







在AI绘画的学习与使用中,无论是入门小白还是进阶高手,都绕不开两个核心概念:文生图和图生图。
这是所有AI绘画工具的根本操作方法。掌握这两者的基本原理,你便能轻松驾驭大多数AI工具,无论是MidJourney、Stable Diffusion,还是其他图像生成平台。
什么是文生图?
简单来说,文生图就是通过文本生成图像。
你输入一段描述性文字,AI就会根据这段文字生成相应的图片。这段描述文字在AI绘画中被称为“提示词(Prompt)”。

比如:
• 描述输入:“A realistic portrait of a woman, with detailed lighting and shading.”
• AI生成:逼真的女性肖像,光影细腻。

文生图的威力在于,更自由的发挥想象力通过文本的细致描述,生成符合预期的图片。
你可以控制画面的风格、内容和构图,让AI生成各种人、物、景、摄影、插画、油画、动画、二维、3d图等不同风格、品类、载体的图像。

文生图的应用领域
广告与品牌设计:创意海报、社交媒体封面图等。
游戏与影视概念设计:生成场景或角色的概念图。
艺术创作:从插画到摄影风格,文生图可以模拟各种艺术形式。
什么是图生图?
与文生图不同,图生图的核心在于你提供一张基础图像,AI会根据提示词进行加工,生成一张混合了原始图像和文本描述的新图像。这不仅有助于AI理解你想要的风格或变化,还可以让图像产生艺术性、风格化的提升。
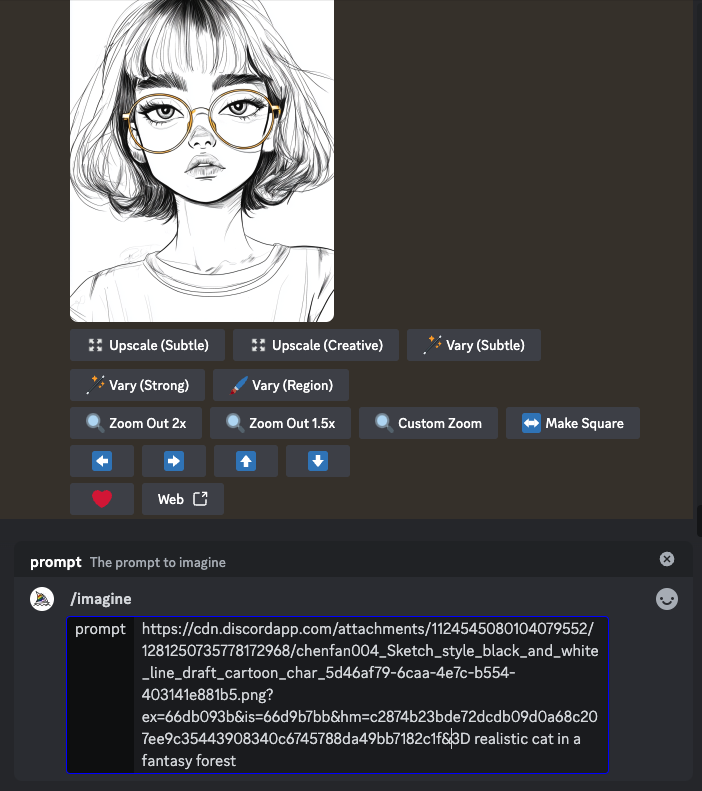
比如:
你上传一张素描风格的猫,输入提示词“3D realistic cat in a fantasy forest”,
AI会生成一张基于你上传图像但又融入了文本描述的猫在森林中的3D效果图。

不过,单纯的图生图并不能完全保留原始图像的结构和特点,特别是在涉及复杂细节时。AI更多地是在参考你上传的图像,而不是严格复刻它的每一个细节。
插件的重要性
如果你希望在图生图的过程中完全保留原始图像的结构和特点,需要使用相关的插件来增强AI的处理能力。例如,在使用Stable Diffusion时,可以通过一些特定的插件调整AI生成的图像,以更接近原始图片的结构。
这些插件会为AI提供更加精准的引导,让它在修改图像的同时不丢失原始画面的核心特点,从而实现更高的控制性。
应用场景
二次创作:对于现有的作品进行风格化再创作。
特定风格的复现:比如将一张现实照片变成手绘风格或动画效果。
产品设计:设计师们可以通过上传原型图,再输入设计描述来生成改进后的效果图。
MidJourney的限制
在当前的主流AI绘画工具中,
比如MidJourney,只支持英文提示词。
因此,在生成过程中,中文用户通常需要先将提示词翻译成英文再输入,这对一些非英文使用者来说,可能会略显不便。但这并不影响MidJourney强大的生成能力,尤其是在细节处理上依然相当出色。
综合看法:文生图与图生图的结合
在实际应用中,文生图与图生图经常是相辅相成的。通过文生图,你可以快速获得一张基础图像,然后通过图生图进行风格化或个性化的调整,最终得到完全符合你需求的作品。
无论你是设计师、艺术家,还是想通过AI生成个人作品的创作者,这两种方法的掌握都会大大提升你的创作效率。而且,AI绘画的技术还在不断进步,随着更多功能和插件的推出,未来的文生图与图生图将更加智能与多样。
总结
• 文生图:输入文字描述,生成图片。
• 图生图:上传图片+文字描述,生成经过修改的图像。
• 插件的使用:更好地保留原始图像结构。
AI绘画的学习并不难,学会这两种核心方法,再搭配不同工具,你也可以快速上手,创作出各种风格、形式的艺术作品。让AI成为你创作的得力助手!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









