







 本文介绍了TensorFlow2.0中Keras的基本概念,包括Tensorflow-Keras与纯Keras的关系,以及它们在分类、回归问题和损失函数上的应用。实战部分涵盖Keras构建分类、回归模型,深度神经网络,wide&deep模型,以及使用Keras与scikit-learn进行超参数搜索。文章强调了Tensorflow-Keras在实验中的优势,并提供了多个模型训练和调优的例子。
本文介绍了TensorFlow2.0中Keras的基本概念,包括Tensorflow-Keras与纯Keras的关系,以及它们在分类、回归问题和损失函数上的应用。实战部分涵盖Keras构建分类、回归模型,深度神经网络,wide&deep模型,以及使用Keras与scikit-learn进行超参数搜索。文章强调了Tensorflow-Keras在实验中的优势,并提供了多个模型训练和调优的例子。
1、内容结构
- 内容如何安排
- 实战与理论并存,实战为主,理论为辅
- 小知识点第一次遇见会讲
- 大知识点独立为一个小节
- 代码的TensorFlow版本
- 大部分都是tf2.0
- 课程以tf.keras API为主,因而部分代码可以在tf1.3+运行
- 另有少量tf1.*版本代码(方便大家读懂老代码)
2、理论部分
- Tensorflow-keras简介;
- 分类问题、回归问题、损失函数;
- 神经网络、激活函数、批归一化、Dropout;
- Wide & deep 模型;
- 超参数搜索
2.1、Tensorflow-keras简介
2.1.1、keras是什么
- 基于python的高级神经网络API;
- Francois Chollet于2014-2015年编写keras;
- 以Tensorflow、CNTK或者Theano为后端运行,keras必须有后端才可以运行;
- 后端可以切换,现在多用TensorFlow
- 极方便于快速实验,帮助用户以最少的时间验证自己的想法;
2.1.2、Tensorflow-keras是什么
- Tensorflow对keras API规范的实现;
- 相对于以Tensorflow为后端的keras,Tensorflow-keras与Tensorflow结合更加紧密;
- 实现在tf.keras空间下;
2.1.3、Tensorflow-keras和keras的联系
- 基于同一套API
- keras程序可以通过改导入方式轻松转为tf.keras程序;
- 反之可能不成立,因为tf.keras有其他特性;
- 相同的JSON和HDF5模型序列化格式和语义;
2.1.4、Tensorflow-keras和keras的区别
- Tf.keras全面支持eager mode
- 只是用keras.Sequential和keras.Model时没影响
- 自定义Model内部运算逻辑的时候会有影响
- Tf低层API可以使用keras的model.fit等抽象
- 适用于研究人员
- Tf.keras支持基于tf.data的模型训练;
- Tf.keras支持TPU训练;
- Tf.keras支持tf.distribution中的分布式策略;
- 其他特性
- Tf.keras可以与Tensorflow中的estimator集成
- Tf.keras可以保存为SavedModel
2.1.5、Tensorflow-keras和keras如何选择
- 如果想用tf.keras的任何一个特性,那么选tf.keras;
- 如果后端互换性很重要,那么选择keras;
- 如果都不重要,那就随便。
2.2、分类问题、回归问题、损失函数
2.2.1、分类问题、回归问题
- 分类问题预测的是类别,模型的输出是概率分布
- 三分类问题输出例子:[0.2,0.7,0.1]
- 回归问题预测的是值,模型的输出是一个实数值
2.2.2、目标函数
为什么需要目标函数?
- 参数是逐步调整的
- 目标函数可以帮助衡量模型的好坏
- Model A:[0.1,0.4,0.5]
- Model B:[0.1,0.2,0.7]
分类问题:
- 需要衡量目标类别与当前预测的差距
- 三分类问题输出例子:[0.2,0.7,0.1] (1 ->one_hot -> [0,1,0])
- 三分类真实类别:2 -> one_hot -> [0,0,1]
- One-hot编码,把正整数变为向量表达
- 生成一个长度不小于正整数的向量,只有正整数的位置处为1,其余位置都为0
- 分类问题损失函数
- 平方差损失;
- 交叉熵损失;
- 平方差损失举例
- 预测值:[0.2,0.7,0.1]
- 真实值:[0,0,1]
- 损失函数值:[(0.2-0)^2 + (0.7-0) ^2 + (0.1-1) ^2 ] * 0.5 = 0.67
回归问题:
- 预测值与 真实值的差距
- 平方差损失
- 绝对值损失
模型的训练就是调整参数,使得目标函数逐渐变小的过程
3、实战部分
- Keras搭建分类模型;
- Keras回调函数;
- Keras搭建回归模型;
- Keras搭建深度神经网络;
- Keras实现wide&deep模型;
- Keras与scikit-learn实现超参数搜索。
3.1、Keras搭建分类模型
3.1.1、数据读取与展示
先导入各种需要的库
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
#import keras
查看导入的库的版本信息
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)
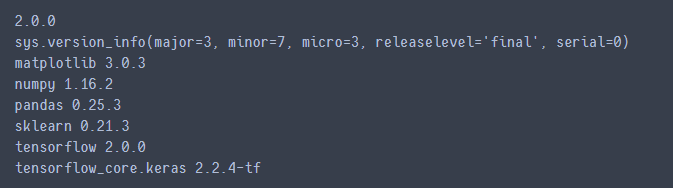
查看使用的数据集的结构
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data()
x_valid,x_train = x_train_all[:5000],x_train_all[5000:] #前5000张做验证集 后55000做训练集
y_valid,y_train = y_train_all[:5000],y_train_all[5000:] #前5000张做验证集 后55000做训练集
print(x_valid.shape,y_valid.shape)
print(x_train.shape,y_train.shape)
print(x_test.shape,y_test.shape)
看一下数据集里面的图片是什么样的(了解数据集是机器学习很重要的一部分)
#定义一个函数,可以显示一张图像
def show_single_image(img_arr):
plt.imshow(img_arr,cmap="binary") #这里是灰度图,其他图像具体参数请百度imshow()函数
plt.show()
show_single_image(x_train[0])

