







本文的网课内容学习自B站左程云老师的算法详解课程,旨在对其中的知识进行整理和分享~
一.利用前缀和快速得到区域累加和
题目:区域和检索 - 数组不可变

算法原理
-
整体原理
- 整体思路是通过预先计算数组的前缀和,从而能够快速获取任意区间的累加和。利用了前缀和的特性,避免了每次计算区间和时都对区间内的元素逐个相加,提高了计算效率。
-
具体步骤
- 前缀和数组构建步骤
- 在
NumArray类的构造函数中,创建一个长度为nums.length + 1的sum数组。 - 初始化一个循环,循环变量
i从1开始,到nums.length结束。这是因为sum数组的第0个元素未使用(方便计算,避免处理边界情况时额外的判断)。 - 在每次循环中,根据递推公式
sum[i]=sum[i - 1]+nums[i - 1]计算sum数组的值。例如,当i = 1时,sum[1]=nums[0];当i = 2时,sum[2]=sum[1]+nums[1],也就是前一个前缀和加上当前位置的nums数组元素。
- 在
- 计算区域累加和步骤
- 在
sumRange方法中,接收两个参数left和right,表示要计算累加和的区间。 - 根据前缀和的计算逻辑,直接返回
sum[right + 1]-sum[left]。这里sum[right + 1]表示从nums数组的第0个元素到第right个元素的累加和,sum[left]表示从nums数组的第0个元素到第left - 1个元素的累加和,两者相减就得到了区间[left, right]的累加和。例如,若要计算nums数组中索引为1到3(假设索引从0开始)的区间累加和,left = 1,right = 3,那么sum[right + 1]就是从第0个元素到第3个元素的累加和,sum[left]就是从第0个元素到第0个元素的累加和,两者相减得到索引为1到3的元素累加和。
- 在
- 前缀和数组构建步骤
代码实现
// 利用前缀和快速得到区域累加和
// 测试链接 : https://leetcode.cn/problems/range-sum-query-immutable/
public class Code01_PrefixSumArray {
class NumArray {
public int[] sum;
public NumArray(int[] nums) {
sum = new int[nums.length + 1];
for (int i = 1; i <= nums.length; i++) {
sum[i] = sum[i - 1] + nums[i - 1];
}
}
public int sumRange(int left, int right) {
return sum[right + 1] - sum[left];
}
}
}二.未排序数组中累加和为给定值的最长子数组长度
题目:未排序数组中累加和为给定值的最长子数组长度
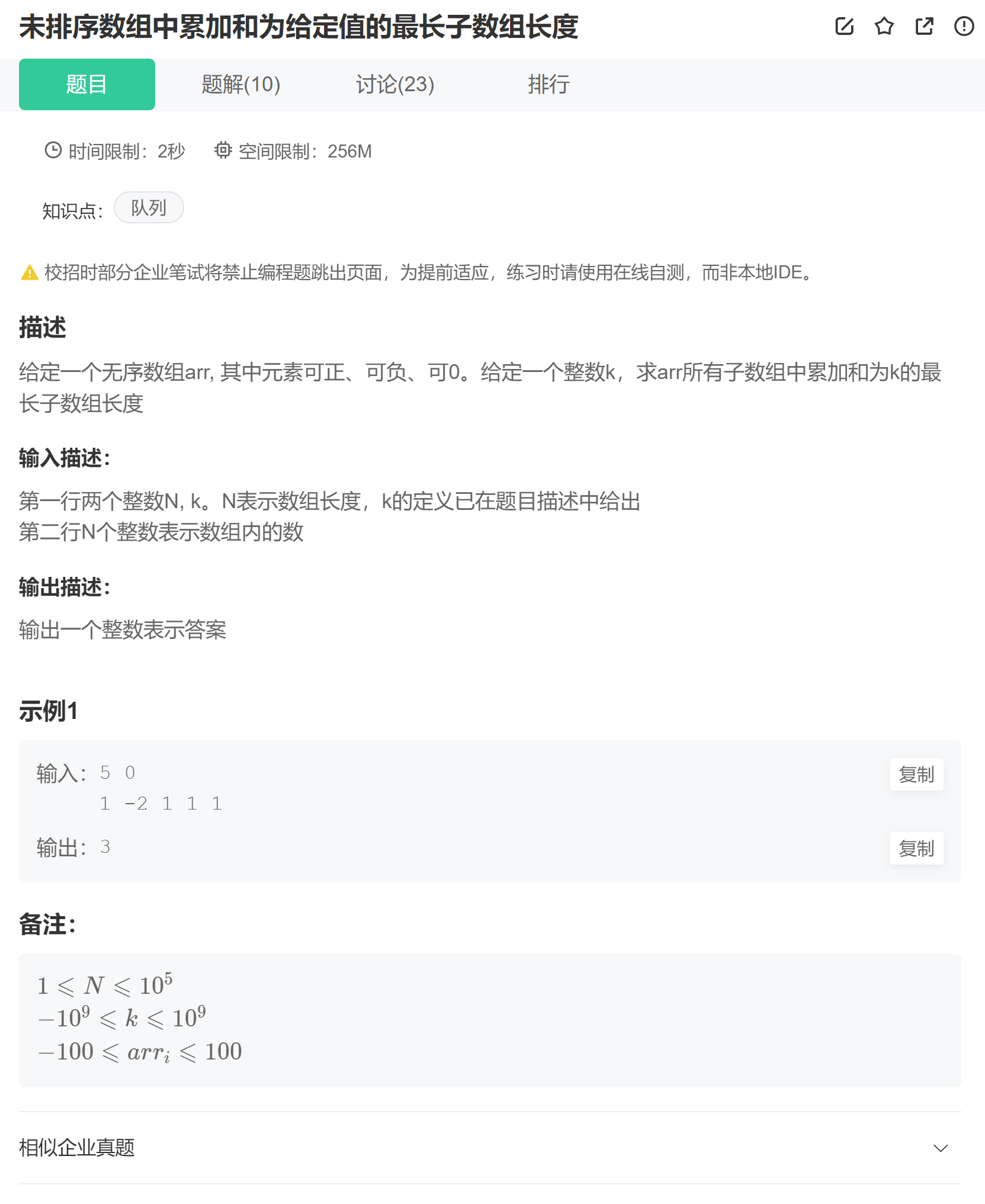
算法原理
-
整体原理
- 这个算法主要是利用前缀和以及哈希表来解决求累加和为给定值的最长子数组长度的问题。通过记录前缀和以及其首次出现的位置,在遍历数组的过程中,计算当前前缀和与目标值
aim的差值,若这个差值对应的前缀和在哈希表中存在,就说明存在一个子数组的累加和为aim,然后计算这个子数组的长度并更新最长子数组长度。
- 这个算法主要是利用前缀和以及哈希表来解决求累加和为给定值的最长子数组长度的问题。通过记录前缀和以及其首次出现的位置,在遍历数组的过程中,计算当前前缀和与目标值
-
具体步骤
- 初始化
- 创建一个
HashMap,其中key为某个前缀和,value为这个前缀和最早出现的位置。将数组arr的最大长度设为MAXN = 100001,并初始化arr数组。 - 在
compute方法中,首先清空map(这是为了处理多组测试数据),并将前缀和为0(表示一个数字也没有的时候)的位置设为- 1,初始化最长子数组长度ans = 0。
- 创建一个
