







HashMap 的实现原理和扩容原理是怎样的?
一、实现原理
1.1 哈希表
1.1.1 概述
要学习 hashmap,就不得不提哈希表。
维基百科定义如下:
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存储存位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
在 java 中,保存数据有两种比较简单的数据结构:数组 和 链表。
- 数组:寻址容易,插入和删除困难;
- 链表:寻址困难,但插入和删除容易。
它是把数组和链表这两种结构结合在一起,发挥出各自的优势,这种结构就是哈希表。
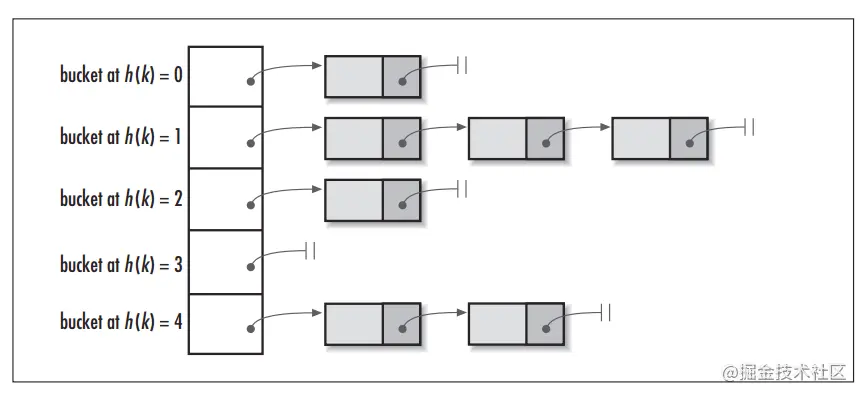
1.1.2 哈希冲突
何为 hash 冲突,当我们对某个元素插入之后,发现该位置已经被其他元素占用了。这就是哈希碰撞,这种情况是不可避免的,比如著名的抽屉原理,在三个抽屉里面放入四个苹果,那么至少有一个抽屉不少于一个苹果。这就是冲突。
哈希冲突解决的方法有很多种,常见的有:
- 开放定址法
- 再散列法
- 链地址法:hashmap 采用的此方法。
hashMap 正是基于哈希表的 map 接口的非同步实现。此实现提供了所有可选的映射操作,并允许使用 null 值和 null 键,但它不保证映射的顺序。
1.2 存储分析
hashmap 的主干是一个 Node 数组,里面存放了很多 Node 元素,Node 是 HashMap 的基本组成单元,每个 Node 包含一个key-value 的键值对。
/**
* 第一次使用初始化表,并将大小调整为必要的。分配时,长度总是2的幂
*/
transient Node<K,V>[] table; // transient 关键字是防止属性被序列化
这里面的每个小黑点就是 Node 节点。
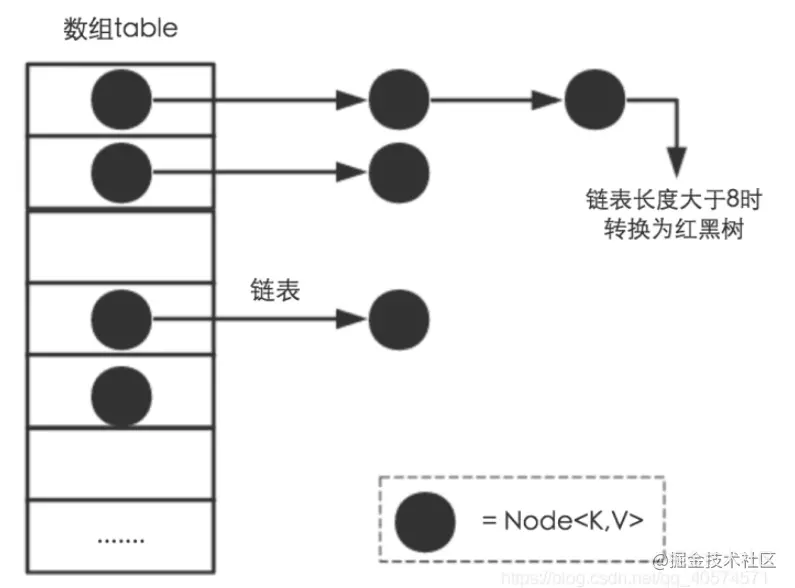
Node 它是 HashMap 中的一个 静态内部类,实现了 Map.Entry 接口,代码如下:
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 用来定位数组索引位置
final K key;
V value;
Node<K,V> next; // 链表的下一个node节点
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() {
return key; }
public final V getValue() {
return value; }
public final String toString() {
return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
1.3 hash 算法
哈希桶的数组如果很大,那么分配的元素就会很分散,占用更多空间;如果哈希桶的数组很小,就会发生多次hash冲突。
如何控制空间更少 的同时碰撞过少,就需要让哈希桶的大小在一个合理的范围内,这就需要学习 Hash 算法。
hash 算法本质上分为三步:
-
1、取 key 的 hashCode 值
问题1:java中对象都已一个hashCode()方法,那为什么还需要hash函数呢?
答:hashcode 返回值为int 类型且长度不定,为了满足理想的散列表数组大小,我们需要将 hashcode 值转换唯一定长的hash值。
-
2、高位运算
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











