






张量分解算法(CP分解、Tucker分解、BTD分解)
基础知识
张量
在介绍张量分解算法(Tensor Decomposition Algorithms)之前,我们先介绍一下什么是张量(tensor)。张量是一个多维的数据存储形式(多维数组),数据的的维度被称为张量的阶。它可以看成是向量和矩阵在多维空间中的推广,更正式地说,一个N维或N阶张量是N个向量空间的张量积的一个元素,每个向量空间都有自己的坐标系。其中零阶张量是标量(scalar),一阶张量是一个向量(vector),二阶的张量是矩阵(matrix),三阶及三阶以上的就是我们通常所说的张量,也叫高阶张量。下图是一个三阶张量
X
∈
R
I
×
J
×
K
\mathcal{X}\in\R^{I\times{J}\times{K}}
X∈RI×J×K,有三个指标。
 应该注意的是,这里的张量不是物理和工程中的张量(如应力张量),后者在数学中通常被称为张量场。
应该注意的是,这里的张量不是物理和工程中的张量(如应力张量),后者在数学中通常被称为张量场。
秩一张量
若一个
N
N
N阶张量
X
∈
R
I
1
×
I
2
×
⋯
×
I
N
\mathcal{X}\in\R^{I_{1}\times I_{2}\times \cdots \times I_{N}}
X∈RI1×I2×⋯×IN能够被表示为
N
N
N个向量的外积,则称
X
\mathcal{X}
X为秩一张量,即
X
=
a
(
1
)
⨂
a
(
2
)
⋯
⨂
a
(
N
)
\mathcal{X}=\bf{a}^{(1)}\bigotimes\bf{a}^{(2)} \cdots\bigotimes\bf{a}^{(N)}
X=a(1)⨂a(2)⋯⨂a(N)这意味着张量的每个元素都是对应的向量元素的乘积:
x
i
1
i
2
⋯
i
N
=
a
i
1
(
1
)
a
i
2
(
2
)
⋯
a
i
N
(
N
)
x_{i_1i_2 \cdots{i_N}}=a_{i_1}^{(1)}a_{i_2}^{(2)} \cdots a_{i_N}^{(N)}
xi1i2⋯iN=ai1(1)ai2(2)⋯aiN(N)其中
1
≤
i
n
≤
I
n
1\leq i_n\leq I_n
1≤in≤In 。下图是一个三阶的秩一张量
X
=
a
⨂
b
⨂
c
\mathcal{X}=\bf{a}\bigotimes\bf{b} \bigotimes\bf{c}
X=a⨂b⨂c
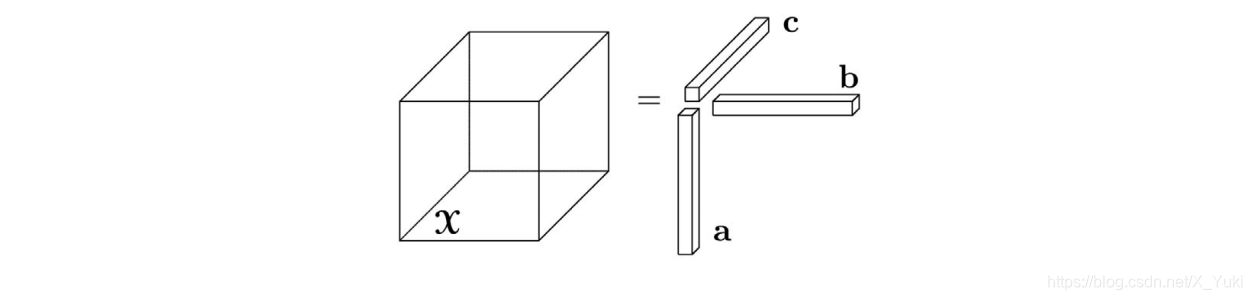 张量
X
\mathcal{X}
X的元素
(
i
,
j
,
k
)
(i,j,k)
(i,j,k)由
x
i
j
k
=
a
i
b
j
c
k
x_{ijk}=a_i b_j c_k
xijk=aibjck给出。
张量
X
\mathcal{X}
X的元素
(
i
,
j
,
k
)
(i,j,k)
(i,j,k)由
x
i
j
k
=
a
i
b
j
c
k
x_{ijk}=a_i b_j c_k
xijk=aibjck给出。
张量分解的意义
张量分解可以看作是矩阵奇异值分解(SVD)和主成分分析(PCA),即矩阵分解的高阶泛化。它能够解决维度灾难问题,而传统的方法(例如ICA、PCA、SVD和NMF)对于维数比较高的数据,一般将数据展成二维的数据形式(矩阵),从而进行降维处理、缺失数据填补(或者说成“稀疏数据填补”)和隐性关系挖掘。但是这种方式会使数据的结构信息丢失,而采用张量对数据进行存储,能够保留数据的结构信息,因此近些年在图像处理以及CV等领域得到了一些广泛的应用。
张量分解中常见的两种分解是CP分解(Canonical Polyadic Decomposition,CPD)和Tucker分解(Tucker Decomposition),下面将重点介绍这两种分解。
张量分解算法
CP分解
介绍