- 遍历数组计算前缀和并更新结果
- 使用
for循环遍历数组arr,在循环中,计算当前位置i的前缀和sum(通过不断累加arr[i])。 - 计算当前前缀和
sum与目标值aim的差值sum - aim,如果map中包含这个差值,说明存在一个子数组的累加和为aim。此时计算这个子数组的长度i - map.get(sum - aim),并通过ans = Math.max(ans, i - map.get(sum - aim))更新最长子数组长度。 - 如果当前前缀和
sum不在map中,将其加入map中,map.put(sum, i),记录这个前缀和首次出现的位置为i。
- 使用
- 返回结果
- 最后,
compute方法返回ans,即累加和为aim的最长子数组长度。
- 最后,
- 初始化
代码实现
// 返回无序数组中累加和为给定值的最长子数组长度
// 给定一个无序数组arr, 其中元素可正、可负、可0
// 给定一个整数aim
// 求arr所有子数组中累加和为aim的最长子数组长度
// 测试链接 : https://www.nowcoder.com/practice/36fb0fd3c656480c92b569258a1223d5
// 请同学们务必参考如下代码中关于输入、输出的处理
// 这是输入输出处理效率很高的写法
// 提交以下的code,提交时请把类名改成"Main",可以直接通过
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.io.StreamTokenizer;
import java.util.HashMap;
public class Code02_LongestSubarraySumEqualsAim {
public static int MAXN = 100001;
public static int[] arr = new int[MAXN];
public static int n, aim;
// key : 某个前缀和
// value : 这个前缀和最早出现的位置
public static HashMap<Integer, Integer> map = new HashMap<>();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StreamTokenizer in = new StreamTokenizer(br);
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
while (in.nextToken() != StreamTokenizer.TT_EOF) {
n = (int) in.nval;
in.nextToken();
aim = (int) in.nval;
for (int i = 0; i < n; i++) {
in.nextToken();
arr[i] = (int) in.nval;
}
out.println(compute());
}
out.flush();
out.close();
br.close();
}
public static int compute() {
map.clear();
// 重要 : 0这个前缀和,一个数字也没有的时候,就存在了
map.put(0, -1);
int ans = 0;
for (int i = 0, sum = 0; i < n; i++) {
sum += arr[i];
if (map.containsKey(sum - aim)) {
ans = Math.max(ans, i - map.get(sum - aim));
}
if (!map.containsKey(sum)) {
map.put(sum, i);
}
}
return ans;
}
}三.和为K的子数组
题目: 和为 K 的子数组

算法原理
-
整体原理
- 这个算法利用前缀和与哈希表来统计无序数组中累加和为给定值的子数组个数。通过记录前缀和出现的次数,在遍历数组计算当前前缀和时,查找当前前缀和与目标值
