







一、集合的理解
1.概念:
一种操作方便的对象容器,可以用于存储管理多个对象,存储多个对象的工具,很多情况下替换数组
2.集合相关内容基本位于 java.util 包中
3.集合从以下4个内容学习
(1) 集合特点
(2) 集合的功能方法
(3) 集合的实现类
(4) 集合遍历
4.集合的分类
(1) Collection集合体系
a. List集合
b. Set集合
(2) Map集合体系
二、Collection集合体系
1. 根接口:Collection接口
(1) 特点:存储多个Object对象
(2) 方法:
boolean add(Object o):往集合中添加一个对象,添加成功-true;不成功-false
int size():获取集合中元素的个数
void clear():清空集合中元素
boolean contains(Object o):判断集合中是否包含o对象
boolean isEmpty():判断集合是否为空
boolean remove(Object o):将o对象从集合中移除
(3) 实现类:没有直接的实现类,详见子接口
(4) 遍历:详见子接口
2. 子接口:List集合
(1) 特点:存储多个Object对象,有序、有下标、元素可重复、下标从0开始,到集合元素个数-1
(2) 方法:
boolean add(Object o):往集合中添加元素
Object get(int index):获取指定下标对应的元素
注意:如果指定下标超过下标的范围,则运行报错,
错误信息为:java.lang.IndexOutOfBoundsException (下标越界)
Object remove(int index):删除指定下标的元素
Object set(int index,Object o):将指定下标位置的元素进行替换,被替换的对象作为返回值返回
