







Linux基本操作与基础知识
Linux和Winodws的区别
1.Linux主要使用命令行操作系统,Windows图形化界面
2.Linux主要应用于服务器,Windows是个人操作系统
3.Linux属于开源项目,而Windows不开源
4.Linux是多用户系统,Windows是单用户系统
Linux系统的目录结构

最顶层是根目录( / )
常见目录说明
/bin存放常用命令(即二进制可执行程序)/etc存放系统配置文件/boot系统内核/dev系统设备(一切皆文件,硬件设备抽象为文件)/lib系统库文件/proc系统进程信息(内存信息的映射,虚拟的并非真是存在)/usr系统运行过程中经常改变的一些内容/var邮件、日志等/home家目录,存放用户文件/root存放管理员文件
文件类型
Linux下所以东西都可以看作是文件,Linux将文件分为以下几种类型:
普通文件: -
目录文件: d
管道文件: p
链接文件: l
设备文件: ( 块设备b,字符设备c )
套接字文件:s

d是文件类型,后面rwx rwx r-x 是文件权限,5是连接数,zyq是属主,第二个zyq是文件所属的用户组,4096是大小,后面是最后修改时间,最后是文件名字。


文件权限
r:读权限 值:4
w:写权限 值:2
x:执行权限 值:1
-:无权限 值:0
总共九个,分为三组。
最左边属主u, 中间同组g,其他人o
chmod 文字设定
chmod 数字设定法
例:
chmod u+x filename 给文件filename,属主u,加上执行权限x**
chmod u-w filename 给文件filename,属主u,减去写权限w**
chmod 764 filename 属主加7(111 rwx),同组加6(110 rw-),其他加4(100 r - -)
基本命令
pwd
显示当前位置的绝对路径

cd
切换目录,cd后的参数表示要切换到的位置,可以使用绝对路径或相对路径


ls
显示目录中的文件

touch
创建普通文件

mkdir
创建目录文件
rmdir 只能删除空文件夹
rm 删除普通文件
rm -r 可以删除文件夹

cp
文件拷贝,拷贝目录文件时,需要加上“-r”

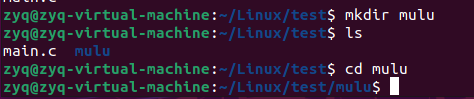
mv
移动文件 mv filename dirname
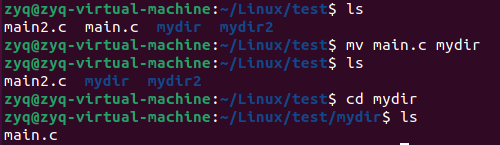
同时可以更改名字

vi vim使用
vim时vi的升级版本
vi 的三种模式:命令模式、插入模式、末行模式




文件查看命令
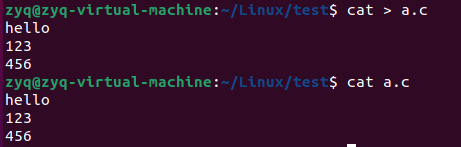
cat
适合查看内容较少的文件
可以合并文件查看

可以向文件中写入数据,停止添加按 ctrl + d
对于内容较多的文件,使用cat查看并不方便
more
适合查看内容较多的文件

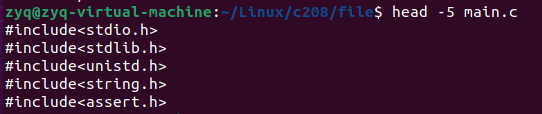
head
显示文件前十行
 添加参数可以显示任意行
添加参数可以显示任意行
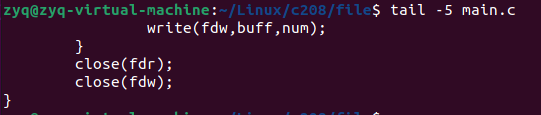
tail
显示末尾十行

