






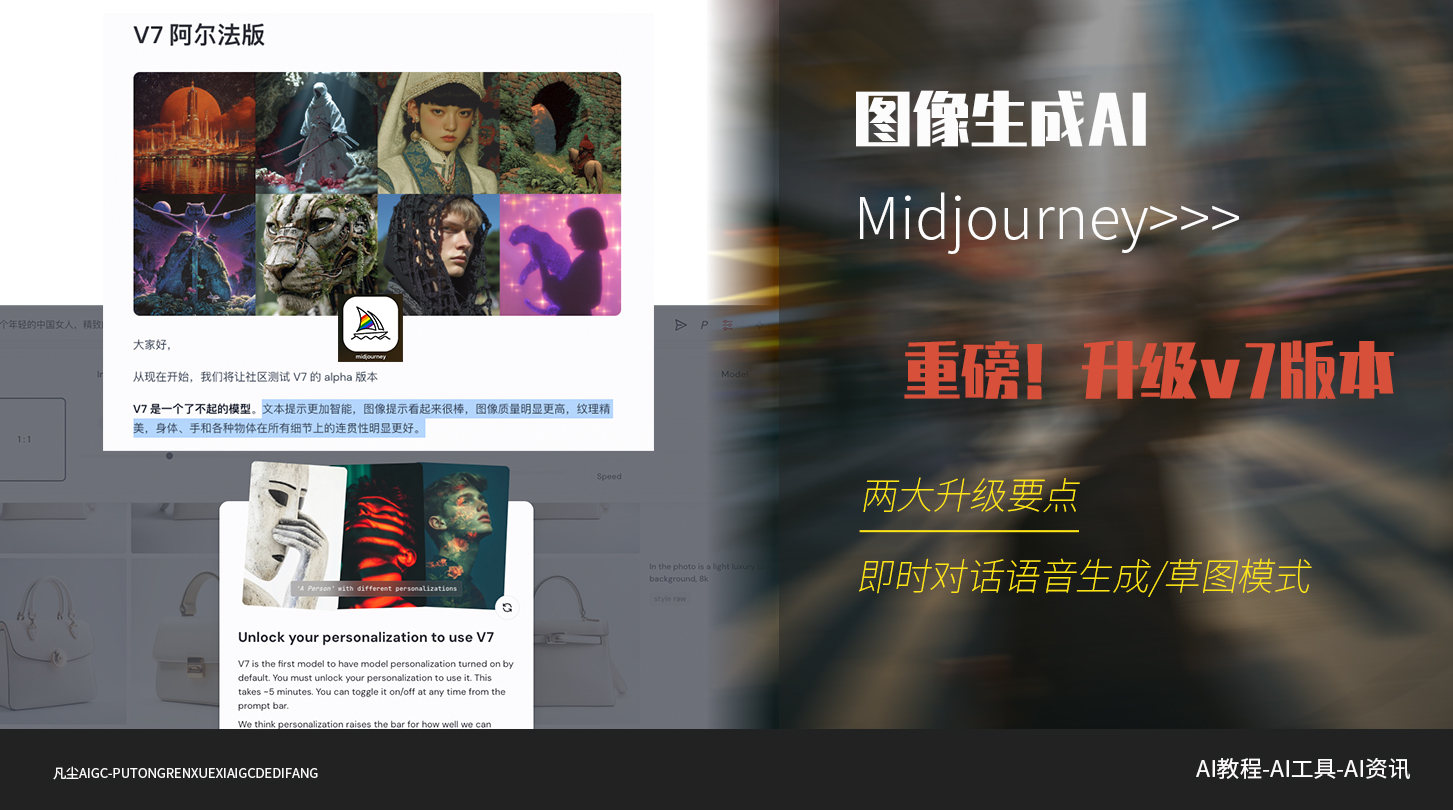
继GPT-4o大放异彩之后, Midjourney也迎来了一次重磅更新:Midjourney V7 正式上线,并开放了 alpha 测试!