1927年Hitchcock基于秩一张量的定义,首次提出了将张量拆成有限个秩为1的张量相加的形式。后来在1970年Carrol和Chang将这个概念以CANDECOMP (canonical decomposition,标准分解)的形式在引入到心理测验学当中,与此同时 Harshman也提出了PARAFAC(parallel factors,平行因素) 的形式,该方法才得以流行,所以今天我们称这个将张量分解为有限个秩一张量和的形式的分解方法为CP分解,即是CANDECOMP/PARAFAC分解的缩写。
简单来说,CP分解就是将一个张量分解成多个秩为一的张量之和的形式。例如,一个三维张量
X
∈
R
I
×
J
×
K
\mathcal{X}\in\R^{I\times{J}\times{K}}
X∈RI×J×K分解成
R
R
R个秩为一的张量和的形式为
X
≈
∑
r
=
1
R
a
r
⨂
b
r
⨂
⋯
c
r
\mathcal{X}\approx \sum \limits_{{r} = 1}^{{R}} a_{r}\bigotimes b_{r}\bigotimes \cdots c_{r}
X≈r=1∑Rar⨂br⨂⋯cr其中
R
R
R是正整数,
a
r
∈
R
I
,
b
r
∈
R
J
,
c
r
∈
R
K
(
r
=
1
,
2
,
…
,
R
)
a_r\in\R^I,b_r\in\R^J,c_r\in\R^K(r=1,2,\ldots,R)
ar∈RI,br∈RJ,cr∈RK(r=1,2,…,R),
X
\mathcal{X}
X中的元素为
x
i
j
k
≈
∑
r
=
1
R
a
i
r
b
j
r
c
k
r
,
i
=
1
,
2
,
…
I
,
j
=
1
,
2
,
…
J
,
k
=
1
,
2
,
…
K
.
x_{ijk}\approx \sum \limits_{{r} = 1}^{{R}} a_{ir} b_{jr} c_{kr}\quad, i=1,2, \ldots I,j=1,2, \ldots J,k=1,2, \ldots K.
xijk≈r=1∑Rairbjrckr,i=1,2,…I,j=1,2,…J,k=1,2,…K.它的CP分解示意图如下图所示
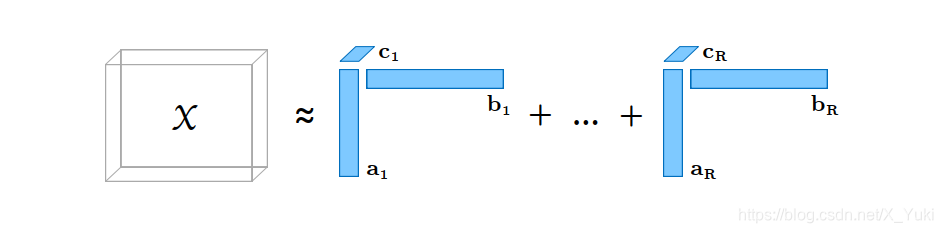
同时,我们也可以将张量
X
\mathcal{X}
X矩阵化(利用Khatri–Rao product进行转换,符号
⨀
\bigodot
⨀,其实就是列元素匹配),并引入了权重向量
λ
∈
R
R
\lambda \in \R^R
λ∈RR将A,B,C的列标准化长度为1,此时的CP分解模型可以简单地表示为
X
≈
∑
r
=
1
R
λ
r
a
r
⨂
b
r
⨂
c
r
=
[
[
λ
;
A
,
B
,
C
]
]
\mathcal{X}\approx\sum \limits_{r=1}^{R}\lambda_{r} a_{r} \bigotimes b_{r} \bigotimes c_{r}=\left [\left[ {\lambda ; A,B,C} \right]\right]
X≈r=1∑Rλrar⨂br⨂cr=[[λ;A,B,C]]
对于一般的
N
N
N阶张量
X
∈
R
I
1
×
I
2
×
⋯
×
I
N
\mathcal{X}\in\R^{I_{1}\times I_{2}\times \cdots \times I_{N}}
X∈RI1×I2×⋯×IN分解成
R
R
R个秩为一的张量和的形式为
X
≈
[
[
λ
;
A
(
1
)
,
A
(
2
)
,
…
,
A
(
N
)
]
]
≡
∑
r
=
1
R
λ
r
a
r
(
1
)
⨂
a
r
(
2
)
⨂
⋯
a
r
(
N
)
\mathcal{X}\approx \left [\left[ {\lambda ; A^{(1)},A^{(2)},\ldots,A^{(N)}} \right]\right] \equiv\sum \limits_{{r} = 1}^{{R}} \lambda_{r} a_{r}^{(1)}\bigotimes a_{r}^{(2)}\bigotimes \cdots a_{r}^{(N) }
