







在SQL里编写复杂查询
1.子查询
用一条查询作为存在于另一个查询内部的子查询
SELECT *
FROM products
WHERE unit_price > (
SELECT unit_price
FROM products
WHERE product_id = 3
) -- 在WHERE子句中编码了子查询当MySQL试图执行这条查询,首先它会评估我们的内查询或者子查询(它会获取生菜的单价 ),然后把结果传给我们的外查询
我们也可以在FROM子句或者SELECT子句中编写子查询
SELECT *
FROM employees
WHERE salary > (
SELECT AVG(salary) FROM employees
)在 SQL 中,聚合函数(如 SUM(), AVG(), MIN(), MAX(), COUNT() 等)通常在 GROUP BY 子句中使用,用于对一组数据进行计算。然而,在这个查询中,尝试直接在 WHERE 子句中使用 AVG(salary) 来筛选出工资高于平均工资的员工,这是不允许的。
要解决这个问题,你可以使用子查询来先计算平均工资,然后在 WHERE 子句中使用这个结果。
2.IN运算符
如何用IN写子查询(返回值大于1时使用)
USE sql_store;
SELECT *
FROM products
WHERE product_id NOT IN(
SELECT DISTINCT product_id
FROM order_items
)
1.2的子查询返回了一个单一值; 在这个例子中,我们的子查询返回了一个列表的值
消除重复项用DISTINCT
3.子查询VS连接
- 使用子查询VS连接,由表现和可读性决定
- 在运行时间相同时,应该选择最易读的连接
SELECT *
FROM clients
WHERE client_id NOT IN(
SELECT DISTINCT client_id
FROM invoices);
SELECT *
FROM clients
LEFT JOIN invoices using (client_id)
WHERE invoice_id IS NULLSELECT customer_id, first_name, last_name
FROM customers
WHERE customer_id IN (
SELECT o.customer_id
FROM order_items oi
JOIN orders o USING (order_id)
WHERE product_id = 3)SELECT DISTINCT customer_id, first_name, last_name
FROM customers c
JOIN orders o USING (customer_id)
JOIN order_items oi USING (order_id)
WHERE oi.product_id = 33.3比3.2更易读,它更有意义因为customers orders和orders item之间有一种自然关联
4.ALL关键字
SELECT *
FROM invoices
WHERE invoice_total > (
SELECT MAX(invoice_total)
FROM invoices
WHERE client_id = 3
) -- 大于客户3所有发票额的发票其实还有一种方法可以解决这个问题,就是使用ALL关键字
SELECT *
FROM invoices
WHERE invoice_total > ALL (
SELECT invoice_total
FROM invoices
WHERE client_id = 3
)-- 子查询返回了一系列值MYSQL会查看发票表,每行都会把发票总额和这些数字作比较,如果发票总额大于所有这些值,那么那行就会返回在最终结果集,这就是ALL关键词的操作原理
俩种方法可以互换,每当你用了ALL关键字,都可以用MAX聚合函数改写(两种查询都很易读)
5.ANY关键字
MySQL里还有ANY或者SOME关键字,这俩是一样的
SELECT *
FROM invoices
WHERE invoice_total > SOME(
SELECT invoice_total
FROM invoices
WHERE client_id = 3
)使用这些关健字可以得到发票总额高于这段子查询返回的任意值的行
=ANY运算符 与 IN运算符 等效,选择哪种方法只要你开心都行
SELECT *
FROM clients
WHERE client_id = ANY( -- 也可以用IN
