






从理论到实践:理解 RAG、代理(Agent)、微调(Fine-Tuning)等
为什么要定制 LLM?
大语言模型(LLM, Large Language Model)是一类基于自监督学习(Self-Supervised Learning) 预训练的深度学习模型。在训练数据、训练时间以及模型参数规模上,这类模型需要大量资源。近年来,LLM 在自然语言处理(NLP) 领域取得了革命性进展,尤其是在过去两年中,展现出了卓越的理解和生成类人文本的能力。然而,这些通用模型 的默认性能并不总是能满足特定业务需求或行业要求。
LLM 无法回答依赖于企业私有数据或封闭知识库 的问题,因此在应用上相对通用。此外,从零开始训练 LLM 对于中小型团队来说几乎不可行,因为这需要海量的训练数据和计算资源。因此,近年来涌现出了多种LLM 定制策略,以便在需要专业知识的各种场景下优化模型。
LLM 定制策略主要分为两类
-
使用冻结模型(Frozen Model)
-
这类技术不需要更新模型参数,通常通过上下文学习(In-Context Learning) 或提示工程(Prompt Engineering) 来实现。
-
由于无需进行大规模训练,成本较低,因此被广泛应用于工业界和学术界,每天都有新的研究论文发表。
-
-
更新模型参数(Updating Model Parameters)
-
这是一种相对资源密集的做法,需要使用特定的数据集 对预训练 LLM 进行微调(Fine-Tuning)。
-
典型方法包括微调(Fine-Tuning) 和 人类反馈强化学习(RLHF, Reinforcement Learning from Human Feedback)。
-
这两大定制范式进一步分化为多种专业化技术,包括:
-
LoRA 微调(LoRA Fine-Tuning)
-
链式思维(Chain of Thought, CoT)
-
检索增强生成(Retrieval Augmented Generation, RAG)
-
ReAct(Synergizing Reasoning and Acting)
-
代理(Agent)框架
每种技术在计算资源、实现复杂性和性能提升 方面各有优劣。
如何选择 LLM?
定制 LLM 的第一步是选择合适的基础模型 作为基准。社区平台(例如 Hugging Face)提供了大量由顶级公司或社区贡献的开源预训练模型,例如:
-
Meta 的 Llama 系列
-
Google 的 Gemini
Hugging Face 还提供排行榜,例如 "Open LLM Leaderboard",通过行业标准指标(如 MMLU) 对 LLM 进行比较。
此外,云服务提供商(如 AWS)和 AI 公司(如 OpenAI 和 Anthropic)也提供专有模型(Proprietary Models),这些模型通常是付费服务,并带有访问限制。
选择 LLM 时需要考虑以下因素:
-
开源模型 vs. 专有模型
-
开源模型:支持完全定制和自托管,但需要较高的技术能力。
-
专有模型:提供即用型 API,通常质量更高,但成本较高。
-
-
任务与指标(Task & Metrics)
-
不同模型在问答、摘要、代码生成 等任务上的表现不同。
-
可以通过基准测试指标和领域任务测试来选择最合适的模型。
-
-
架构(Architecture)
-
仅解码架构(Decoder-Only,如 GPT):在文本生成任务 上表现更佳。
-
编码-解码架构(Encoder-Decoder,如 T5):在翻译任务 上效果更好。
-
专家混合(Mixture of Experts, MoE)模型(如 DeepSeek) 也正在展现良好潜力。
-
-
参数规模(Number of Parameters & Size)
-
大模型(70B-175B 参数):性能更强,但计算资源需求高。
-
小模型(7B-13B 参数):运行更快、成本更低,但能力可能有所降低。
-
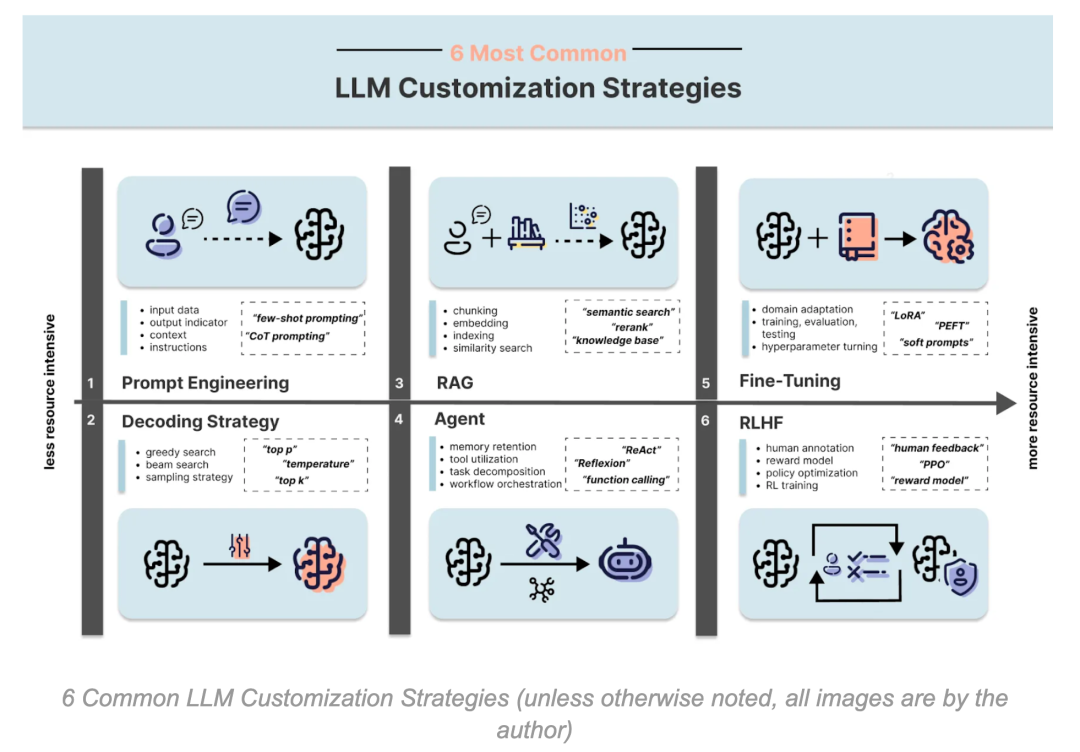
6 种常见的 LLM 定制策略
确定基础 LLM 之后,我们可以探索6 种最常见的 LLM 定制策略,按资源消耗从低到高排序:
-
提示工程(Prompt Engineering)
-
解码与采样策略(Decoding and Sampling Strategy)
-
检索增强生成(Retrieval Augmented Generation, RAG)
-
代理(Agent)
-
微调(Fine-Tuning)
-
人类反馈强化学习(RLHF, Reinforcement Learning from Human Feedback)