X≈[[λ;A(1),A(2),…,A(N)]]≡r=1∑Rλrar(1)⨂ar(2)⨂⋯ar(N)通常情况下,
a
r
(
n
)
a_r^{(n)}
ar(n)是一个单位向量且
A
(
n
)
∈
R
I
n
×
R
(
n
=
1
,
2
,
…
,
N
)
A^{(n)}\in \R^{I_n \times R}(n=1,2,\ldots,N)
A(n)∈RIn×R(n=1,2,…,N),
A
(
n
)
=
[
a
1
n
a
2
n
⋯
a
R
n
]
,
Λ
=
d
i
a
g
(
λ
)
A^{(n)}=\left [ a_1^n \quad a_2^n\quad \cdots\quad a_R^n \right],\Lambda=diag(\lambda)
A(n)=[a1na2n⋯aRn],Λ=diag(λ),则上式可以写成
X
=
Λ
×
1
A
(
1
)
×
2
A
(
2
)
⋯
×
N
A
(
N
)
\mathcal{X}=\Lambda\times_{1}A^{(1)}\times_{2}A^{(2)}\cdots\times_{N}A^{(N)}
X=Λ×1A(1)×2A(2)⋯×NA(N)矩阵表达形式为
X
(
n
)
≈
A
(
n
)
Λ
(
A
(
N
)
⨀
⋯
A
(
n
+
1
)
⨀
A
(
n
−
1
)
⋯
⨀
A
1
)
T
X_{(n)}\approx A^{(n)}\Lambda(A^{(N)} \bigodot \cdots A^{(n+1)} \bigodot A^{(n-1)}\cdots \bigodot A^{1})^T
X(n)≈A(n)Λ(A(N)⨀⋯A(n+1)⨀A(n−1)⋯⨀A1)T
CP秩与CP分解求解
张量
X
\mathcal{X}
X的秩是指,用秩一张量之和来精确表示所需要的秩一张量的最少个数R的最小值为张量的秩,记作
R
a
n
k
(
X
)
=
R
Rank(\mathcal{X})=R
Rank(X)=R,这样的CP分解也称为张量的秩分解。
R
a
n
k
c
p
(
X
)
=
m
i
n
{
R
∣
X
=
∑
r
=
1
R
X
(
r
)
,
X
(
r
)
是
秩
张
量
}
Rank_{cp}(\mathcal{X})=min\{R\mid\mathcal{X}=\sum \limits_{r=1}^{R}\mathcal{X}^{(r)},\mathcal{X}^{(r)}是秩张量\}
Rankcp(X)=min{R∣X=r=1∑RX(r),X(r)是秩张量}
显然,这样定义的张量秩和矩阵的秩的定义十分相似,换句话说这种定义可以退化为矩阵的秩(即对于矩阵而言,秩的定义与普通的矩阵秩的定义等价)。但是在代数性质上,张量的秩与矩阵秩相比则表现出很多不一样的特性。张量秩的个数求解是一个NP问题,研究者只能通过一些数值方法近似的找到数个该张量的近似分解,从而估计该张量的秩。那么我们怎么去优化所有参数,使得分解后跟分解前尽可能的相似呢?
通常我们通过迭代的方法对 R R R从1开始遍历直到找到一个合适的解。当数据无噪声时,重构误差为0所对应的解即为CP分解的解,当数据有噪声的情况下,可以通过CORCONDIA算法估计 R R R。当分解的秩一张量的个数确定下来之后,可以通过交替最小二乘方法(the Alternating Least Squares,ALS)对CP分解进行进行求解。
对于
N
N
N阶张量
X
∈
R
I
1
×
I
2
×
⋯
×
I
N
\mathcal{X}\in\R^{I_{1}\times I_{2}\times \cdots \times I_{N}}
X∈RI1×I2×⋯×IN完整的交替最小二乘法优化CP分解参数的过程如下图
 其中,它假设分解出秩一张量的个数
R
R