SELECT client_id
FROM invoices
GROUP BY client_id
HAVING COUNT(*)>= 2
)6.相关子查询
伪代码 (长得像代码却不是代码,只是白话英语罢了)
-- for each employee
-- calculate the avg salary for employee.office
-- return the employee if salary > avg
没有每个id都采取一样的平均值时,采用相关子查询
SELECT *
FROM employees e -- 对于每个员工执行计算与他的同一部门员工平均工资,符合条件的再返回最终结果
WHERE salary > (
SELECT AVG(salary)
FROM employees
WHERE office_id = e.office_id -- 计算同一个部门员工的平均工资
)我们把这称为:相关子查询,因为这段子查询和外查询存在相关性(为同一个表,外查询的表要加别名来区分),相比之下所有我们以前写的子查询都是非关联子查询(子查询里没有外查询的引用也没有和外查询有相关性)
非关联子查询中,MY SQL只会执行一次子查询,子查询返回了一系列客户id 它们会被赋值到外查询或者主查询的WHERE子句中
相比较,我们使用相关子查询的时候,这段查询会在主查询每一行的层面执行。因此,相关子查询通常执行得很慢,数据越多查询更费力,也会占用更多的存储。
7.EXISTS运算符
SELECT *
FROM clients c
WHERE EXISTS(
SELECT client_id
FROM invoices
WHERE client_id = c.client_id
)使用EXISTS运算符,来查看发票表里是否存在符合这个条件的行
当MY SQL执行时,对于客户表里的每一位客户它都会检查是否存在一条符合这个条件的记录
使用IN时,子查询里面生成列表(A,B,C,D.........),数据很多时,会妨碍最佳性能,使用EXISTS运算符能够提高效率
当我们使用EXISTS时,子查询并没有给外查询返回一个结果(不会先返回一个结果集),它会返回一个指令说明这个子查询中是否有符合这个搜索条件的行(只要它找到这个表中有一条匹配这个条件的记录,它就会返回 TRUE给EXISTS运算符,然后这个EXISTS运算符就会在最终结果里添加当前记录,也就是当前客户) 先TRUE,再被添加到结果集(从后往前)
SELECT *
FROM products p
WHERE NOT EXISTS(
SELECT product_id
FROM order_items
WHERE product_id = p.product_id
)
SELECT *
FROM products
WHERE product_id NOT IN (
SELECT product_id
FROM order_items
)8.SELECT子句中的子查询
- 表达式中不能用列的别名,解决方法:
- (复制整段子查询)
- (SELECT 列别名)
SELECT
invoice_id,
invoice_total,
(SELECT AVG(invoice_total)
FROM invoices) AS invoice_average,
invoice_total - (SELECT invoice_average) AS difference-- 用(SELECT 列名)
FROM invoices
SELECT
invoice_id,
invoice_total,
(SELECT AVG(invoice_total)
FROM invoices) AS invoice_average,
invoice_total - (SELECT AVG(invbice_total)
FROM invoices) -- 把上面整个表达子句复制下来
FROM invoices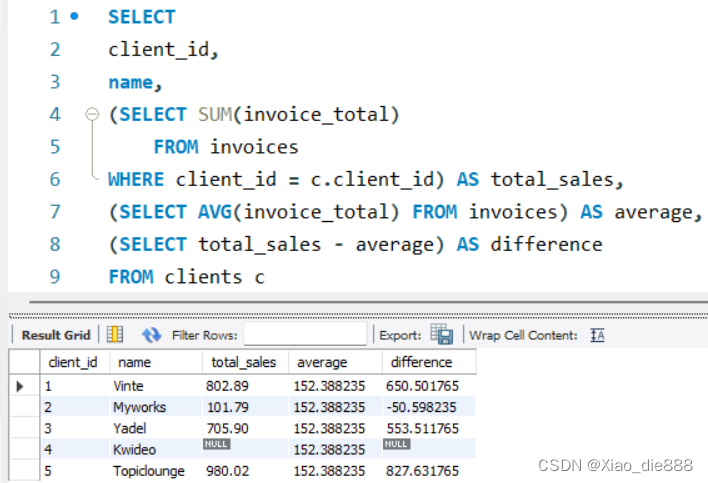
9.FROM子句中的子查询
- 可以在FROM中写子查询,但仅限于简单的查询
- 一定需要添加别名
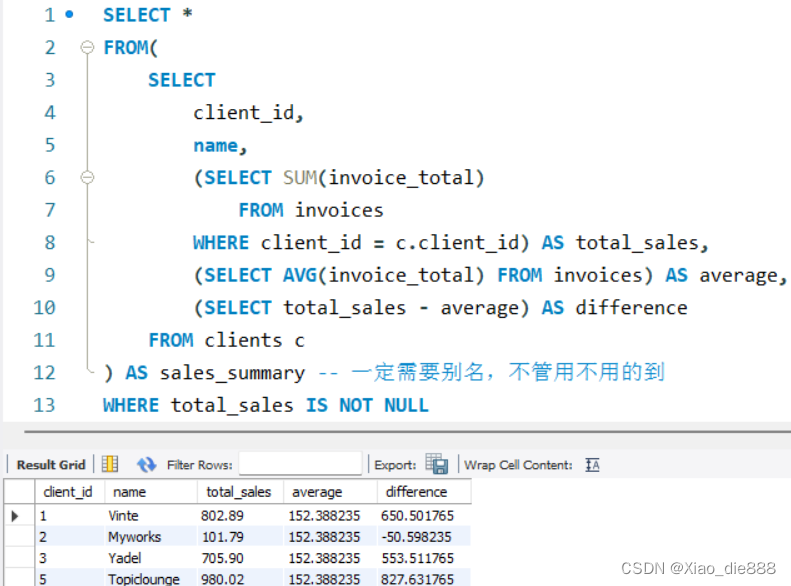
在选择语句的FROM字句中写子查询,会让我们的主查询变得更复杂,一个更好的解决方法是使用视图,所以我们可以使用这段查询,作为视图存储在数据库中,我们可以在这个视图取名为“销售信息汇总”















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









