --- O(1)
双向队列
Queue有一个子接口Dueue,即双向队列,和单向队列不同,它的出队入队可以从两个方向。
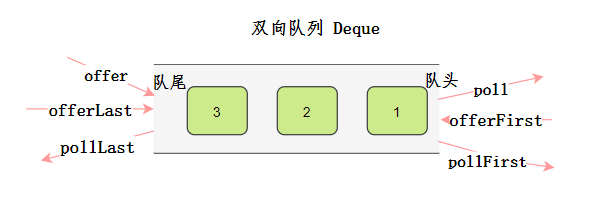
- 构造
Dueue<Integer> q = new LinkedList<>();
- offFirst
offFirst(Object e) // 将指定元素添加到双端队列的头部 --- O(1)
- offLast
offLast(Object e) //将指定元素添加到双端队列的尾部 --- O(1)
- pollFirst
pollFirst() //获取并删除双端队列的第一个元素 --- O(1)
- pollLast
pollLast() //获取并删除双端队列的最后一个元素 --- O(1)
- peekFirst
peekFirst() //获取但不删除双端队列的第一个元素 --- O(1)
- peekLast
peekLast() //获取但不删除双端队列的最后一个元素 --- O(1)
优先队列
优先队列是一种比较特殊的队列,保存队列元素的顺序不是按照元素添加的顺序来保存的,而是在添加元素的时候对元素的大小排序后再保存。
所以在队头的元素不是按照先后顺序,而是按照大小顺序。
在Java中的实现是PriorityQueue,底层是一棵树, 以小根堆为例。对于任意结点来说,该节点的值比其左右孩子的值都要小。 (就是最上面的结点最小)。 大根堆类似,最上面结点最大
- 构造
- 小根堆
Queue<Integer> minH = new PriorityQueue<>(); // 小根堆,默认大小为11 相当于 new PriorityQueue<>(11)
Queue<Integer> minH = new PriorityQueue<>(100); // 定义一个默认容量有100的小根堆。在当中增加元素会扩容,只是开始指定大小。不是size,是capacity
-
- 大根堆
Queue<Integer> maxH = new PriorityQueue<>((i1, i2) -> i2 - i1); // 大根堆,默认大小为11 相当于 new PriorityQueue<>(11, (i1, i2) -> i2 - i1)
Queue<Integer> maxH = new PriorityQueue<>(100, (i1, i2) -> i2 - i1); // 定义一个默认容量有100的大根堆。在当中增加元素会扩容,只是开始指定大小
- offer
offer(E e); // 在堆中加入元素e,并调整堆。若成功入堆返回值true,否则返回false --- O(logN)
- poll
poll(); // 弹出堆顶元素,并重新调整堆,返回出队元素e --- O(logN)
复制代码
- peek
peek(); // 查看堆顶元素, 返回值堆顶元素e --- O(1)
散列表
散列表示一种<key,value>型的数据结构,在Java中的实现是HashMap。
- 构造
Map<Characters, Integer> map = new HashMap<>();
- put
put(K key, V value); // 在Map中加入键值对<key, value>。返回value值。如果Map中有key,则replace旧的value --- O(1)
- get
get(K key); // 返回Map中key对应的value。若Map中没有该key,则返回null --- O(1)
- getOrDefault
getOrDefault(K key, V defaultValue); // 返回Map中key对应的value。若Map中没有该key,则返回defaultValue --- O(1)
// For example:
// Map<Character, Integer> map = new HashMap<>();
// if (...) // 如果发现k,则k在Map中的值加1。没一开始没有k,则从0开始加1。(相当于给了key在Map中的一个初试值)
map.put('k', map.getOrDefault('k', 0) + 1);
- containsKey
containsKey(Key key); // 在Map中若存在key,则返回true,否则返回false --- O(1)
get(x) == null // 可以代替改用法
- keySet
keySet(); // 返回一个Set,这个Set中包含Map中所有的Key --- O(1)
// For example:
// We want to get all keys in Map
// Map<Character, Integer> map = new HashMap<>();
for (Character key : map.keySet()) {
// Operate with each key
}
- values
values(); // 返回一个Collection<v>,里面全是对应的每一个value --- O(1)
// For example:
// We want to get all values in Map
// Map<Character, Integer> map = new HashMap<>();
for (Integer value : map.values()) {
// Operate with each values
}
- isEmpty
isEmpty() // 若Map为空返回true, 否则返回false --- O(1)
- size
.size() // 返回Map中中键值对<K, V>的个数 --- O(1)
Set
Set是一种没有重复元素的集合,常用的实现是HashSet。
- 构造
Set<Integer> set = new HashSet<>();
List<Integer> list = new ArrayList<>....;
Set<Integer> set = new HashSet<>(list);
- add
.add(E e); // 在集合中添加元素E e, 若成功添加则返回true,若集合中有元素e则返回false --- O(1)
- remove
remove(E e); // 在集合中删除元素e,若删除成功返回true;若集合中没有元素e,返回false --- O(1)
- contains
contains(E e); // 若存在元素e,则返回true,否则返回false --- O(1)
- isEmpty
isEmpty() // 若集合为空返回true, 否则返回false --- O(1)
- size
size() // 返回集合中中元素个数 --- O(1)