R是已知的。
其中,它假设分解出秩一张量的个数
R
R
R是已知的。
在一些应用中,为了使得CP分解更加的鲁棒和精确,可以在分解出的因子上加上一些先验知识即约束。比如说平滑约束(smooth)、正交约束、非负约束(nonegative) 、稀疏约束(sparsity)等。
Tucker 分解
介绍
Tucker分解最早由Tucker在1963年提出的,Levin和Tucker在随后的文章中对其进行了改进。
张量的Tucker分解是指,将一个张量表示成一个核张量(Core Tensor)沿着每一个模式乘上一个矩阵的形式,下面以一个三阶
X
∈
R
I
×
J
×
K
\mathcal{X}\in\R^{I\times{J}\times{K}}
X∈RI×J×K示意图为例
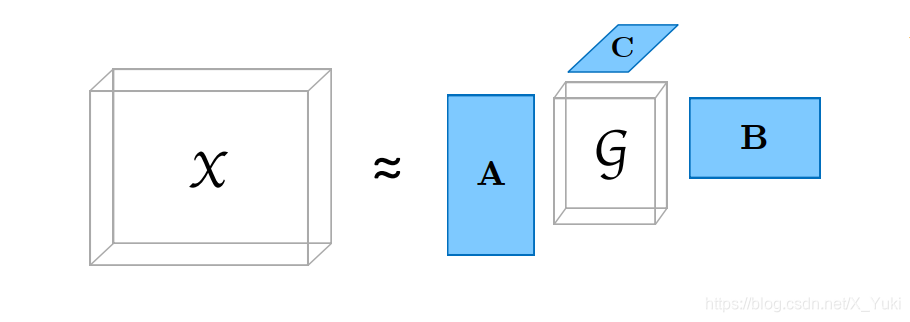
上图中
A
∈
R
I
×
P
A\in \mathbb{R}^{I\times P}
A∈RI×P,
B
∈
R
J
×
Q
B\in \mathbb{R}^{J\times Q}
B∈RJ×Q,
C
∈
R
K
×
R
C\in \mathbb{R}^{K\times R}
C∈RK×R是三个因子矩阵(通常是正交的),
G
∈
R
P
×
Q
×
R
\mathcal{G}\in \mathbb{R}^{P\times Q\times R}
G∈RP×Q×R是核张量。具体公式如下
X
=
G
×
1
A
×
2
B
×
3
C
=
∑
p
=
1
P
∑
q
=
1
Q
∑
r
=
1
R
g
p
q
r
a
p
⨂
b
q
⨂
c
r
=
[
[
G
;
A
,
B
,
C
]
]
\mathcal{X}=\mathcal{G}\times_{1} A \times_{2} B\times_{3}C=\sum \limits_{p = 1}^{{P}}\sum \limits_{q = 1}^{Q}\sum \limits_{r = 1}^{R}g_{pqr}a_{p}\bigotimes b_{q} \bigotimes c_{r}=\left[\kern-0.15em\left[ {\mathcal{G} ; A,B,C}\right]\kern-0.15em\right]
X=G×1A×2B×3C=p=1∑Pq=1∑Qr=1∑Rgpqrap⨂bq⨂cr=[[G;A,B,C]]
在元素级别上,可表示为
x
i
j
k
≈
∑
p
=
1
P
∑
q
=
1
Q
∑
r
=
1
R
g
p
q
r
a
i
p
b
j
q
c
k
r
,
i
=
1
,
2
,
…
I
,
j
=
1
,
2
,
…
J
,
k
=
1
,
2
,
…
K
.
x_{ijk}\approx \sum\limits_{p=1}^P \sum \limits_{q = 1}^{Q}\sum \limits_{{r} = 1}^{{R}} g_{pqr} a_{ip} b_{jq} c_{kr}\quad, i=1,2, \ldots I,j=1,2, \ldots J,k=1,2, \ldots K.
xijk≈p=1∑Pq=1∑Qr=1∑Rgpqraipbjqckr,i=1,2,…I,j=1,2,…J,k=1,2,…K.
这里
P
、
Q
、
R
P、Q、R
P、Q、R是分量的数量(即因子矩阵
A
、
B
A、B
A、B和
C
C
C中的列向量。如果
P
、
Q
、
R
P、Q、R
P、Q、R小于
I
、
J
、
K
,
I、J、K,
I、J、K,则核心张量
G
\mathcal{G}
G可以看作是
X
\mathcal{X}
X的压缩版本,在某些情况下,分解后的张量的存储显著小于原始张量。
虽然Tucker模型是在三维数组下引入的,但它可以推广到
N
N
N阶张量:
X
=
G
×
1
A
(
1
)
×
2
A
(
2
)
⋯
×
(
N
)
A
(
N
)
=
[
[
G
;
A
(
1
)
,
A
(
2
)
,
⋯
,
A