(3) 实现类:ArrayList
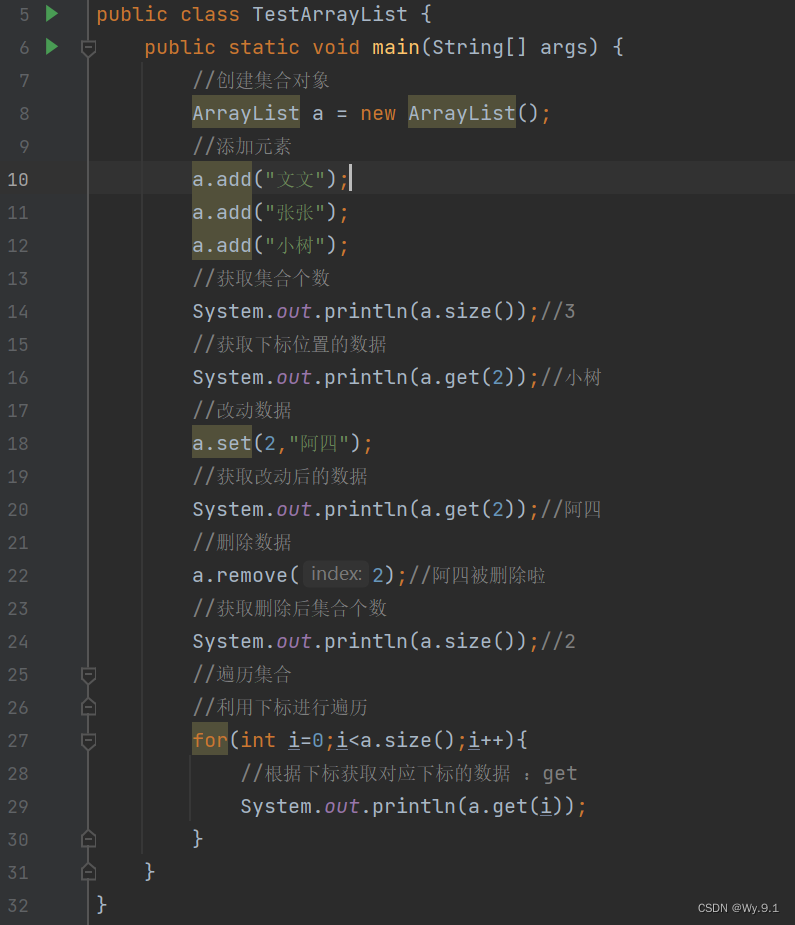
(4) 遍历:
a. 下标遍历
for(int i=0;i<集合名.size();i++){
// 根据下标获取元素
System.out.println(list.get(i));
}
b. forEach遍历
for(数据类型 变量名:集合名){
// 利用变量名直接操作元素
}
注意:()中的数据类型取决于集合中泛型的类型
(5) 泛型集合:
a. 目的:保证集合中的数据类型统一,方便对集合中元素进行统一管理
b. 语法:
List<数据类型> list = new ArrayList<>();
注意:后面<>中的数据类型可以省略,但是<>不能省

c. 基本数据类型不能作为泛型,需要使用对应的包装类
List<Integer> a=new ArrayList<Integer>();
(6) List接口不同实现类的区别
实际开发时常用的List实现类为ArrayList,创建集合对象时,底层数组长度为0,只有当第一次往集合中添加元素(第一次调用add方法),为数组分配空间,数组长度默认为10,如果存储的元素个数达到底层数组长度上限时,自动扩容,每次扩容为原来的1.5倍(每次扩容如果倍数太大,空间利用率太低;每次扩容一个长度,导致扩容太频繁,降低程序效率)
a. ArrayList:底层数组实现,查询效率高,增删效率较低;jdk1.2版本,线程不安全,并发效率高
b. Vector:底层数组实现,查询效率高,增删效率较低;jdk1.0版本,线程安全,并发效率低
c. LinkedList:底层链表实现,查询效率较低,增删效率高
补充:数据结构,两种数据存储形式:
