









正则表达式,我一直学的云里雾里的,很多的元字符都弄不清楚,今天看完了《正则表达式必知必会》这本书,觉着讲的很棒,现在把相关知识总结如下:
写在前面:其实正则表达式并不难,只要静下心来去学习,就会发现真的不难,
一、什么是正则表达式?
正则表达式:简单的说,正则表达式就是一些用来匹配和处理文本的字符串,其可以看作是内嵌在其他语言里的“迷你”语言。其实,语法是正则表达式最容易掌握的地方,真正的挑战是学会如何运用哪些语法把实际问题分解为一系列正则表达式并最终解决
**正则表达式的用途:**1、查找特定的信息(搜索);2、查找并编辑特定的信息(替换)
小工具:http://www.forta.com/books/0672325667/ 可以在这个网站上下载 Regular Expression Tester(正则表达式测试器)
注意 Note: 1、使用正则表达式时,几乎所有的问题都有不止一种解决方案,并且学习的时候一定要动手去实践。2、把必须匹配的情况考虑周全并写出一个正则表达式很容易,但是把不需要匹配的情况考虑周全并确保它们被排除在外就有点难度了。所以在构造一个正则表达式的时候一定要把你想匹配什么和你不想匹配什么都详尽的列出来,定义清楚。
二、正则表达式的基本语法(JavaScipt适用)
1、匹配单字符
(1)匹配纯文本
文本 :
Hello,i’m vicky , nice to meet you .
正则表达式:
vicky(区分大小写)
匹配结果:
Hello,i’m vicky , nice to meet you .
正则表达式可以包含纯文本
(2)匹配任意字符
. (英文状态下的句号)可以匹配任意一个单个的字符。.字符可以用来匹配任意单个的字符/字母/数字甚至是.本身。
文本
cat cot aat cmt ccc
正则表达式
c.t
匹配结果
cat cot aat cmt ccc
(3)匹配特殊字符
如果在正则表达式中需要用到元字符,则需要使用 ”\“ 进行转义
2、匹配一组字符(字符集)
[ ] 可以用来定义一个字符集,在[ ]这两个元字符之间的所有字符都是该集合的组成部分,字符集合的匹配结果是能够与该集合里的任意一个成员相匹配的文本。作为元字符,- 只能用在 [ ]之间。
例如:
[nN]可以匹配的是 n或者N
(1)字符集合区间
正则表达式……提供了一个特殊的元字符 - ,字符区间可以使用 - (连字符)来定义。
[0-9] :等价于 [012346789]
[A-Z] :匹配从A到Z的所有大写字母
[a-z] :匹配从a到z的所有小写字母
(2)取非匹配
取非匹配是指:除了那个字符集合里的字符,其他字符都可以匹配。元字符^表明对一个字符集合进行取非匹配。
[^0-9] :除了0-9的其他字符都匹配
注意:^的效果将作用于给定字符集里的所有字符或字符区间,而不仅限于紧跟在^字符后面的那一个字符或字符区间。
3、一些常用元字符
元字符大致可以分为两种:一种是用来匹配文本的比如 . 另一种是正则表达式的语法所要求的 ,比如定义字符集的[ ] 。
(1)空白字符
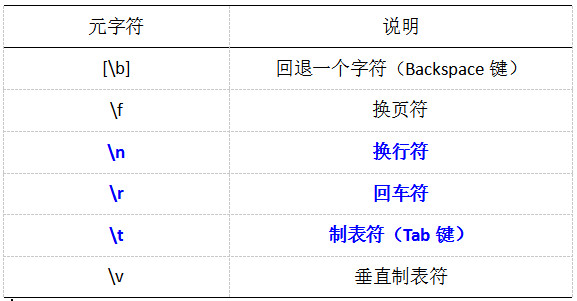
(2)匹配数字

修正:上表中标注错误,应改为\d \D; \b是单词边界\B为\b的反义。感谢@chenshiforever同学指出错误!
正则表达式的语法是区分大小写的,\d匹配数字,\D与\d含义刚好相反
(3)匹配字母和数字