- first
first() // 返回集合里的最小值(若给了比较器从大到小则是返回最大值)
- last
last() // 返回集合里的最大值(若给了比较器从大到小则是返回最小值)
字符串
String
不可变量(相当于只读final修饰),每个位置元素是个char。

- 初始化
字符串复制初始化
String s = ``"abc"``;
基于另外一个字符串
// s = "abc"``String s2 = ``new` `String(s);
基于char[]
// s = "abc";
// char[] c = s.toCharArray();
String s3 = new String(c);
// 可以偏移
// public String(char value[], int offset, int count)
String s4 = new String(c, 1, 2); // [offset, offset + count) [)
// 把char[] 变成字符串
char[] ch = {'a', 'b', 'c'};
String.valueOf(ch);
- charAt
charAt(int index); // 返回index位置的char --- O(1)
- length
length(); // 返回字符串长度 --- O(1)
- substring
substring(int beginIndex, int endIndex); // 返回字符片段[beginIndex, endIndex) --- O(n)
substring(int beginIndex); // 返回字符片段[beginIndex, end_of_String) 就是从beginIndex开始后面的 ---- O(n)
- indexOf
indexOf(String str) // 返回str第一个出现的位置(int),没找到则返回-1。 --- O(m * n) m为原串长度, n为str长度
// (假如要找一个字符char c,str可以表示成String.valueOf(c),然后作为参数传进去.
s.indexOf(String str, int fromIndex); // 同上,但从fromIndex开始找 --- O(m * n)
- lastIndexOf
lastIndexOf(String str); // 返回str最后出现的位置(int),没找到则返回-1。 --- O(m * n) m为原串长度, n为str长度
// (假如要找一个字符char c,str可以表示成String.valueOf(c),然后作为参数传进去.
lastIndexOf(String str, int fromIndex); // 同上,
//但从fromIndex开始从后往前找 [0 <- fromIndex] --- O(m * n)
- replace
replace(char oldChar, char newChar); // 返回一个新字符串String,其oldChar全部变成newChar --- O(n)
- toCharArray
toCharArray(); // 返回char[] 数组。 把String编程字符数组 --- O(n)
- trim
trim(); // 返回去除前后空格的新字符串 --- O(n)
- split
split(String regex); // 返回 String[],以regex(正则表达式)分隔好的字符换数组。 ---- O(n)
// For example
// 从非"/"算起 若"/a/c" -> 会变成"" "a" "c"
String[] date = str.split("/"); // date[0]:1995 date[1]:12 date[2]:18 --- O(n)
- toLowerCase, toUpperCase
s = s.toLowerCase(); // 返回一个新的字符串全部转成小写 --- O(n)
s = s.toUpperCase(); // 返回一个新的字符串全部转成大写 --- O(n)
StringBuilder
由于String是所谓的不可变类,使用 str+这种形式拼接字符串实际上,是JVM帮助循环创建StringBuilder来拼接,所以拼接字符串最好用StringBuilder。
- 构造
StringBuilder sb = new StringBuilder();
- charAt
charAt(int index); // 返回index位置的char --- O(1)
- length
length(); // 返回缓冲字符串长度 --- O(1)
- apped
append(String str) // 拼接字符串 --- O(n)
- toString
toString(); // 返回一个与构建起或缓冲器内容相同的字符串 --- O(n)
复制代码
数学
最大最小值
在一些题目里,需要用到最大,最小值,Java中各个数据类型的最大最小值定义如下:
fmax = Float.MAX_VALUE;
fmin = Float.MIN_VALUE;
dmax = Double.MAX_VALUE;
dmin = Double.MIN_VALUE;
bmax = Byte.MAX_VALUE;
bmin = Byte.MIN_VALUE;
cmax = Character.MAX_VALUE;
cmin = Character.MIN_VALUE;
shmax = Short.MAX_VALUE;
shmin = Short.MIN_VALUE;
imax = Integer.MAX_VALUE;
imin = Integer.MIN_VALUE;
lmax = Long.MAX_VALUE;
lmin = Long.MIN_VALUE;
Math
- max
Math.max(long a, long b); //返回两个参数中较大的值
- sqrt
Math.sqrt(double a); //求参数的算术平方根
- abs
Math.abs(double a); //返回一个类型和参数类型一致的绝对值
- pow
Math.pow(double a, double b); //返回第一个参数的第二个参数次方。
- ceil
Math.ceil(double x); //向上取整
- floor
Math.floor(double x); //向下取整
- round
Math.round(double x); //四舍五入















 9497
9497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