这一次不吹不黑,作为一名专注AIGC应用与落地赋能的AI应用实践者来说,我也第一时间上手测试了V7版本,并对其更新进行了深入体验。结合Midjourney官方给出的路线图和功能解读,我们完全可以把这次V7升级概括为两个关键词:
一个更强,一个更快。
一、更强:语义理解 + 图像质量双提升
V7在模型层面做了底层升级,最直接的感受是,它的语义理解能力更强了,画面细节一致性更高了。
什么意思?就是我们可以更大胆、更复杂地去写提示词,它也能准确理解并生成令人满意的结果——而且这次,支持中文提示词。
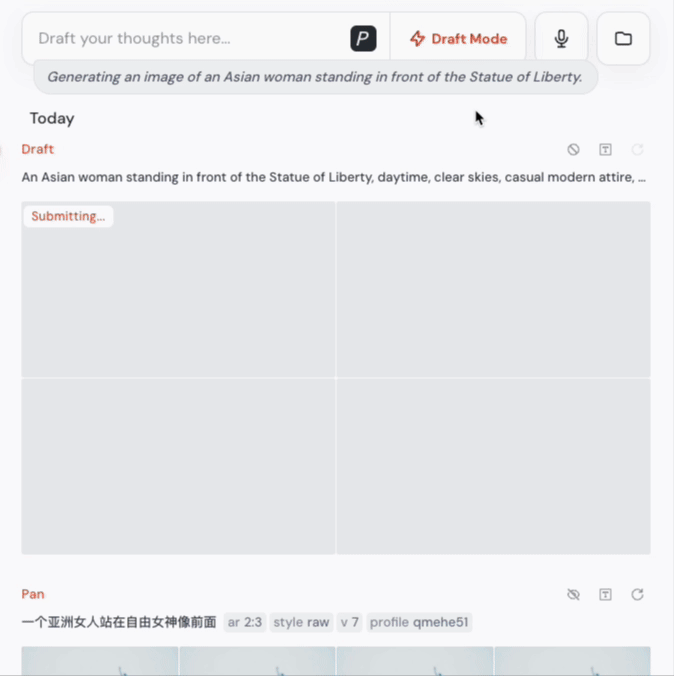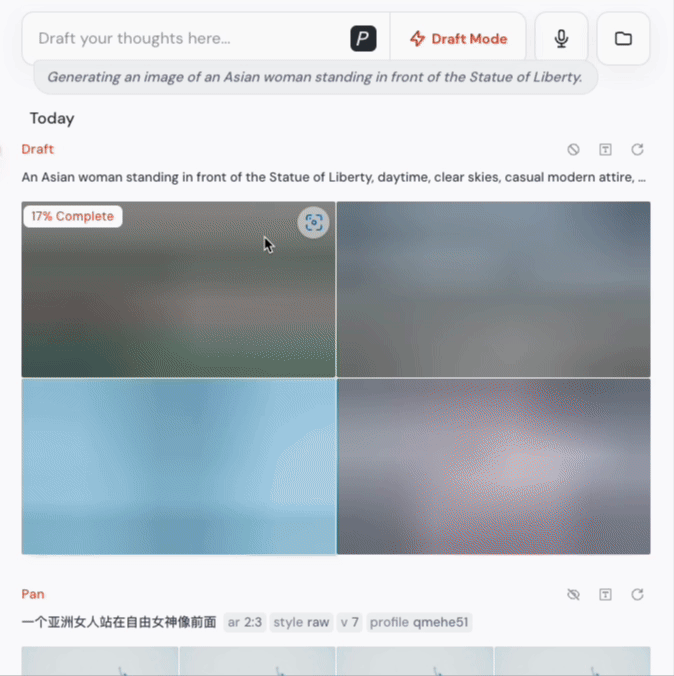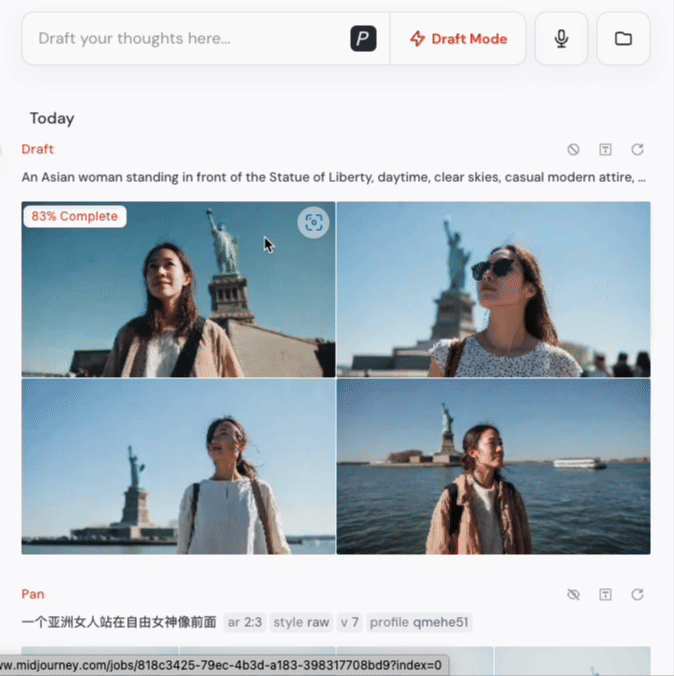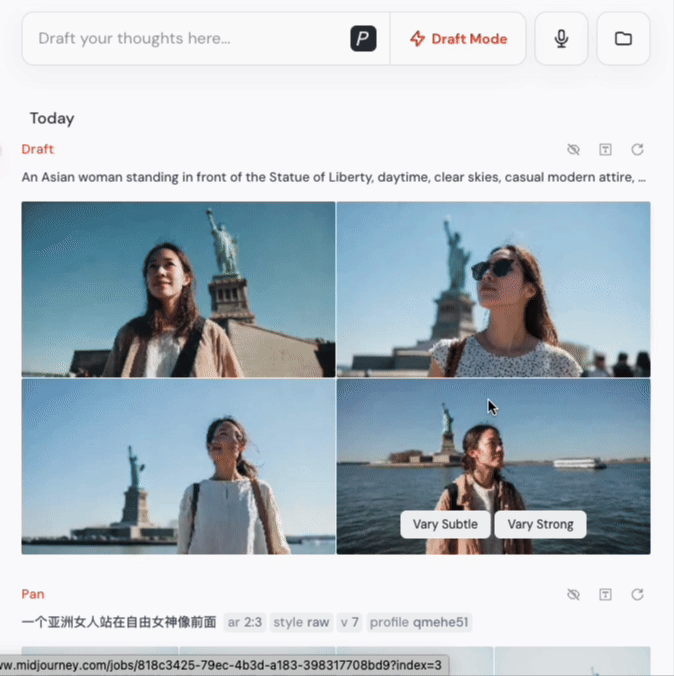
比如我直接用中文输入这样一句话:“一个亚洲女人站在金字塔前面,一只手拿着一个红色的苹果,一只手挡在眼睛前面,微笑着看向镜头。”