同样可以根据参数显示任意末尾行
less
可以反复显示,通过方向键调整

按q退出

查找文件方法
find


在当前目录下搜索

搜索家目录下,30分钟内修改过的文件

搜索家目录下,过去一天内修改过的文件

grep 强大的文本搜索工具

grep默认区分大小写
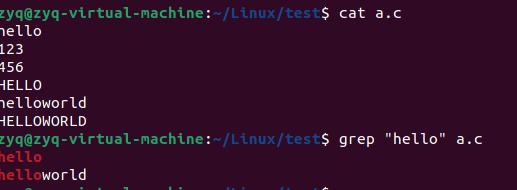
添加参数


意味满足条件的行数有两行

显示匹配到的行号
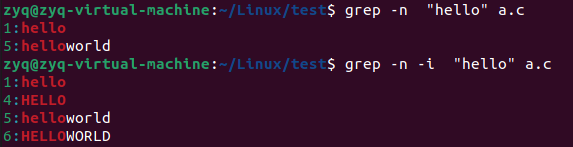
显示不包含"hello"的匹配项

进程管理命令
ps
进程是一个正在运行的程序(pid是区分进程的编号,pid最大值37268,限制值)

两次ps的pid不同,说明属于两个不同进程,而bash是同一个进程
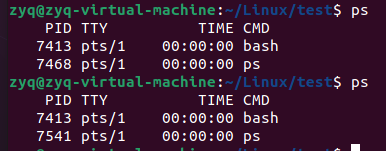
单个执行ps,默认执行当前终端的进程内容
pstree
查看系统进程树

kill




这里可以使用grep对ps -ef 的结果进行筛选(中间竖线 | 是管道,能让两个进程间进行数据传送)

有时候会出现一些情况比如,我们运行一个sleep 500 使用ctrl+z将进程停止

使用kill命令后,进程依然没有终止,这时候就要用kill -9强制进行结束

&
后台执行命令
当我们执行sleep 300时,终端会阻塞住,不能继续执行命令
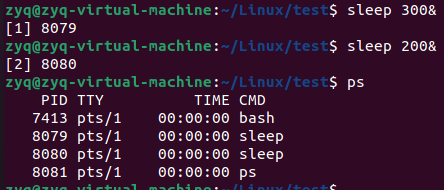
使用&可以让进程在后台进行执行
jobs
可以看到在后台执行的命令

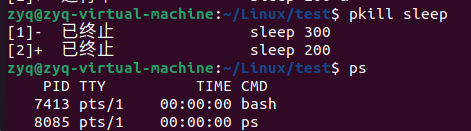
pkill
可以根据名字将所以命令全部清除
用户管理命令


添加新用户
会修改上述的文件

添加用户首先切换root管理员用户

输入 useradd username 添加用户

/etc/passwd 会出现我们新添加的信息

但没有设置密码,该用户无法登录
开始设置密码,输入 passwd username

userdel username 移除用户,但是不会删除家目录下该用户的目录

使用userdel -r username 会直接将家目录下的用户目录一并删除

文件压缩与解压命令
tar

打包
tar cvf my.tar file1.txt file2.txt file3.c
c:创建包文件
v:显示详细过程
f:制定目标为文件而不是设备

解包
tar xvf my,tar
x:释放包中内容
v:显示详细过程
f:制定目标为文件而不是设备
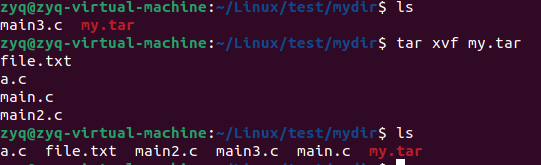
压缩
gzip my.tar

解压
gzip -d my.tar.gz
解压前大小为 310

解压后大小为10240

一步释放压缩包
tar zxf my.tar.gz

使用GCC编译程序

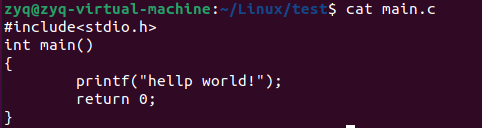
首先我们编写了一个这样的.c 文件
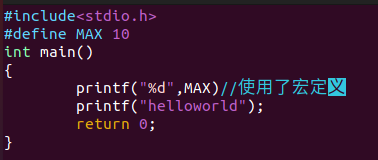
执行gcc -E main.c -o mian.i预编译

打开main.i查看

发现我们的代码在最后,并且宏定义被直接替换了,注释也不见了,而前面七百多行的文件就是我们引用的头文件
如果我们再增加一个头文件后
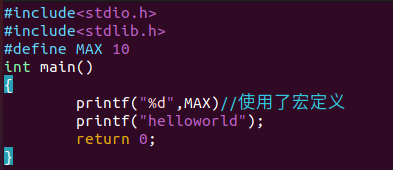
再次进行预编译,打开main.i

