






什么是推荐系统?推荐系统属于资讯过滤的一种应用。推荐系统能够将可能受喜好的资讯或实物(例如:电影、电视节目、音乐、书籍、新闻、图片、网页)推荐给使用者。
推荐系统首先收集用户的历史行为数据,然后通过预处理的方法得到用户-评价矩阵,再利用机器学习领域中相关推荐技术形成对用户的个性化推荐。有的推荐系统还搜集用户对推荐结果的反馈,并根据实际的反馈信息实时调整推荐策略,产生更符合用户需求的推荐结果。
推荐系统的作用:
- 将网站的浏览者转为购买者或者潜在购买者(购物车);
- 提高购物网站的交叉销售能力和成交转化率;
- 提高客户对网站的忠诚度和帮助用户迅速找到产品。
推荐系统的表现形式:
- Browsing:客户提出对特定商品的查询要求,推荐系统根据查询要求返回高质量的推荐;
- Similar Item:推荐系统根据客户购物篮中的商品和客户可能感兴趣的商品推荐类似的商品;
- Email:推荐系统通过电子邮件的方式通知客户可能感兴趣的商品信息;
- Text Comments:推荐系统向客户提供其他客户对相应产品的评论信息;
- Average Rating:推荐系统向客户提供其他客户对相应产品的等级评价 ;
- Top-N:推荐系统根据客户的喜好向客户推荐最可能吸引客户的N件产品 ;
- Ordered Search Results:推荐系统列出所有的搜索结果,并将搜索结果按照客户的兴趣降序排列。
推荐技术分类:
- 基于用户统计信息的推荐;
- 基于其他客户对该产品的平均评价,这种推荐系统独立于客户,所有的客户得到的推荐都是相同的(Non-Personalized Recommendation);
- 基于产品的属性特征(Attributed-Based Recommendation);
- 根据客户感兴趣的产品推荐相关的产品(Item-to-Item Correlation);
- 协同过滤,推荐系统根据客户与其他已经购买了商品的客户之间的相关性进行推荐(People-to-People Correlation)。
推荐系统的数据分类:
- explicit(显式):能准确的反应用户对物品的真实喜好,但需要用户付出额外的代价。如:用户收藏、用户评价。
- Implicit(隐式):通过一些分析和处理,才能反映用户的喜好。如:用户浏览、用户页面停留时间、访问次数。
推荐系统算法介绍:
谈到推荐系统,当然离不开它的核心 —— 推荐算法。推荐算法最早在1992年就提出来了,但是发展起来是最近这些年的事情,因为互联网的爆发,有了更大的数据量可以供我们使用,推荐算法才有了很大的用武之地。
下面我们分别来介绍几种常用的推荐算法:
基于用户统计信息的推荐:
描述
这是最为简单的一种推荐算法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。
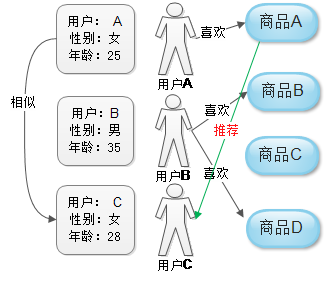
系统首先根据用户的类型,比如按照年龄、性别、兴趣爱好等信息进行分类。根据用户的这些特点计算形似度和匹配度。如图,发现用户A和B的性别一样,年龄段相似,于是推荐A喜欢的商品给C。
优点:
a 不需要历史数据,没有冷启动问题;
b 不依赖于物品的属性,因此其他领域的问题都可无缝接入。
不足:
算法比较粗糙,效果很难令人满意,只适合简单的推荐。
基于内容的推荐(Content-based Recommendation)
描述:
基于内容的推荐是建立在产品的信息上作出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机 器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。
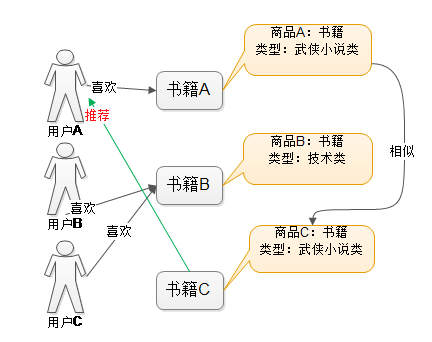
系统首先对商品书籍的属性进行建模,图中用类型作为属性。在实际应用中,只根据类型显然过于粗糙,还需要考虑其他信息。通过相似度计算,发现书籍A和C相似度较高,因为他们都属于武侠小说类。系统还会发现用户A喜欢书籍A,由此得出结论,用户A很可能对书籍C也感兴趣。于是将书籍C推荐给A。
示例:
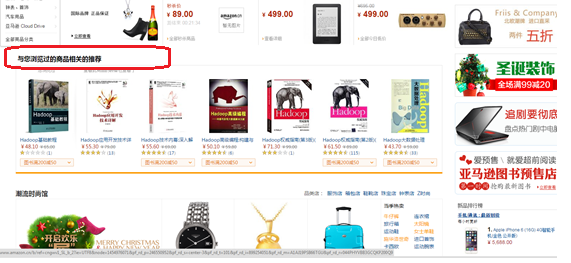
下面是亚马逊中国的一个例子,未登录用户浏览了关于Hadoop的书籍,于是在首页会出现如下相关产品的推荐:
优点:
- 对用户兴趣可以很好的建模,并通过对商品和用户添加标签,可以获得更好的精确度;
- 能为具有特殊兴趣爱好的用户进行推荐。
不足:
- a. 物品的属性有限,难以区分商品信息的品质;
- b. 物品相似度的衡量标准只考虑到了物品本身,有一定的片面性;
c . 不能为用户发现新的感兴趣的产品。
协同过滤推荐(Collaborative Filtering Recommendation)
背景:
协同过滤的场景是这样的:要为某用户推荐他真正感兴趣的内容/商品,首先要找到与此用户有相似兴趣的其他用户,然后将他们感兴趣的内容推荐给该用户。协同过滤就是利用这个思想,基于其他用户对某一个内容的评价来向目标客户进行推荐。
基于协同过滤的推荐系统可以说是从用户的角度来进行相应的自动的推荐,即用户获得的推荐是系统从购买模式或浏览行为等隐式获得的。
比较:
这里你是否觉得协同过滤推荐和基于用户统计信息的推荐以及基于内容的推荐有很多相似之处呢?下面我们先来比较一下协同过滤推荐和上述两种推荐的区别。
ü 协同过滤推荐 VS 基于用户统计信息推荐
基于用户的协同过滤推荐机制和基于用户统计信息推荐机制都是计算用户的相似度,并基于“邻居”用户群计算推荐,但它们所不同的是如何计算用户的相似度,基 于用户统计信息只考虑用户本身的特征,而基于用户的协同过滤机制是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户 可能有相同或者相似的兴趣爱好。
ü 系统过滤推荐 VS 基于内容的推荐
基于项目的协同过滤推荐和基于内容的推荐其实都是基于物品相似度预测推荐,只是相似度计算的方法不一样,前者是从用户历史的偏好推断,而后者是基于物品本身的属性特征信息。
描述:
协同过滤算法,顾名思义就是指用户可以齐心协力,通过不断的和网站互动,是自己的推荐列表能够不断过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。
协同过滤算法主要有两种,一种是基于用户的协同过滤算法(UserCF),另一种是基于物品的协同过滤算法(ItemCF)。















 3235
3235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









