







Pytorch网络模型的训练
网络模型训练是指使用数据对机器学习或深度学习模型进行优化的过程。这个过程的主要目标是通过调整模型的参数,使其能够更好地预测或分类新的、未见过的数据。简而言之,网络模型训练的过程是使用数据集对模型进行优化,使其能够识别模式、学习规律,从而在面对新数据时能够做出准确的预测或分类。
下面使用CIFAR10数据集来训练一个分类模型:
1. 数据准备
首先,我们需要准备数据集。CIFAR-10 是一个常用的图像分类数据集,包含 10 类彩色图片,每类包含 6000 张图片。训练集有 50000 张图像,测试集有 10000 张图像。
我们可以通过 torchvision 库来方便地下载并加载 CIFAR-10 数据集。
import torchvision
from torch.utils.data import DataLoader
# 下载并加载训练集和测试集
train_data = torchvision.datasets.CIFAR10('data', train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10('data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 查看数据集的大小
print(f"训练集大小:{len(train_data)}") # 50000
print(f"测试集大小:{len(test_data)}") # 10000
我们通过 torchvision.transforms.ToTensor() 将图像数据转换为 PyTorch 张量,方便输入到神经网络中。同时,数据集会自动下载到指定的 'data' 目录。
接下来,我们将数据加载器 (DataLoader) 用于批量加载训练和测试数据。
train_loader = DataLoader(train_data, batch_size=64)
test_loader = DataLoader(test_data, batch_size=64)
通过 DataLoader,我们可以按批次加载数据,设定每个批次包含 64 张图片。
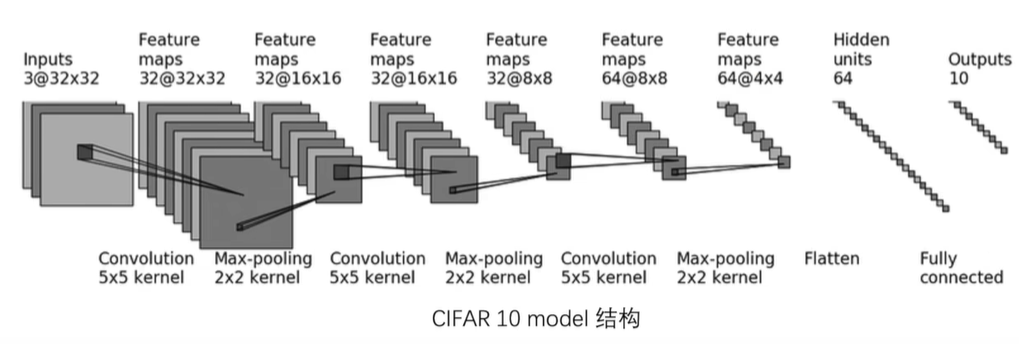
2. 构建神经网络模型
为了进行 CIFAR-10 图像分类任务,我们需要构建一个适合该任务的神经网络模型。模型的设计可以根据需求进行调整。这里我们已有一个名为 CIFAR10NN 的神经网络模型,该模型适用于 CIFAR-10 分类任务。
import torch
from torch import nn
# CIFAR10网络模型
class CIFAR10NN(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=64 * 4 * 4, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, input):
return self.model(input)
# 测试该网络模型
if __name__ == '__main__':
input = torch.zeros(size=(64, 3, 32, 32))
model = CIFAR10NN()
res = model(input)
print(res.shape)
我们通过从 model.py 文件导入该模型。
from model import CIFAR10NN
# 初始化模型
net = CIFAR10NN()
3. 定义损失函数和优化器
在训练神经网络时,我们需要定义损失函数和优化器。损失函数用于衡量模型预测与实际标签之间的误差,而优化器则用于更新模型参数,以最小化损失函数。
对于分类任务,常用的损失函数是 CrossEntropyLoss,它能够处理多分类问题。我们使用 SGD(随机梯度下降)作为优化器。
import torch.nn as nn
# 定义损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
learning_rate = 0.01
optim = torch.optim.SGD(params=net.parameters(), lr=learning_rate)
这里设置了学习率为 0.01,您可以根据需要调整它。
4. 设置训练参数
我们还需要设置一些训练过程中的超参数,如训练轮数、训练步数和测试步数。
train_step = 0 # 记录训练步数
test_step = 0 # 记录测试步数
epoch = 5 # 总训练轮数
我们设定训练模型 5 轮。您可以根据实际情况增加或减少训练轮数。
5. 开始训练模型
在训练过程中,我们需要迭代数据集,并通过前向传播计算输出,然后根据输出与实际标签之间的差距计算损失。接下来,通过反向传播计算梯度,并使用优化器更新模型参数。
for i in range(epoch):
print(f"*****第{i+1}轮训练开始*****")
# 训练模式
net.train()
for data in train_loader:
imgs, targets = data
outputs = net(imgs) # 前向传播
res_loss = loss_fn(outputs, targets) # 计算损失值