aim的差值在前缀和记录中的出现次数,将这些次数累加起来就得到累加和为aim的子数组个数。
- 这个算法利用前缀和与哈希表来统计无序数组中累加和为给定值的子数组个数。通过记录前缀和出现的次数,在遍历数组计算当前前缀和时,查找当前前缀和与目标值
-
具体步骤
- 初始化
- 创建一个
HashMap来存储前缀和及其出现的次数。首先将前缀和为0(表示还没有任何数字的时候)的出现次数设为1,因为这是一种初始状态。同时初始化结果变量ans = 0,用于存储累加和为aim的子数组个数。
- 创建一个
- 遍历数组计算前缀和并更新结果
- 使用
for循环遍历数组nums,在循环中,使用sum变量来计算从0到i的前缀和(通过不断累加nums[i])。 - 计算当前前缀和
sum与目标值aim的差值sum - aim,然后通过map.getOrDefault(sum - aim, 0)获取这个差值在前缀和记录中的出现次数,并将这个次数累加到ans中。这是因为如果sum - aim存在于map中,说明存在一些子数组的累加和为aim,其个数就是sum - aim这个前缀和出现的次数。 - 接着,更新当前前缀和
sum在map中的出现次数,通过map.put(sum, map.getOrDefault(sum, 0)+1),如果sum已经在map中,就将其出现次数加1,否则将其加入map中并设置出现次数为1。
- 使用
- 返回结果
- 最后,循环结束后,返回
ans,即累加和为aim的子数组个数。
- 最后,循环结束后,返回
- 初始化
代码实现
import java.util.HashMap;
// 返回无序数组中累加和为给定值的子数组个数
// 测试链接 : https://leetcode.cn/problems/subarray-sum-equals-k/
public class Code03_NumberOfSubarraySumEqualsAim {
public static int subarraySum(int[] nums, int aim) {
HashMap<Integer, Integer> map = new HashMap<>();
// 0这个前缀和,在没有任何数字的时候,已经有1次了
map.put(0, 1);
int ans = 0;
for (int i = 0, sum = 0; i < nums.length; i++) {
// sum : 0...i前缀和
sum += nums[i];
ans += map.getOrDefault(sum - aim, 0);
map.put(sum, map.getOrDefault(sum, 0) + 1);
}
return ans;
}
}四.未排序数组中累加和为给定值的最长子数组系列问题补1
题目:未排序数组中累加和为给定值的最长子数组系列问题补1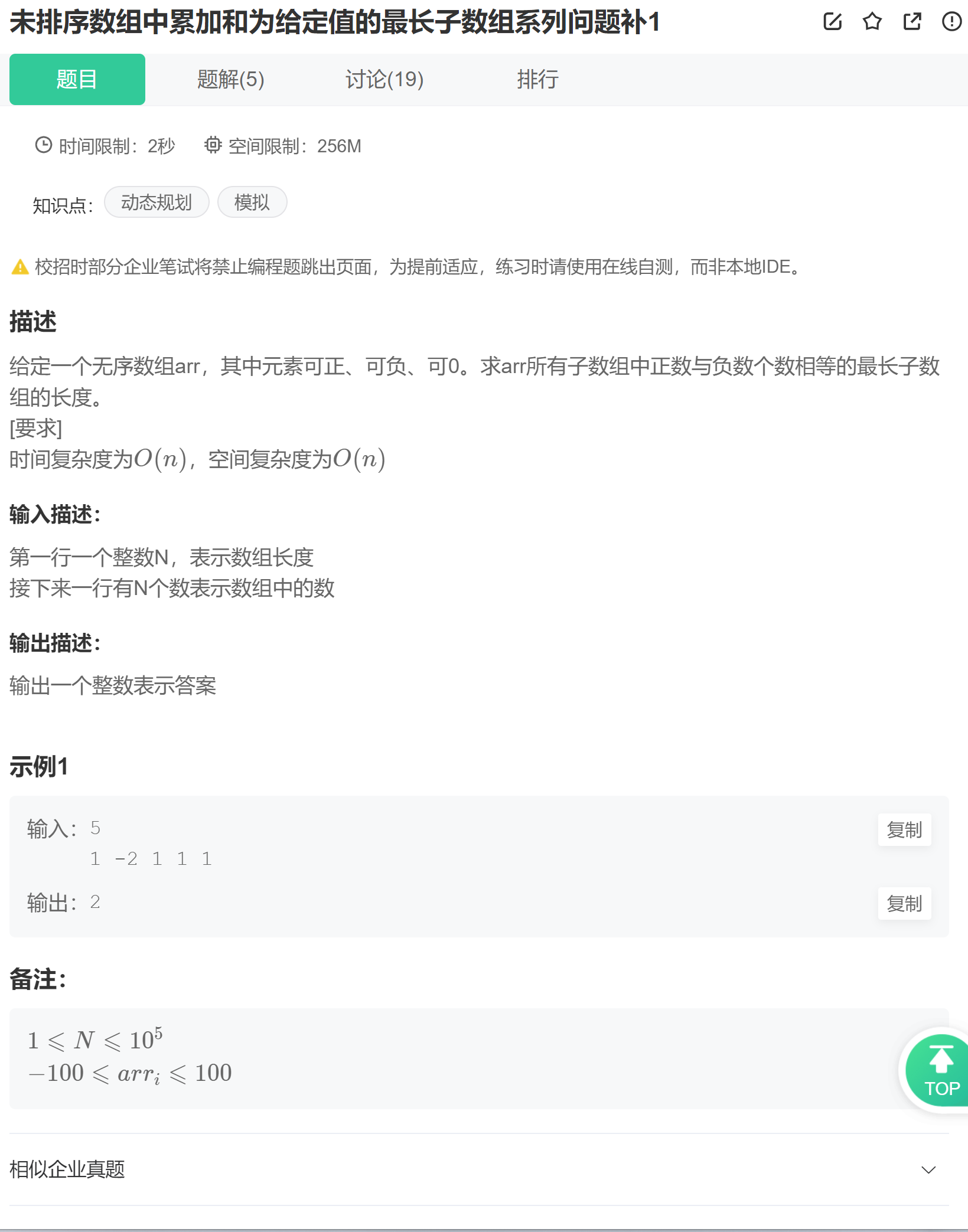
算法原理
-
整体原理
- 该算法旨在找出无序数组中正数和负数个数相等的最长子数组长度。通过将数组中的正数转换为1,负数转换为 - 1,0保持不变,然后计算前缀和。利用哈希表记录前缀和首次出现的位置,当再次出现相同的前缀和时,就意味着在这两个位置之间的子数组中正数和负数的个数相等,通过不断更新最长子数组长度来得到最终结果。
-
具体步骤
- 初始化
- 定义数组
arr的最大长度MAXN = 100001,并初始化arr数组。创建一个HashMap用于存储前缀和及其首次出现的位置。在compute方法中,先清空map(用于处理多组测试数据),并将前缀和为0的位置设为 - 1(表示还没有任何元素时的状态),初始化最长子数组长度ans = 0。
- 定义数组
- 处理输入数据
- 在
main方法中,通过BufferedReader和StreamTokenizer读取输入数据。将输入的每个数num进行转换,如果num不等于0,当num > 0时将其转换为1,当num < 0时将其转换为 - 1,然后存储到arr数组中。