1. 提示工程(Prompt Engineering)
提示(Prompt) 是发送给 LLM 的输入文本,用于引导 AI 生成响应。提示通常包括以下四个部分:
-
指令(Instructions):描述任务或提供执行指南。
-
上下文(Context):提供额外信息,以限制模型的回答范围。
-
输入数据(Input Data):具体的问题或任务输入。
-
输出指示(Output Indicator):指定输出的格式或类型。
提示工程的核心在于优化提示的结构,以更好地控制模型输出。
常见的提示工程技术
-
零样本(Zero-Shot Prompting):直接输入问题,模型自行推理答案。
-
单样本(One-Shot Prompting):提供一个示例,指导模型如何回答。
-
少样本(Few-Shot Prompting):提供多个示例,以提高响应质量。
由于提示工程的高效性和低成本,研究人员开发了更复杂的方法,以增强提示的逻辑结构,例如:
-
链式思维(Chain of Thought, CoT)
-
让 LLM 将复杂推理任务拆解为多个步骤,提高连贯性和准确性。
-
每一步输出的推理结果都会成为下一步的输入,直到得出最终答案。
-
-
思维树(Tree of Thoughts, ToT)
-
在 CoT 的基础上,探索多条推理路径,并自评选择最佳行动。
-
适用于需要决策规划和探索多种解决方案 的任务。
-
-
自动推理与工具使用(ART, Automatic Reasoning and Tool-Use)
-
结合 CoT,并允许模型调用外部工具(如搜索、代码生成)以完成任务。
-
-
ReAct(Synergizing Reasoning and Acting)
-
结合推理路径和“行动空间”,根据环境反馈动态调整模型行为。
-
CoT 和 ReAct 等技术通常与代理(Agent)框架结合使用,以进一步增强模型能力。
2. 解码与采样策略(Decoding and Sampling Strategy)
解码策略(Decoding Strategy) 可在推理(Inference) 阶段控制 LLM 的输出方式,影响文本的随机性和多样性。常见的解码策略包括:
(1)贪心搜索(Greedy Search)
-
直接选择概率最高的 token 作为下一个输出。
-
优点:计算速度快,适用于结构化任务(如填充缺失单词)。
-
缺点:可能导致模型输出单调,缺乏创造力。
(2)束搜索(Beam Search)
-
维护 k 个候选路径(beam size),每步选择最优的k 个 token 组合,最终选择最高概率的句子。
-
优点:比贪心搜索更全面,适用于翻译等任务。
-
缺点:计算量较大,仍可能生成重复文本。
(3)采样策略(Sampling Strategy)
采样策略通过调整模型推理参数 来增加生成文本的随机性和创造力。
① 温度(Temperature)
-
降低温度(Temperature → 0):增加高概率词的选择,减少随机性(类似贪心搜索)。
-
提高温度(Temperature → 1):增加随机性,生成更具创造性的文本。
-
示例:
outputs = model.generate(**inputs, temperature=0.7)
② Top-K 采样(Top-K Sampling)
-
仅从 K 个最可能的 token 中进行采样,忽略概率较低的 token。
-
示例:
outputs = model.generate(**inputs, top_k=50)
③ Top-P 采样(Nucleus Sampling)
-
选择累计概率大于 p 的最小 token 集合 进行采样。
-
Top-P vs. Top-K:
-
Top-K 固定选择 k 个 token,可能会忽略更适合上下文的低概率 token。
-
Top-P 动态调整选择范围,更适用于灵活生成任务。
-
-
示例:
outputs = model.generate(**inputs, top_p=0.95)
3. 检索增强生成(Retrieval Augmented Generation, RAG)
检索增强生成(RAG) 结合 LLM 与外部知识库,减少“幻觉”(hallucination)问题,提升对特定领域问题 的回答能力。
RAG 的主要流程
RAG 主要包括 “检索(Retrieval)” 和 “生成(Generation)” 两个阶段:
(1)检索阶段
-
文档切分(Chunking):将外部知识拆分成小块。
-
创建嵌入向量(Embeddings):将文本转换为向量表示。