(
N
)
]
]
\mathcal{X}=\mathcal{G}\times_{1} A^{(1)} \times_{2} A^{(2)}\cdots \times_{(N)}A^{(N)}=\left[\kern-0.15em\left[ {\mathcal{G} ; A^{(1)} ,A^{(2)} ,\cdots,A^{(N)} } \right]\kern-0.15em\right]
X=G×1A(1)×2A(2)⋯×(N)A(N)=[[G;A(1),A(2),⋯,A(N)]]
其矩阵形式为
X
(
n
)
=
A
(
n
)
G
(
n
)
(
A
(
N
)
⊗
⋯
⊗
A
(
n
+
1
)
⊗
A
(
n
−
1
)
⋯
⊗
A
(
1
)
)
T
X_{(n)}=A^{(n)}G_{(n)}(A^{(N)}\otimes \cdots \otimes A^{(n+1)}\otimes A^{(n-1)}\cdots \otimes A^{(1)} )^{T}
X(n)=A(n)G(n)(A(N)⊗⋯⊗A(n+1)⊗A(n−1)⋯⊗A(1))T
同时由图可以看出Tucker分解实质上是一种高阶的主成分分析(PCA,每个mode上的因子矩阵称为张量在每个mode上的基矩阵或者是主成分),因此Tucker 分解又称为高阶PCA,高阶SVD等。实际上,当核张量是对角化的且
P
=
Q
=
R
P=Q=R
P=Q=R时,CP分解便是Tucker分解的一种特殊形式且CP分解。
Tucker秩与Tucker分解求解
对于
N
N
N阶张量
X
∈
R
I
1
×
I
2
×
⋯
×
I
N
\mathcal{X}\in\R^{I_{1}\times I_{2}\times \cdots \times I_{N}}
X∈RI1×I2×⋯×IN,定义张量的
n
n
n-秩为其按照第
n
n
n个模式矩阵化展开后得到的矩阵
X
(
n
)
X_{(n)}
X(n)的秩,表示为
R
a
n
k
(
n
)
(
X
)
Rank_{(n)}(X)
Rank(n)(X)。若令
R
n
=
R
a
n
k
n
(
X
)
,
n
=
1
,
2
,
…
,
N
R_n=Rank_n(X),n=1,2,\ldots,N
Rn=Rankn(X),n=1,2,…,N,那么我们称张量
X
\mathcal{X}
X为
R
a
n
k
−
{
R
1
,
R
2
,
…
,
R
N
}
Rank-\{R_1,R_2,\ldots,R_N\}
Rank−{R1,R2,…,RN}张量,同时张量
X
\mathcal{X}
X的Tucker秩可定义为
R
a
n
k
T
u
c
k
e
r
(
X
)
=
m
a
x
{
R
n
,
n
=
1
,
2
,
…
,
N
}
Rank_{Tucker}(\mathcal{X})=max\{R_n,n=1,2,\ldots,N \}
RankTucker(X)=max{Rn,n=1,2,…,N}
对于固定的
n
n
n-秩,Tucker分解的唯一性不能保证,通常情况下会加上一些约束,如分解得到的因子单位正交约束等。对于Tucker分解优化的方法有HOSVD(High Order SVD)和HOOI(High-order orthogonal iteration)求解算法,如下所示
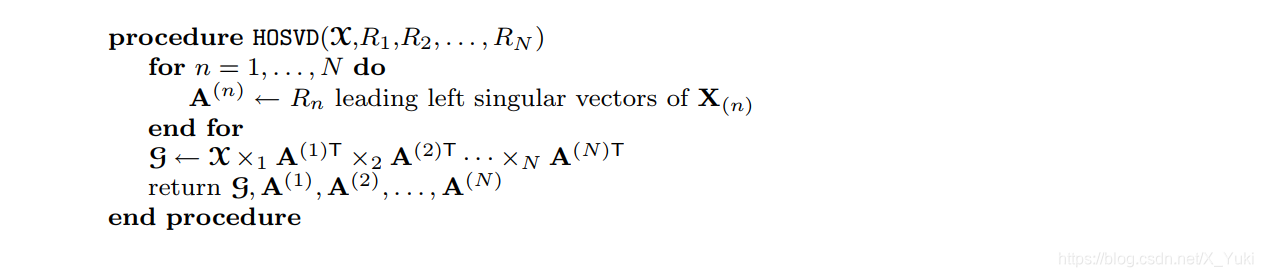
 其中HOSVD算法通过对张量的每一个模式上做SVD分解,对各个模式上的因子矩阵进行求解,最后计算张量在各个模式上的投影之后的张量作为核张量。但是HOSVD 不能保证得到一个较好的近似。而HOSVD算法是HOOI算法的一个很好的初始化,HOOI算法是将张量分解看作是一个优化的过程,不断迭代得到分解结果。
其中HOSVD算法通过对张量的每一个模式上做SVD分解,对各个模式上的因子矩阵进行求解,最后计算张量在各个模式上的投影之后的张量作为核张量。但是HOSVD 不能保证得到一个较好的近似。而HOSVD算法是HOOI算法的一个很好的初始化,HOOI算法是将张量分解看作是一个优化的过程,不断迭代得到分解结果。