- 在
- 遍历数组计算前缀和并更新结果
- 在
compute方法中,使用for循环遍历数组arr。在循环中,计算当前位置i的前缀和sum(通过不断累加arr[i])。 - 如果
map中包含当前前缀和sum,说明在之前已经出现过相同的前缀和,那么在这两个位置之间的子数组中正数和负数的个数相等。计算这个子数组的长度i - map.get(sum),并通过ans = Math.max(ans, i - map.get(sum))更新最长子数组长度。 - 如果
map不包含当前前缀和sum,则将sum及其当前位置i添加到map中,即map.put(sum, i)。
- 在
- 返回结果
- 最后,
compute方法返回ans,即正数和负数个数相等的最长子数组长度。
- 最后,
- 初始化
代码实现
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.io.StreamTokenizer;
import java.util.HashMap;
// 返回无序数组中正数和负数个数相等的最长子数组长度
// 给定一个无序数组arr,其中元素可正、可负、可0
// 求arr所有子数组中正数与负数个数相等的最长子数组的长度
// 测试链接 : https://www.nowcoder.com/practice/545544c060804eceaed0bb84fcd992fb
// 请同学们务必参考如下代码中关于输入、输出的处理
// 这是输入输出处理效率很高的写法
// 提交以下的code,提交时请把类名改成"Main",可以直接通过
public class Code04_PositivesEqualsNegtivesLongestSubarray {
public static int MAXN = 100001;
public static int[] arr = new int[MAXN];
public static int n;
public static HashMap<Integer, Integer> map = new HashMap<>();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StreamTokenizer in = new StreamTokenizer(br);
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
while (in.nextToken() != StreamTokenizer.TT_EOF) {
n = (int) in.nval;
for (int i = 0, num; i < n; i++) {
in.nextToken();
num = (int) in.nval;
arr[i] = num != 0 ? (num > 0 ? 1 : -1) : 0;
}
out.println(compute());
}
out.flush();
out.close();
br.close();
}
public static int compute() {
map.clear();
map.put(0, -1);
int ans = 0;
for (int i = 0, sum = 0; i < n; i++) {
sum += arr[i];
if (map.containsKey(sum)) {
ans = Math.max(ans, i - map.get(sum));
} else {
map.put(sum, i);
}
}
return ans;
}
}五.表现良好的最长时间段
题目:表现良好的最长时间段
算法原理
-
整体原理
- 此算法用于寻找工作时间表中表现良好时间段(劳累天数严格大于不劳累天数)的最大长度。通过将劳累的一天记为1,不劳累的一天记为 - 1,计算前缀和。利用哈希表记录前缀和首次出现的位置,通过分析当前前缀和以及寻找特定前缀和(sum - 1)的位置来确定表现良好时间段的长度,不断更新最大长度得到最终结果。