-
索引存储(Indexing):存储文本与向量,支持高效检索。
-
相似度搜索(Similarity Search):匹配最相关的文档 以增强模型的回答。
(2)生成阶段
-
结合检索到的信息 与 用户查询,生成更精准的答案。
示例代码(RAG 实现)
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import VectorStoreIndex
# 设定 LLM & 嵌入模型
Settings.llm = OpenAI(model="gpt-3.5-turbo")
Settings.embed_model = "BAAI/bge-small-en-v1.5"
# 创建索引
document = Document(text="\n\n".join([doc.text for doc in documents]))
index = VectorStoreIndex.from_documents([document])
query_engine = index.as_query_engine()
# 进行查询
response = query_engine.query("Tell me about LLM customization strategies.")4. 代理(Agent)
LLM 代理(Agent) 超越了 RAG 的能力,能够自主规划任务、调用工具并维护对话状态,适用于更复杂的任务管理。
代理的核心能力
-
维护记忆和状态,跟踪上下文信息。
-
调用外部工具(如 API、数据库、计算工具)。
-
分解复杂任务,规划执行步骤。
-
与其他代理协作,形成多代理系统。
ReAct 框架(Synergizing Reasoning and Acting)
-
结合推理(Reasoning) 和 行动(Action),让 LLM 具备决策能力。
-
由 Google Research & Princeton 提出,基于 Chain of Thought 发展而来。
示例代码(ReAct 代理实现)
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
# 创建代理工具
def multiply(a: float, b: float) -> float:
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
def add(a: float, b: float) -> float:
return a + b
add_tool = FunctionTool.from_defaults(fn=add)
# 定义代理
agent = ReActAgent.from_tools([multiply_tool, add_tool], llm=llm, verbose=True)5. 微调(Fine-Tuning)
微调(Fine-Tuning) 通过训练专有数据集,调整 LLM 权重,使其更符合特定任务需求。
PEFT(参数高效微调)
为了降低计算成本,研究人员提出参数高效微调(PEFT, Parameter-Efficient Fine-Tuning) 方法,例如:
-
LoRA(低秩适配):减少参数更新数量,加速微调。
-
适配器(Adapters):添加可训练层,而不修改原模型参数。
示例代码(使用 Hugging Face 进行微调)
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir=output_dir,
learning_rate=1e-5,
eval_strategy="epoch"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()6. 人类反馈强化学习(RLHF)
人类反馈强化学习(RLHF, Reinforcement Learning from Human Feedback) 通过人类偏好数据训练奖励模型,优化 LLM 的回答质量。
RLHF 训练流程
-
收集人类偏好数据,标注高质量回答。
-
训练奖励模型,预测回答的质量得分。
-
使用强化学习(PPO 算法)优化 LLM,提高模型对人类偏好的匹配度。
示例代码(使用 Trlx 进行 RLHF 训练)
from trl import PPOTrainer, PPOConfig, AutoModelForSeq2SeqLMWithValueHead
# 定义强化学习参数
config = PPOConfig(
model_name=model_name,