(4)匹配空白字符

4、重复匹配
(1)匹配一个或多个字符
+ 要想匹配同一个字符(或字符集合)的多次重复,只要简单的给这个字符(或字符集合)加上一个+字符作为后缀就可以了。+匹配一个或多个字符(至少一个)
例如:
[\w.]+ 将匹配一个或多个 (字母数字字符、下划线和.)的一次或多次重复出现
(2)匹配零个或多个字符
* 只要把*放在一个字符或者字符集的后面,就可以匹配该字符连续出现零次或多次的情况
* 和+的区别:
+匹配一个或多个字符或字符集合,至少要匹配一次;
*匹配零个或任意多个字符或字符集合,可以没有匹配
(3)匹配零个或一个字符
? 只能匹配一个字符或字符集合的零次或一次出现,最多不能超过一次。
例如:
https?://
既可以匹配http://也可以匹配https://
(4)匹配的重复次数
{ } 重复次数要用{ }字符来给出,把数值写在它们之间。
{n} 精确匹配n次
如:[0-5]{2} 0-5之间的数字重复两次,即可以匹配01 02 03 04 05 一直到55 之间的任意数字
{n,m} n为下限,m为上限
如:\d{1,3} 匹配1个到3个数字字符
{n,}至少匹配n次
如:\d{3,}至少匹配3个数字字符
(5) 贪婪型元字符与懒惰型元字符

* + {n,} 匹配次数都没有上限,他们属于是贪婪型元字符,他们在进行匹配时的行为模式是多多益善,而不是适可而止的。它们会尽可能的从一段文本的开头一直匹配到这段文本的末尾,而不是从这段文本的开头匹配到第一个匹配项为止。
例如:
文本:
This offer is not available to customers living in < B> AK < \B> and < B>HI< /B>
正则表达式
<[Bb]>.*< /[Bb]>
匹配结果
This offer is not available to customers living in** < B> AK < \B> and < B>HI< /B>**
把第一个B标签和最后一个/B标签中间的所有文本都匹配出来了,这并不是我们想要的结果,如何修正呢?使用懒惰型元字符。懒惰型元字符会选择匹配尽可能少的字符。
正则表达式
<[Bb]>.*?< /[Bb]>
匹配结果
This offer is not available to customers living in< B> AK < \B> and < B>HI< /B>
5、位置匹配
(1)单词边界
\b 用来匹配一个单词的开始或者结尾
\B 匹配不是单词的字符
例如:
文本
The cat scattered his food all over the room.
正则表达式
/bcat/b
匹配结果
The cat scattered his food all over the room.
只会匹配到cat 而不会匹配到scattered中的cat,注意 \b只匹配一个位置,不匹配任何字符。
(2)字符串边界
^ 用来定义字符串的开始。^是不是有点眼熟呢,对的,之前介绍过它,它在[ ]字符集里面使用表示取非的意思
$ 用来定义字符串的结束
6、子表达式
子表达式用()括起来,把一个表达式划分为一系列子表达式的目的是为了把那些子表达式当作一个独立元素来使用。
例如,我们想把一条用户记录里的年份数字完整的记录下来,我们只记录年。
文本
ID:022
SEX:M
DOB:1967-08-17
Status:Active
正则表达式
19|20\d{2}
匹配结果
ID:022
SEX:M
DOB:1967-08-17
Status:Active
分析:
结果只匹配出了19,为什么呢 ,| 表示或操作,为了避免匹配出无意义的年份,正则表达式 19|20\d{2} 的意思是 匹配 19 或者 20\d{2} .那么如何改进呢?使用子表达式:
(19|20)\d{2}
匹配结果
DOB:1967-08-17
7、回溯匹配
所谓回溯匹配,就是说允许正则表达式引用前面的匹配结果。
(1)回溯
例如:我们想把文本里面所有连续重复出现的单词找出来。
文本
This is a block of of text, severl words here are are repeated, and and they should not be.
正则表达式
[ ]+(\w+)[ ]+\1
结果
This is a blockof of text, severl words here are are repeated, and and they should not be.
\1是一个回溯引用,代表着模式里的第一个子表达式,那么\2就代表模式里的第2个子表达式,依次类推。
(2)替换
例如,我们想把文本段里的邮件文本替换成可以点击的超链接,那么就要用到回溯替换
文本
Hello, vicky@dut.com is my email address.
正则表达式
(\w+[\w.]*@[\w.]+\.\w+)
替换
< A HREF=”mailto:$1”>$1< /A>
8、向前查找
?= 开头的子表达式,需要匹配的文本跟在=后面,它是这样一个模式,包含的匹配本身并不返回,而是用于确定正确的匹配位置即向前查找,它并不是匹配结果的一部分
例如,要在URL地址中,提取出它们的协议名部分。
文本
http://www.vicky.com
https://mail.vicky.com
ftp://ftp.vicky.com
正则表达式
.+(?=:)
结果
http://www.vicky.com
https://mail.vicky.com
ftp://ftp.vicky.com
用?=正则表达式引擎表明,只要找到:就行了,不要把它包括在最终的匹配结果里。
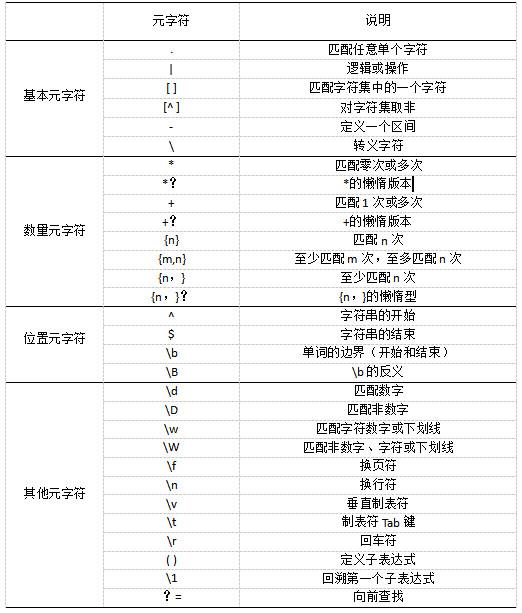
三、元字符总结
四、JavaScript的RegExp类型
创建一个正则表达式:
var pattern = /pattern/ flags
flags 包括:
g:全局模式 global,即模式被应用于所有字符串
i:不区分大小写
m:多行模式,在到达一行文本的末尾时还会继续查找下一行中是否存在与模式匹配的项
1 创建正则表达式
1)正则表达式字面量
var pattern = /.at/g ;2)RegExp构造函数
var re = new RegExp(".at","g");区别:
正则表达式字面量会始终共享一个RegExp实例,而使用构造函数创建的每一个新RegExp实例都是一个新实例。
2 RegExp实例属性
global:布尔值,表示是否设置了g标识
ignorance:布尔值,表示是否设置了i标识
lastIndex:整数,表示开始搜索下一个匹配项的字符位置,从0算起
multiline:布尔值,表示是否设置了m标识
source:正则表达式的字符串表示
3 RegExp实例方法
1)exec()
该方法是专门为捕获组而设计的,这里的捕获组其实就是子表达式。exec()接受一个参数,即要应用模式的字符串,然后返回包含第一个匹配项信息的数组。
数组的内容如下:

[匹配的第一项,index,input]
index:表示匹配项在字符串中的位置
input:表示应用正则表达式的字符串
注意:对于exec()而言,它每次只会返回一个匹配项。在不设置全局标识的情况下,在同一个字符串上多次调用exec()将始终返回第一个匹配项的信息。而在设置了全局表示的情况下,每次调用exec()都会在字符串中继续查找新的匹配项。
var text = "cat,bat,sat,fat";
var pattern1 = /.at/;
var matches = pattern1.exec(text);
console.log(matches.index);//0
console.log(matches[0]);//cat
console.log(pattern1.lastIndex);//0
var pattern2 = /.at/gi;
var matches = pattern2.exec(text);
console.log(matches.index);//0
console.log(matches[0]);//cat
console.log(pattern2.lastIndex);//3!!!!!
console.log(matches);结果:

2)test()
它接受一个字符串参数,在模式与该字符串匹配时返回true,否则返回false。在想知道目标字符串与某个模式是否匹配,但不需要知道其文本内容的情况下,使用test()很方便。test()经常被用在if语句中
var text = "000-00-0000";
var pattern = /\d{3}-\d{2}-\d{4}/;
if (pattern.test(text)) {
console.log("match!");
}; //match!4 RegExp构造函数属性
input:最近一次要匹配的字符串
lastMatch:最近一次的匹配项
lastParen:最近一次匹配的捕获组
leftContext:input字符串中最近一次匹配项前面的文本
rightContext:input字符串中最近一次匹配项后面的文本
multiline:布尔值,表示是否所有表达式都使用多行模式
以上属性Opera都不支持















 650
650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