发现文件行数变得更多了
执行gcc -S main.i -o main.s编译

打开main.s

会发现里面变成了汇编代码,但是依然不能执行,我们继续处理
执行gcc -c main.s -o main.o 汇编


再打开mian.o 发现已经变成了二进制文件
执行gcc -o main main.o 链接

我们最终就得到了可执行文件

上面的./main 与 给出全路径 /home/zyq/Linux/test/main 是一样的
当然上面的步骤我们可以通过一步进行完成
执行gcc -o main main.c
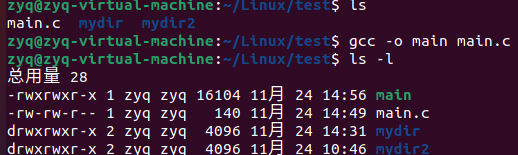
为什么要执行上面的这些过程呢,因为我们的计算机能够执行的只是二进制的机械语言,而直接编写这些语言是非常困难的,所以我们编写高级语言,通过预编译、编译、汇编、链接这些步骤一步一步将源代码变成汇编代码到可执行二进制文件

多文件编译
假设我们的main可执行程序最终是由,main.c add.c max.c 这三个文件组成

这分别是三个文件的内容
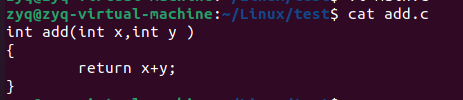
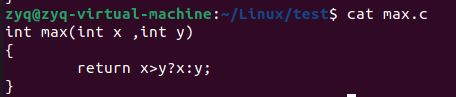

如果我们生成我们的可执行文件,我们直接去编译main.c

会提醒我们找不到add max的方法
所以我们需要将所以源文件进行编译,这里仅仅是进行了编译生成可执行二进制,而没有进行链接

最后将三个文件链接

成功生成可执行文件

同时我们也可以通过一步进行完成
执行gcc -o mian add.c main.c max.c 直接生成可执行文件

Makefile文件
makefile文件用来管理工程实现自动化编译
如果我们某一个工程,有大量的源文件需要去编译链接,仅靠我们输命令是一个繁琐复杂的方式,所以我们可以通过编写一个makefile文件再通过make命令来一步进行这个过程

自始至终的主要逻辑就是,首先我们要生产的文件,已经下面的依赖关系,已经执行命令,然后就是依赖文件的依赖关系以及执行命令

同make命令就可以一步进行编译,同时对代码的修改后重新编译会更加方便

GDB调试程序
debug与release版本的区别:
debug是调试程序版本,里面包含了调试代码的信息,release版本是发行版本,一般来讲debug版本比release版本体积更大
Linux系统中生成debug版本时,需要在编译阶段给gcc传入参数-g
Linux系统中使用gdb调试程序
GDB中常用的命令
l显示代码b加断点info break查看断点信息r运行程序n单步执行p打印内容c继续运行s进入函数finish退出函数q退出程序bt函数调用栈关系
我们现在写一段代码进行调试

我们分别使用gcc -o main main.c 和 gcc -o main main.c -g分别编出来 release 和debug版本

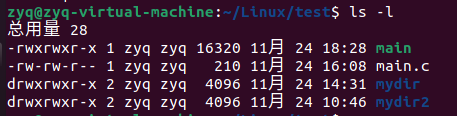
可以看到debug版本的main执行程序的更大

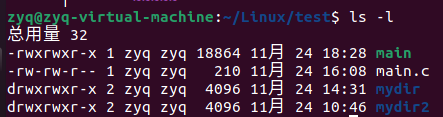
然后进行调试gdb main调试的是可执行文件

l 显示代码
b 添加断点
info break 显示断点

程序运行会停在断点处,即第八行且第八行处于未执行状态
r 执行
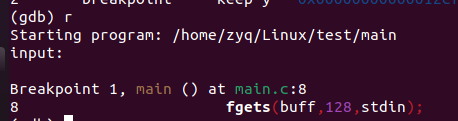
n 单步执行

单步执行后,从键盘获取字符串,这就是gdb的调试过程
我们退出调试,执行程序发现程序并没有按照我们预想的那样输入end结束,而是陷入一个死循环,我们来调试一下看看出现了上面问题

我们继续执行我们上面的调试步骤发现buff接受的数据不是end而是end\n多了一个回车符
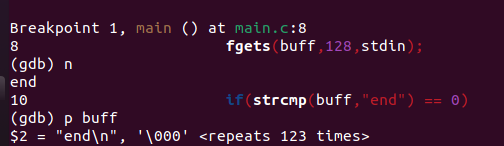
发现问题我们修改代码,再次测试