-
具体步骤
- 初始化
- 创建一个
HashMap,用于存储前缀和及其最早出现的位置。将前缀和为0最早出现的位置设为 - 1(表示一个数也没有的时候)。初始化结果变量ans = 0,用于存储表现良好时间段的最大长度。
- 创建一个
- 遍历数组计算前缀和并更新结果
- 使用
for循环遍历工作时间表数组hours。在循环中,根据当天工作小时数计算当前位置i的前缀和sum,如果当天工作小时数大于8小时,sum加1,否则sum减1。 - 如果
sum > 0,说明从开始到当前位置就是一个表现良好的时间段,其长度为i + 1,直接将ans更新为i + 1。 - 如果
sum <= 0,则需要寻找是否存在sum - 1这个前缀和在之前出现过。如果map中包含sum - 1,说明在之前的某个位置到当前位置构成了一个表现良好的时间段,计算这个时间段的长度i - map.get(sum - 1),并通过ans = Math.max(ans, i - map.get(sum - 1))更新表现良好时间段的最大长度。 - 如果当前前缀和
sum不在map中,将sum及其当前位置i添加到map中,即map.put(sum, i)。
- 使用
- 返回结果
- 最后,循环结束后,返回
ans,即表现良好时间段的最大长度。
- 最后,循环结束后,返回
- 初始化
代码实现
import java.util.HashMap;
// 表现良好的最长时间段
// 给你一份工作时间表 hours,上面记录着某一位员工每天的工作小时数
// 我们认为当员工一天中的工作小时数大于 8 小时的时候,那么这一天就是 劳累的一天
// 所谓 表现良好的时间段 ,意味在这段时间内,「劳累的天数」是严格 大于 不劳累的天数
// 请你返回 表现良好时间段 的最大长度
// 测试链接 : https://leetcode.cn/problems/longest-well-performing-interval/
public class Code05_LongestWellPerformingInterval {
public static int longestWPI(int[] hours) {
// 某个前缀和,最早出现的位置
HashMap<Integer, Integer> map = new HashMap<>();
// 0这个前缀和,最早出现在-1,一个数也没有的时候
map.put(0, -1);
int ans = 0;
for (int i = 0, sum = 0; i < hours.length; i++) {
sum += hours[i] > 8 ? 1 : -1;
if (sum > 0) {
ans = i + 1;
} else {
// sum <= 0
if (map.containsKey(sum - 1)) {
ans = Math.max(ans, i - map.get(sum - 1));
}
}
if (!map.containsKey(sum)) {
map.put(sum, i);
}
}
return ans;
}
}六.使数组和能被P整除
题目:使数组和能被 P 整除

算法原理
-
整体原理
- 这个算法旨在找到一个正整数数组中需要移除的最短子数组的长度,使得剩余元素的和能被给定的数
p整除。首先计算整个数组的余数,若余数为0则不需要移除任何子数组。然后通过计算前缀和对p的余数,利用哈希表记录这些余数及其最晚出现的位置,通过寻找特定余数来确定满足条件的最短子数组长度。
- 这个算法旨在找到一个正整数数组中需要移除的最短子数组的长度,使得剩余元素的和能被给定的数
-
具体步骤
- 计算整体余数
- 初始化一个变量
mod为0,通过遍历数组nums,不断更新mod = (mod + num)%p,得到整个数组的和对p的余数。如果mod = 0,则说明不需要移除任何子数组,直接返回0。
- 初始化一个变量
- 利用哈希表计算最短子数组长度