数组:内存中空间连续,方便管理,但是空间利用率低
链表:内存空间不连续,空间利用率高(一个链表由多个节点组成)
3. 子接口:Set集合
(1) 特点:存储任意类型对象,无序、无下标、元素内容不可以重复
(2) 方法:继承于父接口Collection
(3) 实现类:HashSet
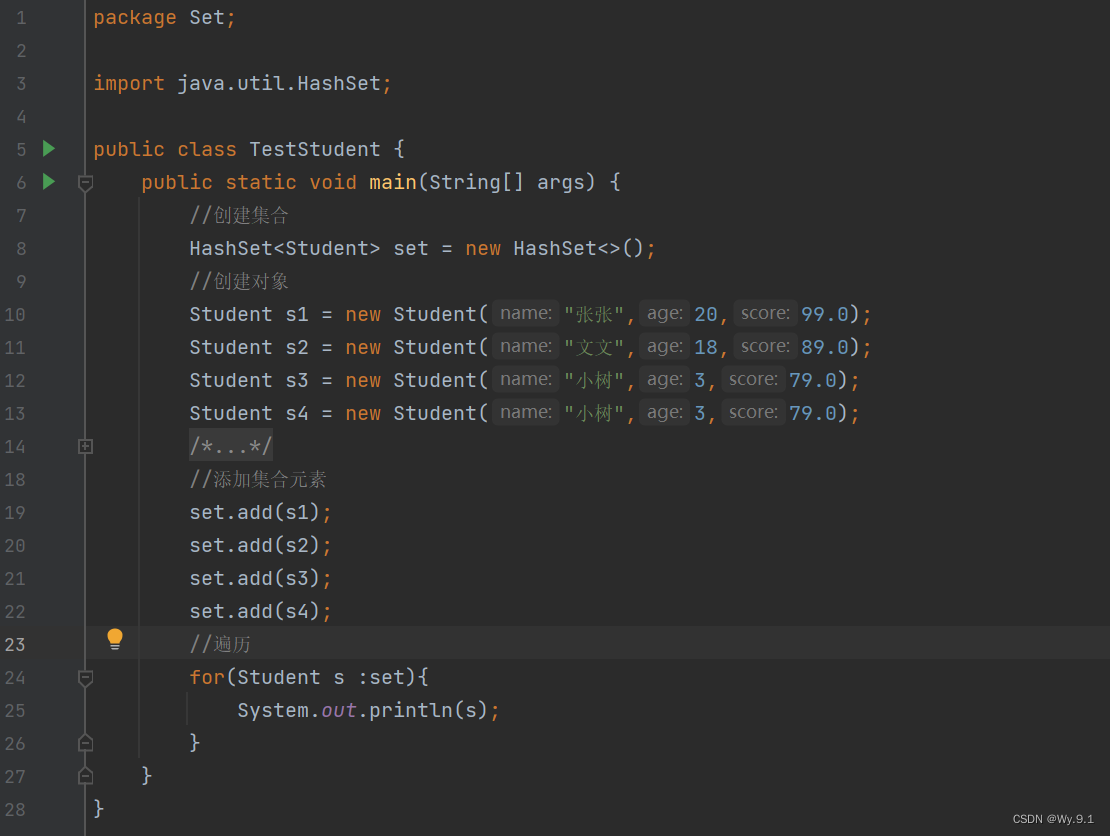
注意:如果自定义类型的对象存储在HashSet集合中,为了保证元素内容不重复,存储对象对应的类需要覆盖 hashCode方法和equals方法

1、覆盖hashCode方法的原则:
必须保证内容相同对象返回相同的哈希码值,为了提高效率,内容不同对象尽可能返回不同的哈希码值;通常是将所有属性(内容)参与哈希码值的覆盖
2、HashSet存储原理:
当对象添加到HashSet集合中,调用添加对象对应类中hashCode方法获取对象的哈希码值,通过(哈希码值%底层数组长度)计算一个下标进行存储,如果获取的下标位置上没有任何元素直接存储,但是如果获取下标位置上已经存在元素,则需要调用该对象的equals方法,判断两个对象的内容是否相同,equals方法返回结果为true,拒绝该对象添加,返回结果为false,则成功添加,采用的数组+链表形式进行存储
(4) 遍历方式:forEach遍历
(5) 实现类:
LinkedHashSet:是HashSet子类,也是Set实现类,无下标、元素内容允许不重复,跟根据元素添加顺序进行存储(如果自定义类型的对象存储在LinkedHashSet中,为了保证元素不重复,需要覆盖hashCode和equals方法)
三、Map集合体系
1、Map集合特点
(1) 存储键值对(key-value),一个键值对为Map集合中一个元
(2) 键:无序、无下标、元素不允许重复(唯一性)
