







文章目录
爬虫
爬虫:通过编写程序来获取互联网上的资源
举例:简单爬百度
from urllib.request import urlopen
#导入一个包
url="http://www.baidu.com"
resp=urlopen(url) #打开一个网址
# print(resp.read().decode("utf-8")) #将解码转换成字符串输出
with open("mybaidu.html",mode="w",encoding="utf-8") as f:
f.write(resp.read().decode("utf-8")) #读取到网页的页面源代码
#将爬取的内容写入文件
print("over!")
resp.close()
爬取百度数据

html文件运行后可得百度网页

哇哦,简直一模一样
一、Requests请求
注意:requests需要安装!!
安装requests:pip install requests
国内源:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
1.Web请求过程剖析
1.服务器渲染:在服务器那边直接把数据和html整合在一起,统一返回给浏览器
在页面源代码中能看到数据
2.客户端渲染:第一次请求只要一个html骨架,第二次请求拿到数据,进行数据拓展
在页面源代码中,看不到数据
2.requests请求方式
①get()
举例:1.从搜狗浏览器请求 “ XXX ” 获得查询结果
import requests
# get方式适用
query=input("请输入:")
url=f"https://www.sogou.com/web?query={query}"
dic={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
#User-Agent:设备
resp=requests.get(url,headers=dic) #获取网站源码 headers=dic实现了一个小小的反爬
print(resp) #<Response [200]>表示发送请求成功
print(resp.text) #获取页面源代码
resp.close()
获得有关 “ 黄晓明 ” 的页面源代码

2.从豆瓣电影网页爬取数据
import requests
url2="https://movie.douban.com/j/chart/top_list?"
#重新封装参数
param={
"type": 24,
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}
header={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
resp2=requests.get(url2,params=param,headers=header)
# print(resp2.text) #若无输出情况,被反爬
print(resp2.json())
resp2.close() #访问页面后要关闭请求
④post()
举例:百度翻译翻译单词
import requests
#post方式适用
url1="https://fanyi.baidu.com/sug"
og=input("请输入你要翻译的单词:")
dat={
"kw":og
}
#发送post请求,发送的数据必须放在字典中,通过data参数进行传递
resp1=requests.post(url1,data=dat)
print(resp1.json()) #resp1.json()将服务器返回的内容直接转换成python里的字典
resp1.close()

二、数据解析
数据解析方式:
①.re解析(Regular Expression):
正则表达式,一种使用表达式的方式对字符串进行匹配的语法规则
元字符:具有固定含义的特殊字符,每个元字符默认只匹配一个字符串
量词:控制元字符出现的次数
贪婪匹配:.*
惰性匹配:.*?
②.bs4解析
③.xpath解析
1.re解析:
①正则表达式
1.常用元字符

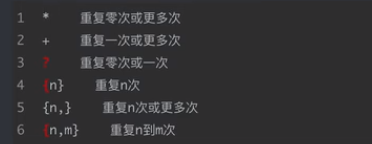
2.量词
②主要方法
1.findall:匹配字符串中所有符合正则的内容,返回的列表
lst=re.findall(r"\d+","我的电话号码是15565151,我爸爸的电话号码是13513444")
print(lst) #['15565151', '13513444']
2.finditer:匹配字符串中所有的内容,返回的是迭代器
it=re.finditer(r"\d+","我的电话号码是15565151,我爸爸的电话号码是13513444")
print(it) #<callable_iterator object at 0x000001F864685430>
for i in it:
print(i.group())
3.search:找到一个结果就返回,返回对象的结果是match对象,拿数据需要.group()
s=re.search(r"\d+","我的电话号码是15565151,我爸爸的电话号码是13513444")
print(s.group())
4.match:从头开始匹配,如果开头第一个不符合类型则报错,相当于正则表达式中的^
m=re.match(r"\d+","15565151是我的电话号码,我爸爸的电话号码是13513444")
print(m.group())
5.compile:预加载正则表达式
obj=re.compile(r"\d+")
ret=obj.findall("我的电话号码是15565151,我爸爸的电话号码是13513444")
print(ret)
ret1=obj.search("我是你爸爸1561号,1456煞笔")
print(ret1.group())
③举例
#单独获取到正则中的具体内容可以给分组起名字
#(?P<分组名字>正则) 可以单独从正则匹配内容中进一步提取内容
s = """
<div class="QQ"><span id="01">数据化</span></div>
<div class="WW"><span id="02">美化</span></div>
<div class="EE"><span id="03">可视化</span></div>
"""
obj = re.compile(r"<div class=\".*?\"><span id=\"\d+\">(?P<name>.*?)</span></div>", re.S) #re.S让.可以匹配换行符
result = obj.finditer(s)
for it in result:
print(it.group())
print(it.group("name"))
注意!!!
调用re的方法必须导入re模块
import re
三、re应用
1.手刃豆瓣top250排行
import requests
import re
import csv
url = "https://movie.douban.com/top250"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
resp = requests.get(url, headers=header)
page_content = resp.text # 页面源代码
# 解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?)'
r' .*?<span class="rating_num" property="v:average">(?P<score>.*?)'
r'</span>.*?<span>(?P<num>.*?)</span>', re.S)
# 开始匹配
result = obj.finditer(page_content)
f=open("data.csv",mode="w")
csvwrite=csv.writer(f)
for it in result:
# print(it.group("name"),"\n",it.group("year").strip(),"\n",it.group("score"),"\n",it.group("num"))
dic=it.groupdict()
dic['year']=dic['year'].strip()
csvwrite.writerow(dic.values())
#将数据写入csv文件中
f.close()
resp.close()
print("over")
csv文件存储数据

2.获取天堂电影信息
注:多重获取,爬取子网页数据
import requests
import re
domain = "https://www.dy2018.com/"
resp = requests.get(domain, verify=False) # 直接get获取不到,会报错,因为网页有防火墙
resp.encoding = "gb2312" # 指定字符集编码格式
# print(resp.text)
# 拿到ul里面的li
obj1 = re.compile(r"2021必看热片.*?<ul>(?P<ul>.*?)</ul>", re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
obj3 = re.compile(r'<br />◎片 名(?P<name>.*?)<br />.*?<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<downlaod>.*?)">', re.S)
result1 = obj1.finditer(resp.text)
child_href_list = []
for it in result1:
ul = it.group("ul")
# 提取子页面链接
result2 = obj2.finditer(ul)
for itt in result2:
# 拼接子页面的url地址 : 域名 + 子页面地址
child_href = domain + itt.group("href").strip("/") # .strip("/")表示去掉/
child_href_list.append(child_href) # 把子页面链接保存起来
# 提取子页面内容
for href in child_href_list:
child_resp = requests.get(href, verify=False)
child_resp.encoding = 'gb2312'
result3 = obj3.search(child_resp.text)
print(result3.group("name"))
print(result3.group("downlaod"))
# break # 测试用
resp.close()
运行结果存在警告信息:因为天堂电影存在防火墙及其他反爬程序
















 2802
2802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