- 创建一个
HashMap,其中key为前缀和对p的余数,value为这个余数最晚出现的位置。将前缀和为0(初始状态)的余数对应的位置设为 - 1。初始化结果变量ans = Integer.MAX_VALUE,用于寻找最短子数组长度。 - 使用
for循环遍历数组nums,在循环中计算当前位置i的前缀和对p的余数cur = (cur + nums[i])%p。 - 计算要寻找的余数
find,如果cur >= mod,则find = cur - mod,否则find = cur + p - mod(这是为了确保在余数计算中的正确性,也可以写成find=(cur + p - mod)%p)。 - 如果
map中包含find这个余数,说明在当前位置之前存在一个子数组,移除这个子数组后剩余元素的和能被p整除。计算这个子数组的长度i - map.get(find),并通过ans = Math.min(ans, i - map.get(find))更新最短子数组长度。 - 无论是否找到满足条件的
find,都将当前余数cur及其位置i添加到map中,即map.put(cur, i)。
- 创建一个
- 返回结果
- 最后,如果
ans = nums.length,说明无法找到满足条件的子数组,返回 - 1,否则返回ans,即最短子数组的长度。
- 最后,如果
- 计算整体余数
代码实现
import java.util.HashMap;
// 使数组和能被P整除
// 给你一个正整数数组 nums,请你移除 最短 子数组(可以为 空)
// 使得剩余元素的 和 能被 p 整除。 不允许 将整个数组都移除。
// 请你返回你需要移除的最短子数组的长度,如果无法满足题目要求,返回 -1 。
// 子数组 定义为原数组中连续的一组元素。
// 测试链接 : https://leetcode.cn/problems/make-sum-divisible-by-p/
public class Code06_MakeSumDivisibleByP {
public static int minSubarray(int[] nums, int p) {
// 整体余数
int mod = 0;
for (int num : nums) {
mod = (mod + num) % p;
}
if (mod == 0) {
return 0;
}
// key : 前缀和%p的余数
// value : 最晚出现的位置
HashMap<Integer, Integer> map = new HashMap<>();
map.put(0, -1);
int ans = Integer.MAX_VALUE;
for (int i = 0, cur = 0, find; i < nums.length; i++) {
// 0...i这部分的余数
cur = (cur + nums[i]) % p;
find = cur >= mod ? (cur - mod) : (cur + p - mod);
// find = (cur + p - mod) % p;
if (map.containsKey(find)) {
ans = Math.min(ans, i - map.get(find));
}
map.put(cur, i);
}
return ans == nums.length ? -1 : ans;
}
}七.每个元音包含偶数次的最长字符串
题目:每个元音包含偶数次的最长子字符串

算法原理
-
整体原理
- 该算法用于寻找给定字符串中每个元音包含偶数次的最长子字符串的长度。通过位运算来表示元音的奇偶性状态,利用数组记录每个状态最早出现的位置,当再次出现相同状态时,就可以计算出这两个位置之间的子字符串满足条件,不断更新最长子字符串的长度。
-
具体步骤
- 初始化
- 获取字符串