BTD 分解
引入
当
R
\mathbb {R}
R和
C
\mathbb {C}
C的区别不重要时,我们用
K
\mathbb K
K来表示
R
\mathbb {R}
R或
C
\mathbb {C}
C。现在定义一个张量
T
∈
K
I
×
J
×
K
\mathcal T \in \mathbb K^{I\times J\times K}
T∈KI×J×K,在CP分解中,张量
T
\mathcal T
T分解为
R
R
R个秩一张量的形式,公式为
T
=
∑
r
=
1
R
a
r
⨂
b
r
⨂
⋯
c
r
=
∑
r
=
1
R
(
a
r
b
r
T
)
⨂
c
r
\mathcal{T}= \sum \limits_{{r} = 1}^{{R}} a_{r}\bigotimes b_{r}\bigotimes \cdots c_{r} =\sum \limits_{r = 1}^{R} (a_rb_r^T)\bigotimes c_r
T=r=1∑Rar⨂br⨂⋯cr=r=1∑R(arbrT)⨂cr可视化如下图所示
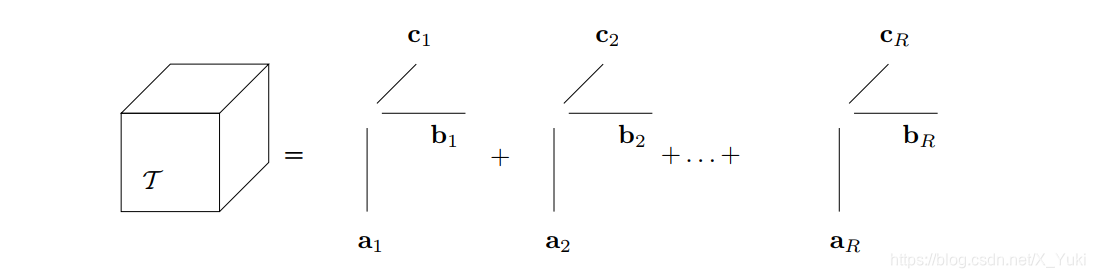 从公式可以看出,
a
r
b
r
T
a_rb_r^T
arbrT是一个秩-1的矩阵(低秩矩阵)。而低秩往往是一些局部的特征,但是在一些应用中,我们想要得到多尺度的特征,这个时候CP分解就无法直观地做到了。如果
a
r
b
r
T
a_rb_r^T
arbrT不是一个秩-1️的矩阵,而是一个秩为
K
K
K的矩阵,那么显然
a
r
a_r
ar和
b
r
b_r
br就不是向量了,而是一个秩为
L
r
L_r
Lr的矩阵,因此我们就得到了BTD模型的一种形式即
T
=
∑
r
=
1
K
A
r
B
r
T
⨂
c
r
\mathcal{T}=\sum\limits_{r=1}^{K}A_rB_r^T\bigotimes c_r
T=r=1∑KArBrT⨂cr然后将这个模型进行推广得出BTD的一般形式。
从公式可以看出,
a
r
b
r
T
a_rb_r^T
arbrT是一个秩-1的矩阵(低秩矩阵)。而低秩往往是一些局部的特征,但是在一些应用中,我们想要得到多尺度的特征,这个时候CP分解就无法直观地做到了。如果
a
r
b
r
T
a_rb_r^T
arbrT不是一个秩-1️的矩阵,而是一个秩为
K
K
K的矩阵,那么显然
a
r
a_r
ar和
b
r
b_r
br就不是向量了,而是一个秩为
L
r
L_r
Lr的矩阵,因此我们就得到了BTD模型的一种形式即
T
=
∑
r
=
1
K
A
r
B
r
T
⨂
c
r
\mathcal{T}=\sum\limits_{r=1}^{K}A_rB_r^T\bigotimes c_r
T=r=1∑KArBrT⨂cr然后将这个模型进行推广得出BTD的一般形式。
BTD分解与求解
首先,我们给出一些定义:
1.张量
T
∈
K
I
1
×
I
2
×
I
3
\mathcal T \in \mathbb K^{I_1\times I_2\times I_3}
T∈KI1×I2×I3的
m
o
d
e
mode
mode-
n
n
n向量是由张量
T
\mathcal T
T通过改变指标
i
n
i_n
in并保持其他指标不变而得到的
I
n
I_n
In维向量。
m
o
d
e
mode
mode-
n
n
n向量泛化行向量和列向量。
2.张量
T
\mathcal T
T的
m
o
d
e
mode
mode-
n
n
n秩是它的
m
o
d
e
mode
mode-
n
n
n向量张成子空间的维数,高阶张量的
m
o
d
e
mode
mode-
n
n
n秩是矩阵列(行)秩的明显推广。
3.如果一个三阶张量的
m
o
d
e
mode
mode-1秩,
m
o
d
e
mode
mode-2秩,
