






房价预测在机器学习是一个非常经典的例子,但是对于入门级选手来说,还是不能找到一个合适的入口,下面以King County的房屋销售价为例子,一步一步地分析学习入门级机器学习。
1、题目要求
从给定的房屋基本信息以及房屋销售信息等,建立一个回归模型预测房屋的销售价格。数据下载请点击数据下载,密码:mfqy
数据主要包括2014年5月至2015年5月美国King County的房屋销售价格以及房屋的基本信息。
数据分为训练数据和测试数据,分别保存在kc_train.csv和kc_test.csv两个文件中。
其中训练数据主要包括10000条记录,14个字段,主要字段说明如下:
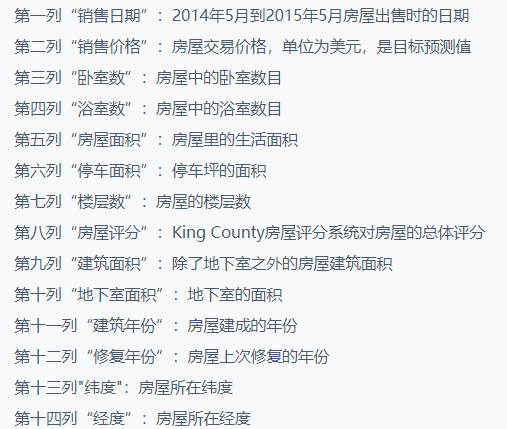 测试数据主要包括3000条记录,13个字段,跟训练数据(kc_test.csv)的不同是测试数据(kc_train.csv)并不包括房屋销售价格,需要通过由训练数据所建立的模型以及所给的测试数据,得出测试数据相应的房屋销售价格预测值。
测试数据主要包括3000条记录,13个字段,跟训练数据(kc_test.csv)的不同是测试数据(kc_train.csv)并不包括房屋销售价格,需要通过由训练数据所建立的模型以及所给的测试数据,得出测试数据相应的房屋销售价格预测值。
2、步骤
- 选择合适的模型,对模型的好坏进行评估和选择。
- 对缺失的值进行补齐操作,可以使用均值的方式补齐数据,使得准确度更高。
- 数据的取值一般跟属性有关系,但世界万物的属性是很多的,有些值小,但不代表不重要,所有为了提高预测的准确度,统一数据维度进行计算,方法有特征缩放和归一法等。
- 数据处理好之后就可以进行调用模型库进行训练了。
- 使用测试数据进行目标函数预测输出,观察结果是否符合预期。或者通过画出对比函数进行结果线条对比。
3、模型选择
这里我们选择多元线性回归模型,y表示我们要求的销售价格,x表示特征值,需要调用sklearn库来训练。
5.csv数据处理
下载的是两个数据文件,一个是真实数据,一个是测试数据,打开kc_train.csv,能够看到第二列是销售价格,而我们要预测的就是销售价格,所以在训练过程中是不需要销售价格的,把第二列删除掉,新建一个csv文件(即kc_train2.csv)存放销售价格这一列,作为后面的结果对比。
注明:以上内容来自:
作者:mantch
链接:https://www.jianshu.com/p/928b95645757
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
下面上代码块,并进行一步一步的分析:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plot
housing = pd.read_csv('kc_train.csv')
target=pd.read_csv('kc_train2.csv') #销售价格
t=pd.read_csv('kc_test.csv') #测试数据
#数据预处理
housing.info() #查看是否有缺失值
#特征缩放
from sklearn.preprocessing import MinMaxScaler
minmax_scaler=MinMaxScaler()
minmax_scaler.fit(housing) #进行内部拟合,内部参数会发生变化
scaler_housing=minmax_scaler.transform(housing)
scaler_housing=pd.DataFrame(scaler_housing,columns=housing.columns)
mm=MinMaxScaler()
mm.fit(t)
scaler_t=mm.transform(t)
scaler_t=pd.DataFrame(scaler_t,columns=t.columns)
#选择基于梯度下降的线性回归模型
from sklearn.linear_model import LinearRegression
LR_reg=LinearRegression()
#进行拟合
LR_reg.fit(scaler_housing,target)
#使用均方误差用于评价模型好坏
from sklearn.metrics import mean_squared_error
preds=LR_reg.predict(scaler_housing) #输入数据进行预测得到结果
mse=mean_squared_error(preds,target) #使用均方误差来评价模型好坏,可以输出mse进行查看评价值
#绘图进行比较
plot.figure(figsize=(10,7)) #画布大小
num=100
x=np.arange(1,num+1) #取100个点进行比较
plot.plot(x,target[:num],label='target') #目标取值
plot.plot(x,preds[:num],label='preds') #预测取值
plot.legend(loc='upper left') #线条显示位置
plot.show()
#输出测试数据
result=LR_reg.predict(scaler_t)
df_result=pd.DataFrame(result)
df_result.to_csv("result.csv")
- 首先导入numpy库,pandas库,matplotlib(用于最后的画图进行分析比较)。
- 将三个文件放在和这个程序同级的地方,分别将他们的数据赋值给housing(训练数据,包括各个数据的特征值),target(实际销售价格),t(测试数据的特征值)
pandas.read_csv可以读取CSV(逗号分割)文件、文本类型的文件text、log类型到DataFrame。官方文档给出的参数较多,这里只说明一下路径,即read_csv(filepath_or_buffer)。
filepath_or_buffer 就是要读取文件的路径,要么是一个文件的路径(a str, pathlib.Path,or py._path.local.LocalPath), URL (including http, ftp,
and S3 locations), 或者是任何有read()方法的对象 (e.g. an open file or StringIO).
- 下面进行数据的预处理,调用info函数,结果如下图