或者这样修改,用strncmp比较字符串前n个字符


代码成功运行
我们再写一段代码来练习一下gdb的其他功能

我们可以通过 b 行号来增加断点,也可以通过b 函数名来增加断电

当我们代码运行到14行 如果输入n 则会进入下一行,而按s会进入函数

输入p 打印我们需要的变量
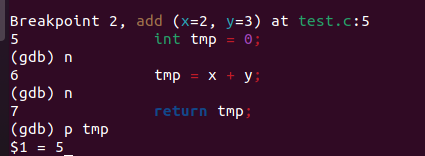
输入 bt 显示,函数的调用关系,我们当前处于 add 函数,函数执行完毕会回到main函数

输入 finish 退出函数
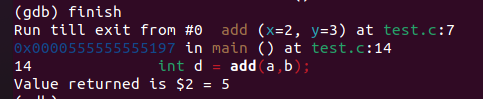
最终q退出调试

库文件
- 库是预先编译好的方法的集合
- Linux上库一般分为
libxxx.a(静态库)或libxxx.so(共享库) - 库文件常存放的地点为
/lib或者/usr/lib - 库对应的头文件一般放在
/usr/include中
库文件一般存放的不是.c代码而是编译好的二进制可执行文件
静态库
- 静态库的生成方法:
- 将所有的
.c源文件编译成目标文件.o - 将所有的目标文件打包生成静态库,如下:
arcrvlibfoo.aadd.omax.o
- 将所有的
- 静态库的使用方法:
gcc -o main main.c -L路径 -l库名
库如果在标准目录底下就不用输入-L路径
我们进入/usr/include路径下查看

里面都是一些方法的声明,我们进入stdio.h查看

会发现里面都是一些方法的声明

我们进入/usr/lib目录下查看,里面存放了很多.so共享库文件
我们现在写一个add方法和max求最大值方法加入到库中
将两个函数的源代码编译生成.o文件,加入创建的libfoo.a的库中
ar crv libfoo.a add.o max.o

我们现在新写一个函数去使用这个方法
这里我们没有一个头文件去存放声明,所以我们直接将声明写在源文件里

当我们直接进行编译时,会提醒我们add方法未定义

所以我们要链接我们事先准备好的库gcc -o main main.c -L. -lfoo
这里-L.后面的点代表当前目录,-lfoo链接我们库不需要写的libfoo.o前面的lib

这里显示编译成功,运行没有问题

这时候我们删掉原本的库,再一次执行我们的main,发现依旧是可以执行的,静态库会把我们原本方法的实现包含进可执行程序中

共享库
接着上面讲到的两个方法,首先我们生成一个共享库
gcc -shared -fPIC -o libfoo.so add.o max.o

我们直接编译原本的main依然是失败且提醒找不到add方法

我们进行链接,命令与上面静态库一致,这里就有一个问题了,加入我们有两个库,一个libfoo.a,一个libfoo.so,那我们到底连接的是哪个库呢。关于这个问题,我们的Linux系统是默认优先使用共享库的
gcc -o main main.c -L. -lfoo

我们尝试运行之后,发现并没有成功,这又是问什么呢?这是因为我们使用共享库,main程序中实际上并没有包含add方法,而之前的链接也只是对程序进行了标记,声明需要使用动态库的方法,所以运行失败是因为main程序找不到需要使用的add方法在哪里

我们使用ldd main查看该程序使用了哪些共享库

这里提示libfoo.so => not found,如果我们将libfoo.so放入到标准库目录下,就不会出现找不到的情况

再次执行main程序,执行成功

-
静态库与共享库的区别:
- 静态库会把用到的方法包含到可执行文件中,而共享库不包含,只作一个标记,然后再运行程序的时候再去动态链接。
- 共享库的好处是由于可执行程序不包含这个方法,假如有十个程序去使用这个库,静态库就要再这些程序中包含十份该方法,在磁盘中就会有十份去占用空间,当这程序都运行起来也会占用十份的内存空间,但是使用静态库的好处就是,当连接完成后就不在依赖原本的库文件。
- 另外一点共享库更方便更新、修改、升级,当对共享库中的代码进行优化后,只需要把新的库替换旧的库,再次执行程序就可以了,相对于静态库则需要将程序代码重新进行编译















 80
80











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