m
o
d
e
mode
mode-3秩分别等于
L
,
M
和
N
L,M和N
L,M和N,那么它就是
r
a
n
k
−
(
L
,
M
,
N
)
rank-(L, M, N)
rank−(L,M,N)。一个
r
a
n
k
rank
rank-
(
1
,
1
,
1
)
(1, 1, 1)
(1,1,1)张量简称
r
a
n
k
rank
rank-1。
4.如果一个三阶张量
T
\mathcal T
T等于三个向量的外积,那么它的秩为1,秩(与
m
o
d
e
mode
mode-
n
n
n秩相反)现在定义如下:
5.张量
T
\mathcal T
T的秩是在线性组合中生成
T
\mathcal T
T的
r
a
n
k
rank
rank-1张量的最小数目。
2008年Lieven De Lathauwer 等人提出了一种Block term decomposition(BTD)张量分解方法,它将一个
N
N
N阶张量分解为
R
R
R个成员张量的形式。定义一个张量
T
∈
K
I
×
J
×
K
\mathcal T \in \mathbb K^{I\times J\times K}
T∈KI×J×K,
T
\mathcal T
T在秩(
L
,
M
,
N
L, M, N
L,M,N)下分解的可视化如下图所示,每一个成员张量是一个
R
a
n
k
−
(
L
,
M
,
N
)
Rank−(L, M, N)
Rank−(L,M,N)的Tucker分解
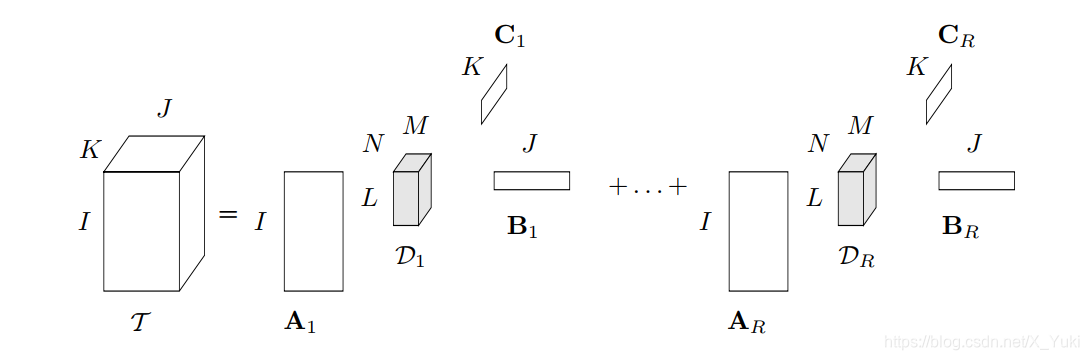
其数学表达式为
T
=
∑
r
=
1
R
D
r
×
1
A
r
×
2
B
r
×
3
C
r
\mathcal{T}=\sum \limits_{r = 1}^{R} \mathcal{D_r}\times_{1} A_r \times_{2} B_r\times_{3}C_r
T=r=1∑RDr×1Ar×2Br×3Cr其中,
D
r
∈
K
K
×
M
×
N
\mathcal D_r \in \mathbb K^{K\times M\times N}
Dr∈KK×M×N是满秩
R
a
n
k
−
(
L
r
,
M
r
,
N
r
)
Rank−(L_r, M_r, N_r)
Rank−(Lr,Mr,Nr)张量,而
A
r
∈
K
I
×
L
(
I
≥
L
)
A_r \in \mathbb K^{I\times L}(I\geq L)
Ar∈KI×L(I≥L),
B
r
∈
K
J
×
M
(
J
≥
M
)
B_r \in \mathbb K^{J\times M}(J\geq M)
Br∈KJ×M(J≥M),
C
r
∈
K
K
×
N
(
K
≥
N
)
C_r \in \mathbb K^{K\times N}(K\geq N)
Cr∈KK×N(K≥N)都是全列秩,且
1
≤
r
≤
R
1\leq r \leq R
1≤r≤R。
从公式和图解我们可以看出,BTD分解可以看作是我们之前介绍的CP分解和Tucker分解的组合形式。当 R = 1 R=1 R=1的时候,成员张量只有一个,此时这个分解就是 R a n k − ( L , M , N ) Rank−(L, M, N) Rank−(L,M,N)的Tucker分解。而当每一个成员张量是一个秩一分解的时候,该分解退化为一个CP分解 (CP分解是将一个张量 T \mathcal T T分解为 R R R个秩为1的张量形式),从而表现出BTD分解具有很强的泛化能力。
BTD分解现在的求解算法有很多,比如说非线性最小二乘法,交替最小二乘算法(ALS),张量对角算法等。
T
∈
K
I
×
J
×
K
\mathcal T \in \mathbb K^{I\times J\times K}
T∈KI×J×K采用ALS算法的求解步骤如下图所示
 其中,算法中的QR分解是为了防止算法出现数值计算错误。
其中,算法中的QR分解是为了防止算法出现数值计算错误。