(3) 值:无序、无下标、元素可以重复
2、方法:
(1) V put(K key,V value):往map集合中添加一个键值对,如果添加键值对key不存在,则直接添加;如果添加键值对key在当前map中已经存在,则用新的value替换原来的value,被替换的value作为返回值返回
put两个含义: a. 添加 b. 修改:利用key修改value值
(2) int size():获取map中键值对个数
(3) V get(K key):根据key获取对应value值
(4) boolean containsKey(K key):判断当前map集合中是否包含某一个键,包含-true;不包含-false
(5) boolean containsValue(V value):判断当前集合中是否包含某一个值,包含-true;不包含-false
(6) V remove(K key):根据键删除对应的键值对,被删除的value作为返回值返回
3、实现类:HashMap
4、遍历方式
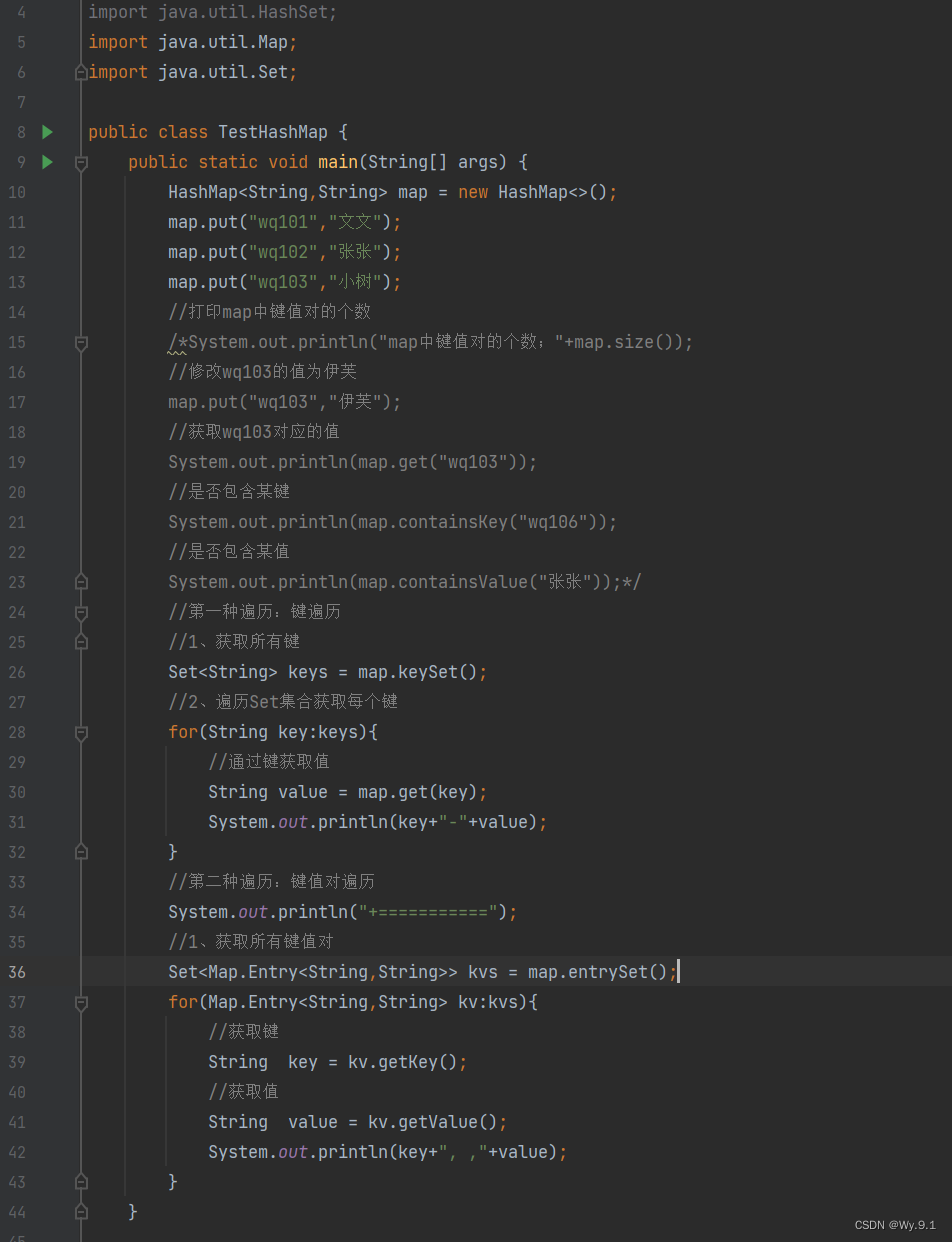
(1) 键遍历:
a. 获取所有的键
Set<K> keys = map.keySet();
b. 遍历set集合获取每一个键:
for(K key:keys){
// 通过键获取对应的值
V value = map.get(key);
// 通过key和value操作
}
(2) 键值对遍历:
a. 获取所有的键值对Entry
Set<Map.Entry<K,V>> kvs = map.entrySet();
b. 遍历set集合获取每一个Entry
for(Map.Entry<K,V> kv : kvs){
// 从键值对获取键和值
K key = kv.getKey();