这句话放在以前,模型很可能因为提示词过长会抓不住重点或者丢失一些细节。但现在,V7可以轻松还原你脑中的画面,而且生成的图片是高清的,纹理、姿态、表情都有细致表现,几乎可以媲美实拍。
不过也要实话实说,V7在画质上的提升不是飞跃式的,毕竟V6的画面质量就已经很高了。这次更多是在细节一致性方面加强,比如之前常见的“手指混乱”、“人物表情扭曲”等问题,现在明显改善。整个人体、服饰、物体之间的协调性更好了,真实感更强,不少图甚至有“相机直出”的错觉。

比较有意思的是,我发现V7生成图的右下角经常会出现一个类似微博的水印……这不禁让人怀疑,是不是V7的训练素材里微博图片的权重不低?
但瑕不掩瑜,总体来看,这一代模型在理解力和视觉表现上都稳稳拉高了一档,是一次偏“基础功”的打磨升级。
二、更快:全新草图模式上线,真正意义上的“言出图随”
如果说第一个升级是“更强”,那第二个升级可以说是“更爽”!
V7最重磅的新功能叫做Draft Mode(草图模式)。它不仅是Midjourney首次引入的全新生成方式,更是一次体验上的大飞跃。
草图模式有多快?
官方说是 10 倍,我实测下来:4-5秒生成4张图,是真的!
而且在这个模式下,生成成本只有标准模式的一半,效率飙升,成本减半,对创作者来说就是:随时试错、疯狂迭代、毫无心理负担。
但更有意思的是,草图模式支持语音对话生成图像!
举个例子:我直接说一句话(是语音),“生成一张照片,内容是一个时尚的女人站在上海街道微笑看向镜头,背景是虚化的东方明珠塔。”
几秒之后,图片就自动生成好了。

再告诉它:“把第二张图转成吉卜力动画风格。”
它立刻理解、优化提示词,然后生成新的动画风格图片。整个过程全程无需手打字,配合十倍生成速度,真的就是**“想什么来什么”**,像是在操作一个拥有视觉画笔的智能助手。
当然,草图模式下的图像画质会有所下降,毕竟它本质是“草图”用途,更适合创意发散、构图测试、灵感捕捉等场景。如果你对某一张草图满意,只需一键“增强”即可转为高清图,非常方便。
你可以无限次调整,直到得到满意的效果。
三、接下来会更猛:人物&物体参考功能即将上线
值得一提的是,这次的升级并不是终点。
Midjourney 官方已经放话:接下来60天内,每1~2周会有新功能上线。其中最受期待的是 V7 的“人物与物体参考(Reference)功能”,预计会进一步强化角色的一致性与场景控制力。

如果你熟悉Stable Diffusion里的ControlNet,或者是最近GPT-4o提到的“多模态实时互动能力”,你就能感受到这种模型+控制工具结合将带来什么样的生产力飞跃。
结语:模型升级永不停,别怕“工具白学”
很多人看到GPT-4o爆火后就开始担心:Midjourney、sd是不是会被替代?这些AI绘图工具是不是要淘汰了?
但我只想说一句话:
只要这些模型的公司还在挣咱们的钱,他们自己就会不断升级迭代、相互内卷。
GPT-4o强,Midjourney V7 也强,各自发挥各自的优势,只会让我们这些创作者有更多、更好用的工具可选。
所以,不用焦虑、不用担心白学,我们真正该关心的是如何用合适的AI工具给我们创造真正的价值,保持自己清晰的认知与判断


















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