特殊的BTD分解
在此之前,我已经介绍了BTD分解的两种特殊形式:Tucker和CP分解,下面介绍两种特殊的张量分解。
r a n k rank rank- ( L r , L r , 1 ) (L_r,L_r,1) (Lr,Lr,1)分解
定义一个张量
T
∈
K
I
×
J
×
K
\mathcal T \in \mathbb K^{I\times J\times K}
T∈KI×J×K,
T
\mathcal T
T在
r
a
n
k
rank
rank-
(
L
r
,
L
r
,
1
)
(L_r,L_r,1)
(Lr,Lr,1)块和下分解为
T
=
∑
r
=
1
R
E
r
∘
c
r
\mathcal T =\sum \limits_{r = 1}^{R} \bf{E}_r \circ c_r
T=r=1∑REr∘cr其中
I
×
J
I \times J
I×J矩阵
E
r
\bf{E}_r
Er是
r
a
n
k
rank
rank-
L
r
L_r
Lr,且
1
≤
r
≤
R
1\leq r \leq R
1≤r≤R。如果我们将
E
r
\bf{E}_r
Er因式分解为
A
r
⋅
B
r
T
\bf A_r\cdot\bf{B}_r^T
Ar⋅BrT,其中矩阵
A
r
∈
K
I
×
L
r
\bf A_r \in\mathbb K^{I\times L_r}
Ar∈KI×Lr和矩阵
B
r
∈
K
J
×
L
r
\bf B_r \in\mathbb K^{J\times L_r}
Br∈KJ×Lr是
r
a
n
k
rank
rank-
L
r
L_r
Lr,因此,可以将上式写成
T
=
∑
r
=
1
R
(
A
r
⋅
B
r
T
)
∘
c
r
\mathcal T =\sum \limits_{r = 1}^{R} (\bf A_r\cdot\bf{B}_r^T) \circ c_r
T=r=1∑R(Ar⋅BrT)∘cr同时,如果对角矩阵
D
r
\bf D_r
Dr能被解释为一个
(
L
r
,
L
r
,
1
)
(L_r,L_r,1)
(Lr,Lr,1)张量,那么还可以写成
T
=
∑
r
=
1
R
D
r
⋅
1
A
r
⋅
2
B
r
⋅
3
c
r
\mathcal{T}=\sum \limits_{r = 1}^{R} \bf {D_r}\cdot_{1} A_r \cdot_{2} B_r\cdot_{3}c_r
T=r=1∑RDr⋅1Ar⋅2Br⋅3cr其中
c
r
c_r
cr是单位范数,张量分解如下图所示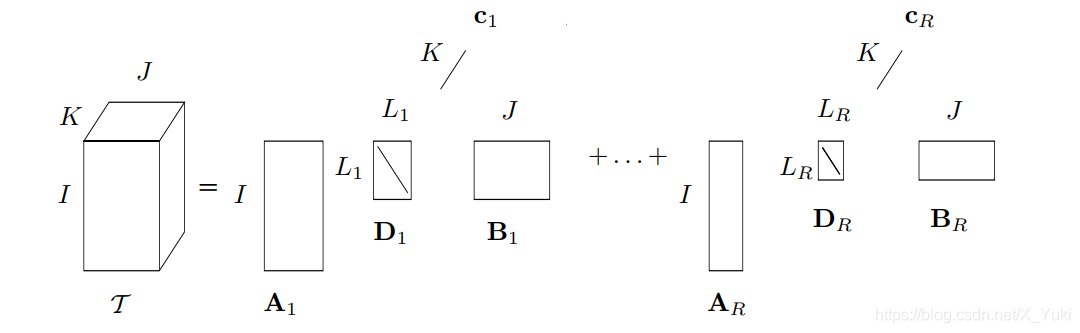 求解算法与BTD算法类似,相应的是没有最后求解core tensor部分。
求解算法与BTD算法类似,相应的是没有最后求解core tensor部分。
r a n k rank rank- ( L , L , 1 ) (L,L,1) (L,L,1)分解
当
r
a
n
k
rank
rank-
(
L
r
,
L
r
,
1
)
(L_r,L_r,1)
(Lr,Lr,1)的每一个
L
r
L_r
Lr都取值为
L
L
L时i,即可得到
r
a
n
k
rank
rank-
(
L
,
L
,
1
)
(L,L,1)
(L,L,1)分解即:
T
=
∑
r
=
1
R
E
r
∘
c
r
\mathcal T =\sum \limits_{r = 1}^{R} \bf{E}_r \circ c_r
T=r=1∑REr∘cr其中
I
×
J
I \times J
I×J矩阵
E
r
\bf{E}_r
Er是
r
a
n
k
rank
rank-
L
L
L,图解为: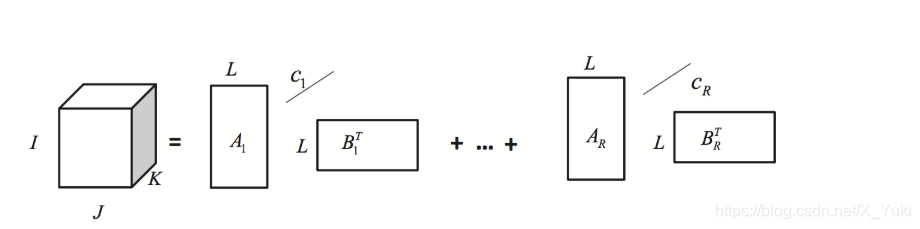














 1084
1084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