V value = kv.getVlaue();
}
5、Map中常见的不同实现类
(1) HashMap:JDK1.2版本,线程不安全,并发效率高,允许null作为key/value
(2) Hashtable:JDK1.0版本,线程安全,并发效率低,不允许null作为key/value
(3) LinkedHashMap:是HashMap子类,可以按照键添加的顺序进行存储
(4) Properties:是Hashtable子类,是Map的实现类,键和值默认为String
( Properties pro = new Properties();// 通常用于加载配置文件)
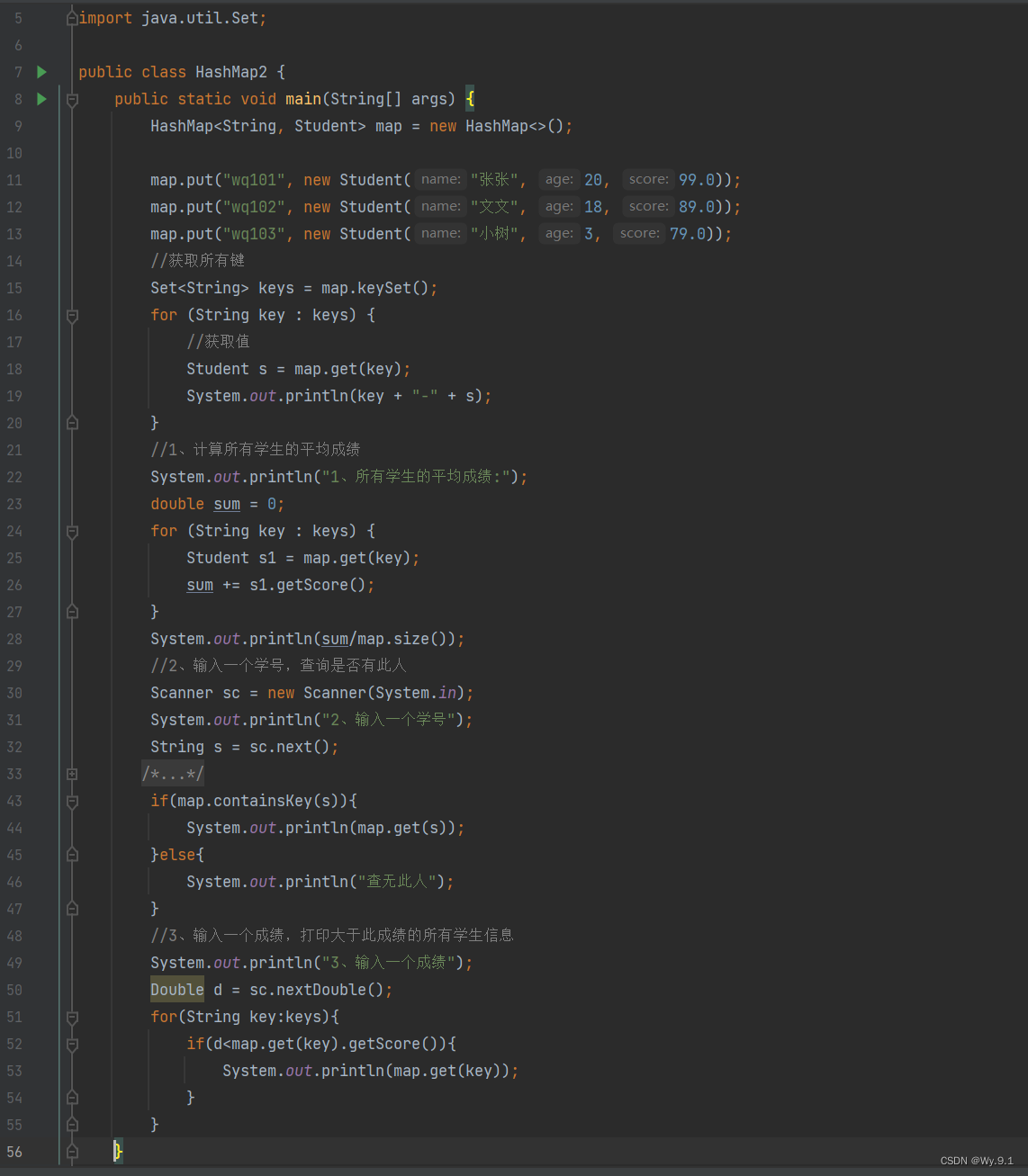
6、补充:
HashSet底层封装了HashMap,如果自定义类型的对象存储在HashMap中作为key,为了保证map的key不重复,自定义的对象对应类需要覆盖hashCode和equals方法;但是实际开发通常使用String/Integer类型作为Map的key,这些类已经覆盖了hashCode和equals方法。
HashMap存储原理:HashMap底层为数组(Entry/Node存储键值对),每次存储键值对时,调用key对应对象的hashCode方法获取对象的哈希码值,通过计算获取一个存储下标,如果存储下标上没有元素,直接存储,但是如果存储下标上已经有其他元素,此时调用key对应equals方法,true-键已经存储在map中,利用新的value替换对应的value值;false-键不存在,则成功添加,此时采用数组+链表形式进行存储。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