# 优化器优化模型
optim.zero_grad() # 清空梯度
res_loss.backward() # 反向传播计算梯度
optim.step() # 更新参数
train_step += 1
if train_step % 100 == 0:
print(f"训练次数:{train_step}, Loss:{res_loss.item()}") # 输出损失值
在每一轮训练中,我们将模型设置为训练模式(net.train())。然后,通过遍历训练集,进行前向传播和反向传播,计算损失并更新模型参数。
我们每 100 次训练步骤输出一次当前的损失值(Loss),以便观察模型的训练情况。
6. 在测试集上评估模型
每训练一轮后,我们会在测试集上验证模型的效果。由于在测试阶段我们不需要计算梯度,因此使用 torch.no_grad() 来禁用梯度计算,以节省内存并提高计算速度。
total_loss = 0
with torch.no_grad(): # 不进行梯度计算
for data in test_loader:
imgs, targets = data
outputs = net(imgs)
res_loss = loss_fn(outputs, targets)
total_loss += res_loss
print(f"整体测试集上的Loss:{total_loss}")
在测试阶段,我们通过模型进行预测,并计算所有测试样本的总损失。通过输出总损失值来评估模型的性能。
7.将训练的模型进行可视化操作
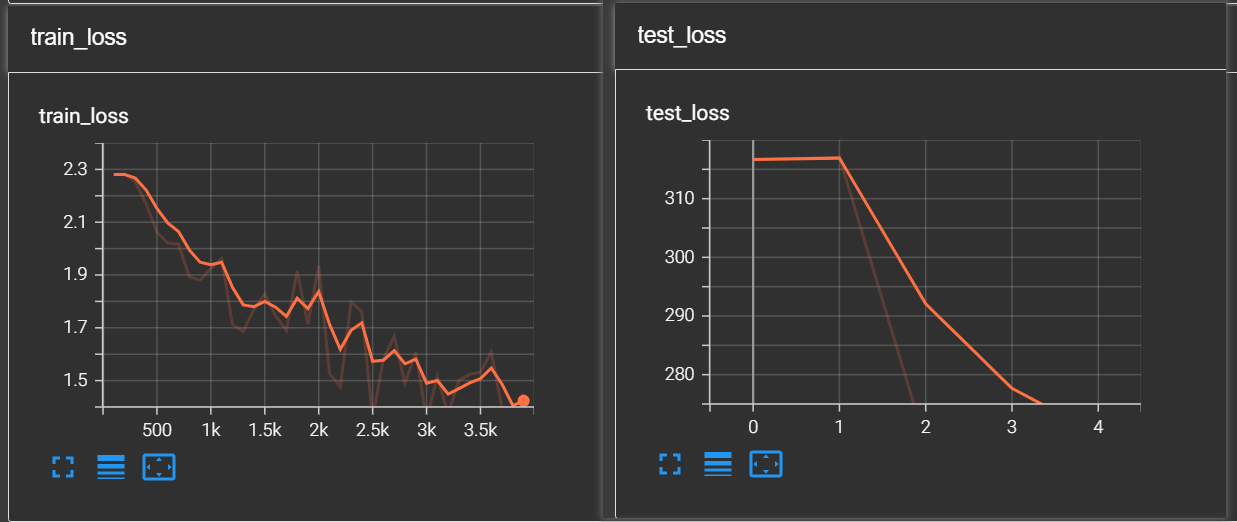
在训练过程中使用 TensorBoard 进行可视化是非常常见的做法,TensorBoard 能帮助我们直观地查看训练损失、测试损失等指标的变化趋势。你已经通过 SummaryWriter 完成了基本的记录步骤,在训练过程中我们会把 train_loss 和 test_loss 添加到 TensorBoard 中。接下来,我们将详细讲解如何在 TensorBoard 中查看这些数据,并如何进一步增强可视化效果。
在训练过程中,使用 writer.add_scalar() 记录每 100 次训练的损失:
writer.add_scalar('train_loss', res_loss.item(), train_step)
这里,train_loss 是标签,res_loss.item() 是记录的数值,train_step 是当前训练步数,TensorBoard 将会按照训练步数绘制损失曲线。
在每轮训练结束后,记录并保存测试集上的损失:
writer.add_scalar('test_loss', total_loss, test_step)
这里,test_loss 是标签,total_loss 是当前测试集上的损失,test_step 是当前测试步数,TensorBoard 会展示每轮训练后模型在测试集上的表现。
8.完整的代码
import torch
import torchvision
from model import *
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 1. 准备数据集
train_data = torchvision.datasets.CIFAR10('data', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10('data', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
print(f"训练集大小:{len(train_data)}") # 查看训练集的大小:50000
print(f"测试集大小:{len(test_data)}") # 查看测试集的大小:10000
# 2.加载数据集
train_loader = DataLoader(train_data, batch_size=64)
test_loader = DataLoader(test_data, batch_size=64)
# 3.搭建神经网络
# 导入搭建的网络 from model import *
net = CIFAR10NN()
# 4.定义损失函数
loss_fn = nn.CrossEntropyLoss()
# 5.定义优化器
learning_rate = 0.01
optim = torch.optim.SGD(params=net.parameters(), lr=learning_rate)
# 6.设置训练网络的一些参数
train_step = 0 #记录训练的次数
test_step = 0 #记录测试的次数
epoch = 5 #训练的总轮数
# 7.可视化
writer = SummaryWriter('logs')
# 8.开始训练
for i in range(epoch):
print(f"*****第{i+1}轮训练开始*****")
# 通过训练并优化模型
net.train() # 设置模型为训练模式
for data in train_loader: # 迭代 train_loader,而不是 train_data
imgs, targets = data
