







Batch normalization in Neural Networks
Deeplearning.ai: Why Does Batch Norm Work? (C2W3L06)
Fitting Batch Norm into a Neural Network
对每个隐层的输入
z(l),a(l)
z
(
l
)
,
a
(
l
)
做归一化(减去均值除以标准差),再用
β,γ
β
,
γ
进行重缩放:



为什么BN?
Covariate shift
To explain covariance shift, let’s have a deep network on cat detection. We train our data on only black cats’ images. So, if we now try to apply this network to data with colored cats, it is obvious; we’re not going to do well. The training set and the prediction set are both cats’ images but they differ a little bit. In other words, If an algorithm learned some X to Y mapping, and if the distribution of X changes, then we might need to retrain the learning algorithm by trying to align the distribution of X with the distribution of Y. This is true even when the ground truth function mapping from X to Y remains unchanged.
针对检测图像中的猫的任务,如果我们的训练集中只有黑猫的图片,训练出来的神经网络运用到彩色猫的图片上时显然不会表现很好。训练集和测试集尽管都是猫的图片,但是他们又有所区别。换句话说,如果一个算法学习了X到Y的映射,当X的分布改变时,我们可能需要重新进行训练来适应这种输入分布的改变,即使真实的映射函数没有改变。
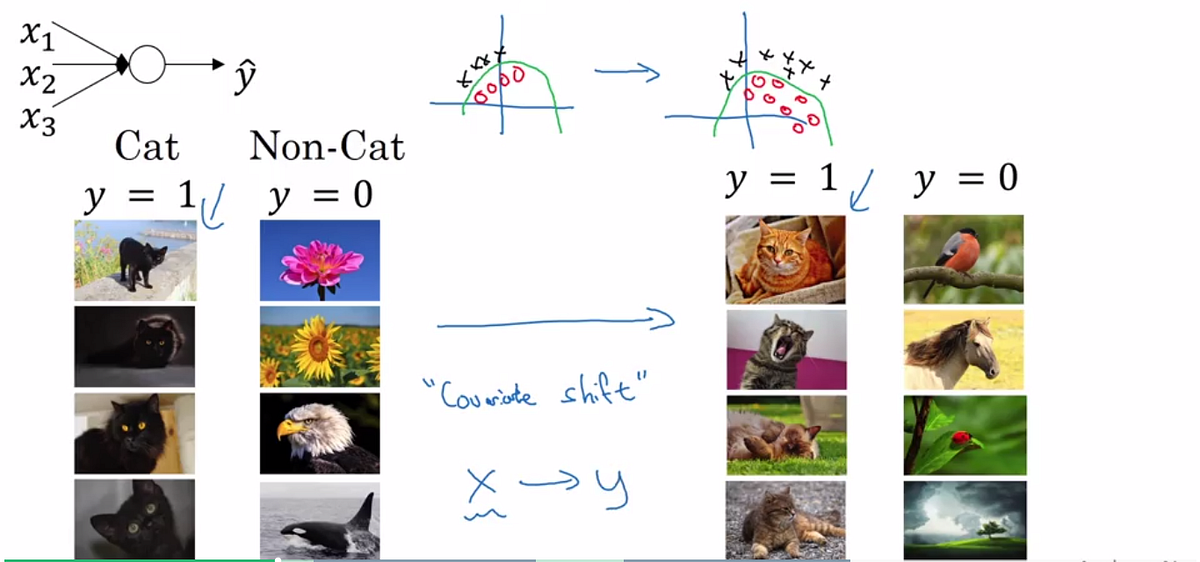
batch normalization allows each layer of a network to learn by itself a little bit more independently of other layers.
Batch normalization使得神经网络每层的学习能够相对的独立于其他层。
Why Batch Norm Works?
现在我们以
w(3),b(3)
w
(
3
)
,
b
(
3
)
的学习为例:



当前面层网络的参数改变时,会改变
a(3)
a
(
3
)
。
而
w(3),b(3)
w
(
3
)
,
b
(
3
)
是为了从
a(3)
a
(
3
)
估计
y
y
而学习的参数,因此也需要随之改变。



因此会有严重的covariate shift问题。
BN减少了隐藏层变化的幅度。

无论每层的输出怎么变,他们的均值和方差不会变(由 β β , γ γ 控制)。



BN算法削弱了前层参数和后面参数的耦合,允许网络的每一层独立学习,提升整个网络的训练速度。
由于前面层输出的均值和方差被限制了,他们的变化不会那么的大,后面的学习变得更加简单。
BN as regularization
此外BN还有轻微正则化作用:均值方差是在每个mini-batch上得到的,因此均值和标准差的估值存在噪声;normalize过程也有噪声。


给隐藏层增加噪声,使得downstream units不至于过分依赖前面的单元。

BN at test time
在测试时可能需要逐一测试样本,没有足够的样本去计算 μ μ 和 σ2 σ 2 。
解决办法:
利用训练集估算,估算的方法有很多种:记住训练时每个mini batch见到的
μ
μ
和
σ2
σ
2
,然后用指数加权平均来估算mu和sigma2。









利用指数加权平均
















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









