







代码报错:AttributeError: module 'keras.preprocessing.sequence' has no attribute 'pad_sequences'。
一、报错,如图1所示。
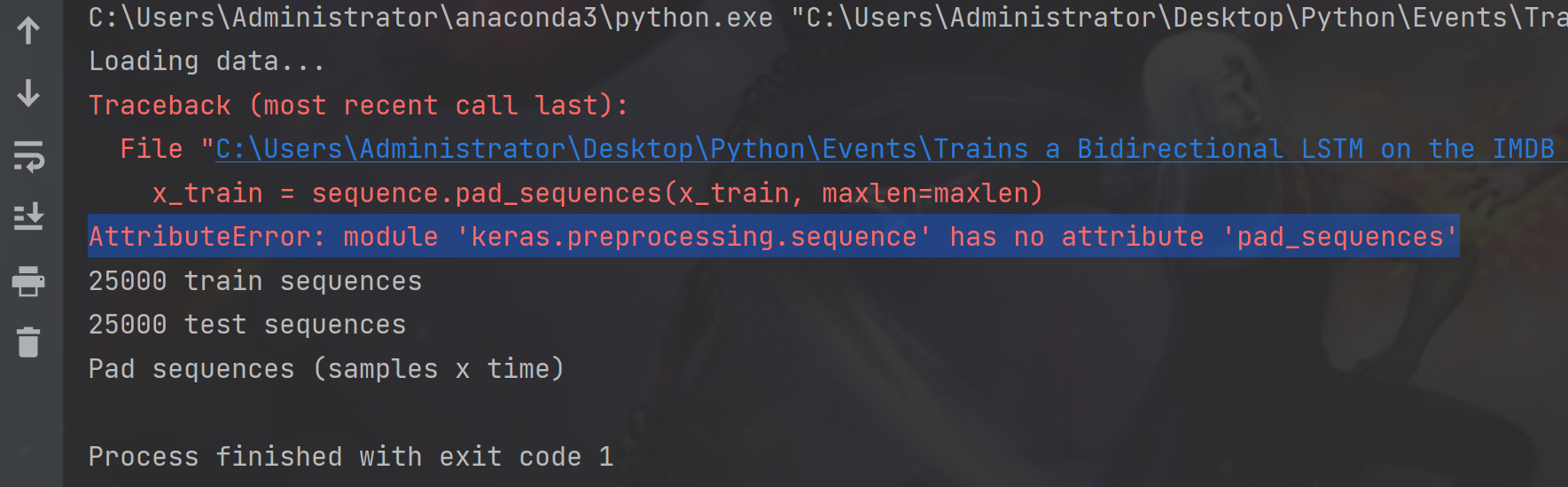
图 1
二、导入的库文件与有问题的代码块。这是问题的根源,如图2,3所示。

图 2

图 3
三、解决方法。直接将图2,3分别修改为图4,5所示就好了。

图 4

图 5
四、完整代码:
from __future__ import print_function
import numpy as np
from keras.utils import pad_sequences
from keras.models import Sequential
from keras.layers import Dense, Dropout, Embedding, LSTM, Bidirectional
from keras.datasets import imdb
max_features = 20000
# cut texts after this number of words
# (among top max_features most common words)
maxlen = 100
batch_size = 32
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)')
x_train = pad_sequences(x_train, maxlen=maxlen)
x_test = pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
y_train = np.array(y_train)
y_test = np.array(y_test)
model = Sequential()
model.add(Embedding(max_features, 128, input_length=maxlen))
model.add(Bidirectional(LSTM(64)))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
# try using different optimizers and different optimizer configs
model.compile('adam', 'binary_crossentropy', metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=4,
validation_data=[x_test, y_test])
五、如图6所示,训练了4轮次的结果。
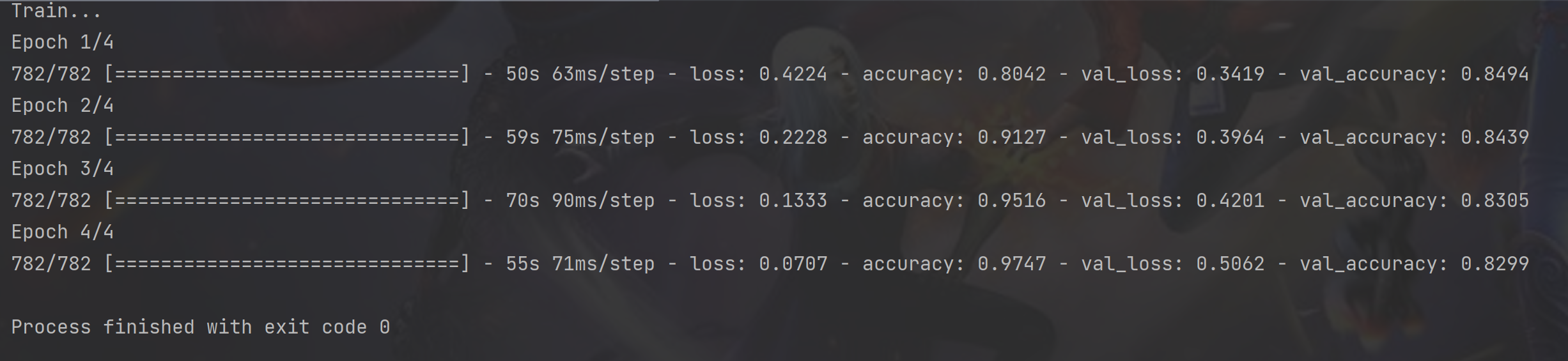
图 6














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