learning_rate=learning_rate,
ppo_epochs=max_ppo_epochs,
mini_batch_size=mini_batch_size,
batch_size=batch_size
)
# 训练 RLHF 模型
ppo_trainer = PPOTrainer(
config=config,
model=ppo_model,
tokenizer=tokenizer,
dataset=dataset["train"]
)
ppo_trainer.step(query_tensors, response_tensors, rewards)📌 总结:6 种 LLM 定制策略对比
下表总结了六种 LLM 定制策略的 特点、适用场景、优缺点,帮助你快速选择最适合的方案:
| 方法 | 特点 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 提示工程(Prompt Engineering) | 通过优化输入提示来调整 LLM 输出 | 快速调整模型行为(如问答、文本摘要) | 易于实现,零成本 | 依赖提示质量,无法长期记忆 |
| 解码 & 采样策略(Decoding & Sampling) | 调整推理参数(如温度、Top-K、Top-P) | 需要控制生成文本的随机性和创造力 | 不修改模型参数,计算开销低 | 无法改变模型知识 |
| 检索增强生成(RAG) | 在推理阶段动态检索外部知识 | 需要实时访问外部数据(如企业内部知识库) | 降低幻觉问题,适合封闭领域 | 依赖检索系统,查询速度可能受限 |
| 代理(Agent) | 具备记忆、决策和工具调用能力 | 复杂任务管理(如多步推理、自动化工作流) | 任务执行灵活,可调用外部工具 | 需要复杂的工作流设计 |
| 微调(Fine-Tuning) | 通过额外训练数据更新模型参数 | 需要长期适应特定领域(如医学、法律) | 提高领域适应性 | 计算成本较高,可能遗忘原始知识 |
| 人类反馈强化学习(RLHF) | 通过人类反馈优化模型行为 | 需要提升模型的道德性、可控性(如减少有害内容) | 提高对齐性,优化人类偏好 | 训练成本高,依赖大量标注数据 |
🔗 进一步阅读
如果你想更深入地研究 LLM 定制策略,可以参考以下论文和资源:
📖 提示工程
-
Chain-of-Thought Prompting: Elicits Reasoning in Large Language Models
-
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
📖 解码策略
-
Text Generation Strategies: Using Different Decoding Methods for Language Generation
📖 检索增强生成(RAG)
-
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks: Original RAG Paper
-
A Survey on RAG for Large Language Models: Comprehensive Research Overview
📖 代理(Agent)
-
NVIDIA: Introduction to LLM Agents: A Guide to Intelligent Agent Systems
📖 微调(Fine-Tuning)
-
LoRA: Low-Rank Adaptation for Efficient Fine-Tuning: Efficient Fine-Tuning Methods
📖 人类反馈强化学习(RLHF)
-
A Survey of Reinforcement Learning from Human Feedback: Comprehensive RLHF Review
🎯 结语
LLM 的定制正在快速发展,不同的应用场景适用于不同的优化方法。如果你的需求是:
-
快速调整模型行为 👉 提示工程
-
控制文本生成风格 👉 解码 & 采样策略
-
减少幻觉,提高专业性 👉 RAG
-
自动化任务 & 复杂决策 👉 代理(Agent)
-
长期适应特定领域 👉 微调(Fine-Tuning)
-
优化 LLM 道德性 & 可控性 👉 RLHF
希望这篇指南对你有所帮助!如果你有任何问题或想了解更多内容,欢迎继续交流!🚀



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