由于原来的数据并没有提供表头,所以用了第一行的每一列数据分别做索引,即20150302,3,2.25…共13列,每一列都有9999行非空值,判断是否有空值,输出non-null,即是不存在缺失值,输出的第四列为该列数据的类型。dtypes表示数据出现了哪些类型,memory usage表示占用内存情况。
info()给出样本数据housing的相关信息概览:包括行数(RangeIndex),列数(Data to columns),列索引,列非空值个数,列类型(dtypes),内存占用(memory usagr),
DataFrame.info(verbose=None, memory_usage=True, null_counts=True)
verbose:默认为None,如果DataFrame有很多列,是否显示所有列的信息,如果为否,那么会省略一部分;
memory_usage:默认为True,是否查看DataFrame的内存使用情况;
null_counts:默认为True,是否统计NaN值的个数。
- 下面进行特征放缩来统一数据维度,从sklearn库中导入MinMaxScaler来实现
from sklearn.preprocessing import MinMaxScaler
MinMaxScaler将属性的范围缩放到指定的最大值和最小值之间,使用的公式是
使用这种方法的目的是:
1、对于方差非常小的属性可以增强其稳定性。
2、维持稀疏矩阵中为0的条目。
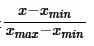
- sklearn里的各种封装好的算法使用前都要fit(),fit相对于整个代码而言,为后续的API服务,fit之后,然后调用各种API方法,transform只是其中一个API方法,所以当你调用transform之外的方法,也必须要先fit。fit()简单来说就是求训练集X的均值,方差,最大最小值这些训练集固有的属性,然后transform()是在fit的基础上进行标准化/降维/归一化等等操作(看具体使用的什么工具)。使用housing来进行fit和transform是为了进行内部拟合,内部的参数会发生变化,再形成DataFrame。
- 同理,得到scaler_housing和scaler_t两个拟合后的DataFrame。
from sklearn.linear_model import LinearRefression从sklearn中导入LinearRegression线性回归,建立好基于梯度下降的线性回归模型进行拟合,参数为scaler_housing和target,则是样本的特征值和真实结果来拟合模型- 再通过这个模型来预测得到结果
LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=None)
fit_intercept:默认为True,表示是否有截距,如果没有截距则过原点;
normalize:默认为False,表示是否将数据归一化;
copy_X:默认为True,当为True时,X会被copied,否则X将会被覆写;
n_jobs:默认值为1,表示计算时使用的核数。
fit(X,y,sample_weight=None)训练模型:
X: array, 稀疏矩阵 [n_samples,n_features]
y: array [n_samples, n_targets]
sample_weight: 权重 array [n_samples]
- from sklearn,metrics import mean_sqared_error,计算均方误差回归损失来评价模型的好坏(可以输出mse查看评价值)
sklearn.metrics.mean_squared_error(y_true, y_pred, sample_weight=None, multioutput=’uniform_average’)
y_true表示真实值;
y_pred表示预测值;
sample_weight表示样本的权重
多维输入输出,默认为’uniform_average’,计算所有元素的均方误差,返回为一个标量;也可选‘raw_values’,计算对应列的均方误差,返回一个与列数相等的一维数组。
-
绘图来进行比较。确定画布的大小figsize=(10,7),np.arrange(1, 101)表示取100个点(因为终点值取不到)
-
将目标取值的label定为‘target’,预测取值定为‘preds’
-
plot.legend(loc = ‘upper left’)表示图例的位置在左上方。
-
使用测试数据进行目标函数预测输出,观察结果是否符合预期,preds是将test数据使用用训练数据拟合出来的模型得到的预测值,与实际的价格(即kc_train2中的销售价格)进行比较。并且将输出测试数据result,生成dataframe保存在result.csv中。
比较图结果如下:
一个很基础的线性回归模型就这样完成啦,第一次写博客有很多不熟悉的地方,冲!















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