查看多张照片
#显示很多张图片
def show_image(n_rows, n_cols, x_data, y_data, class_names):
assert len(x_data) == len(y_data) #验证x样本数和y样本数一样
assert n_rows * n_cols < len(x_data) #验证行和列的乘积不能大于样本数
plt.figure(figsize = (n_cols * 1.4, n_rows * 1.6)) #定义一张大图1.4 1.6 就是缩放的图片
for row in range(n_rows):
for col in range(n_cols):
index = n_cols * row + col #计算当前位置图片的索引
plt.subplot(n_rows, n_cols, index + 1) #大图上画子图(之前index是从0开始的,这里要从1开始)
plt.imshow(x_data[index], cmap="binary", interpolation='nearest') #interpolation缩放图片时,插值的方法
plt.axis('off') #坐标系关掉
plt.title(class_names[y_data[index]]) #给每一张小图都加上title
plt.show()
class_names = ['T-shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
show_image(3, 5, x_train, y_train, class_names)

3.1.2、模型构建
#tf.keras.models.Sequential()
'''
#构建模型
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape = [28, 28]))
model.add(keras.layers.Dense(300, activation = "relu"))
model.add(keras.layers.Dense(100, activation = "relu"))
model.add(keras.layers.Dense(10, activation = "softmax"))
'''
#模型构建的另一种等价写法
model = keras.models.Sequential([
keras.layers.Flatten(input_shape = [28, 28]), #将输入为28 * 28的图像展开(28*28的二维矩阵展成784的一维向量)
keras.layers.Dense(300, activation = "relu"),
keras.layers.Dense(100, activation = "relu"),
keras.layers.Dense(10, activation = "softmax")
])
# relu: y = max(0, x)
# softmax: 将变量变成概率分布。 x = [x1,x2,x3],
# y = [e^x1/sum, e^x2/sum, e^x3/sum, sum = e^x1 + e^x2 + e^x3]
# reason for sparse: y->index. y->one_hot->[]
model.compile(loss = "sparse_categorical_crossentropy", #如果y已经是向量了就用categorical_crossentropy",如果是数字就用sparse_
optimizer = "adam",
metrics = ["accuracy"])
查看模型层数
model.layers

查看模型概况
model.summary()

训练模型
'''
[None, 784] * w + b -> [None, 300] 其中,w.shape->[784,300], b = [300]
'''
history = model.fit(x_train, y_train, epochs=10, validation_data = (x_valid, y_valid))

3.1.3、模型训练参数查看
history.history #查看history里面存储的一些值
绘图查看history中的变量变化过程
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8,5)) #将数据转换成DataFrame,然后调用plot实现
plt.grid(True) #绘制网格
plt.gca().set_ylim(0, 1) #设定y坐标的范围
plt.show()
plot_learning_curves(history)

3.1.4、数据归一化处理
归一化分两种,数据归一化,批归一化
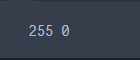
查看归一化之前数据的最大值最小值
print(np.max(x_train), np.min(x_train))
数据归一化
#数据归一化
# x = (x - u) / std
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# x_train:[None, 28, 28] -> [None, 784]
x_train_scaler = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) #之前数据是int的,因为要做除法,所以先转换成float32的
#scaler.fit_transform()函数要求输入参数是二维数据,
#所以先变成二维数据,然后再变回三维数据
#scaler.fit_transform()函数有fit功能,记录训练的均值和方差(因为后面验证集和测试集数据归一化的时候,都要使用训练集的均值和方差)
#验证集和测试集归一化,用scaler.transform()即可
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