s的长度n。创建一个长度为32的整数数组map,这个数组用于存储不同元音奇偶性状态最早出现的位置。将map数组中的元素初始化为 - 2,表示这个状态还未出现过,将map[0]设为 - 1,因为状态0(表示所有元音出现次数都是偶数次的初始状态)在还没有任何字符时就存在了。初始化结果变量ans = 0,用于存储最长子字符串的长度。
- 获取字符串
- 遍历字符串并更新状态和结果
- 使用
for循环遍历字符串s。在循环中,初始化变量status为0,用于表示从索引0到i - 1的字符串上元音的奇偶性状态。 - 对于每个字符
s[i],调用move方法判断是否为元音,如果不是元音(move方法返回 - 1),则status不变;如果是元音(例如a对应0,e对应1等),则通过status ^= 1 << m来更新status,这里的^是异或运算,1 << m是将1左移m位,用于改变对应元音的奇偶性状态。 - 此时
status表示从索引0到i的字符串上元音的奇偶性状态。如果map[status]不等于 - 2,说明这个状态之前已经出现过,计算当前位置i与之前出现该状态的位置map[status]之间的距离i - map[status],并通过ans = Math.max(ans, i - map[status])更新最长子字符串的长度。 - 如果
map[status]等于 - 2,说明这个状态是首次出现,将当前状态status对应的位置设为i,即map[status] = i。
- 使用
- 返回结果
- 最后,循环结束后,返回
ans,即每个元音包含偶数次的最长子字符串的长度。
- 最后,循环结束后,返回
- 初始化
代码实现
import java.util.Arrays;
// 每个元音包含偶数次的最长子字符串
// 给你一个字符串 s ,请你返回满足以下条件的最长子字符串的长度
// 每个元音字母,即 'a','e','i','o','u'
// 在子字符串中都恰好出现了偶数次。
// 测试链接 : https://leetcode.cn/problems/find-the-longest-substring-containing-vowels-in-even-counts/
public class Code07_EvenCountsLongestSubarray {
public static int findTheLongestSubstring(String s) {
int n = s.length();
// 只有5个元音字符,状态就5位
int[] map = new int[32];
// map[0...31] = -2
// map[01100] = -2, 这个状态之前没出现过
Arrays.fill(map, -2);
map[0] = -1;
int ans = 0;
for (int i = 0, status = 0, m; i < n; i++) {
// status : 0....i-1字符串上,aeiou的奇偶性
// s[i] = 当前字符
// 情况1 : 当前字符不是元音,status不变
// 情况2 : 当前字符是元音,a~u(0~4),修改相应的状态
m = move(s.charAt(i));
if (m != -1) {
status ^= 1 << m;
}
// status: 0....i字符串上,aeiou的奇偶性
// 同样的状态,之前最早出现在哪
if (map[status] != -2) {
ans = Math.max(ans, i - map[status]);
} else {
map[status] = i;
}
}
return ans;
}
public static int move(char cha) {
switch (cha) {
case 'a': return 0;
case 'e': return 1;
case 'i': return 2;
case 'o': return 3;
case 'u': return 4;
default: return -1;
}
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