outputs = net(imgs) # 前向传播
res_loss = loss_fn(outputs, targets) # 求解损失值
# 优化器优化模型
optim.zero_grad() # 清空梯度
res_loss.backward() # 反向传播
optim.step() # 更新参数
train_step += 1
if train_step % 100 == 0:
print(f"训练次数:{train_step}, Loss:{res_loss.item()}") # 输出损失值
writer.add_scalar('train_loss', res_loss.item(), train_step)
# 在测试集上验证模型的效果
total_loss = 0
with torch.no_grad():# 为了使得在测试集上不进行调优,因此不设置梯度
for data in test_loader:
imgs, targets = data
outputs = net(imgs)
res_loss = loss_fn(outputs, targets)
total_loss += res_loss
# 检测模型结构并可视化
print(f"整体测试集上的Loss:{total_loss}")
writer.add_scalar('test_loss', total_loss, test_step)
test_step += 1
#保存模型
torch.save(net.state_dict(), f'CIFAR10_Model{i}.pth')
print("模型已保存")
writer.close()
9.注意事项
值得注意的是,并非在训练之前都要使用torch.train(),测试时使用torch.eval(),只有网络中含有特定的层时才有作用。

10.GPU对模型的训练
GPU 之所以能加速深度学习训练,是因为它擅长并行计算。深度神经网络、卷积、矩阵乘法等操作都可以并行化,而 GPU 拥有数千个计算核心,能够同时处理大量的计算任务。这使得训练深度学习模型比 CPU 更加高效,尤其是对于大规模数据集和复杂模型。
GPU 主要用于训练涉及大量矩阵运算、数据并行处理的机器学习和深度学习模型,特别是深度神经网络(如 CNN、RNN、Transformer 等)、强化学习、大规模数据集处理等任务。
在 PyTorch 中,cuda() 可以用于以下对象:
- 张量(Tensor)
- 模型(Model)
- 数据批次(在 DataLoader 中的每个 batch)
- 损失函数输入(如模型的输出和标签)
下面是使用GPU训练的两种方式
- 方式一:
# 对模型进行训练
if torch.cuda.is_available():
net = net.cuda()
# 对损失函数输入进行训练
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 对输入数据进行训练
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
- 方式二:
# 1.设置设备 (GPU / CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 2. 初始化模型
net = CIFAR10NN().to(device)
# 3.定义损失函数
loss_fn = nn.CrossEntropyLoss().to(device)
# 4.训练模式
net.train()
for data in train_loader:
imgs, targets = data
imgs, targets = imgs.to(device), targets.to(device) # 将数据移到 GPU 或 CPU
Pytorch模型验证

from model import *
import torchvision.transforms
from PIL import Image
# 1.加载图片
img = Image.open("data/plane.png")
# 2.设置输入数据
transforms_compose = torchvision.transforms.Compose(
[torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()])
img = transforms_compose(img)
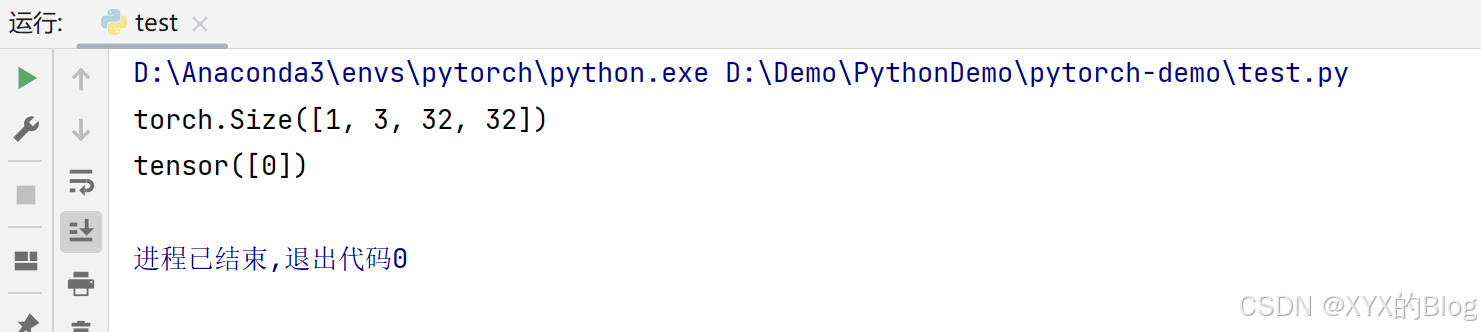
input = torch.reshape(img, (1, 3, 32, 32))
print(input.shape)
# 3.加载模型
net = CIFAR10NN()
net.load_state_dict(torch.load("model/CIFAR10_Model4.pth"))
# 4.测试模型
net.eval()
with torch.no_grad():
output = net(input)
print(output.argmax(1))


















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









