






基于图像处理的方法可以对垃圾图像进行分类处理,要求是原始数据必须有标记,通过收集具有标记的垃圾分类,可以满足图像分类算法对数据的要求。通过收集相关数据,并将这些数据利用降维的方式生成了新的图像数据,新生成的图像数据的维度为128*128,既可以满足算力较低的硬件环境下进行训练的需求,又可以满足系统的训练质量。在经过对神经网络调参,并进行多次实验,最终训练出来了分类准确率达到93%以上的模型,为以后的垃圾分类使用产品落地奠定了基础。
本人专注于软件开发,可以助你升学、就业、深造,我会定期发布对应的软件设计和内容,大家如果有开发需求,可以私信联系、评论,我看到一定就回。
资源链接
论文链接
数据集
1 引 言
1.1课题背景
如果可以通过自动化或者信息化的方式对垃圾进行分类,则可以有效提升垃圾分类效率,同时对循环经济和绿色经济产生积极影响。近些年,计算机视觉在分类问题上表现了较好的分类能力,在对垃圾分类的时候,可以采用对含有垃圾的图像进行处理,利用计算机视觉对垃圾进行处理,可以使用计算机图像学和深度学习的相关理论对垃圾进行分类。
1.2课题意义以及目标
垃圾分类对个人、社会、物业从业者等都有意义。对于住户来说,如果有一套垃圾分类系统,就可以帮助他们减轻垃圾分类工作,也不会因为垃圾分类错误而导致收到处罚;对于物业相关人员来说,如果住家户的垃圾分类正确合理,也可以降低垃圾处理人员的工作;对于垃圾回收站的工作人员来说,前期垃圾分类做的好,可以降低他们的工作负担,对于仍然需要进行分类的垃圾,他们也可以使用垃圾分类系统进行分类,提升垃圾处理效率。对于整个经济社会来讲,垃圾分类可以显著提升垃圾循环经济,比如可以使用垃圾发电,不仅可以处理垃圾,还可以带来新的经济增长点。对于国家来说,垃圾分类有助于提升垃圾的的治理水平,可以有效落实国家“碳达峰”目标。
2 基于机器学习的图像识别
2.1 机器学习研究步骤
机器学习的一般研究步骤描述如图2-1所示。

图2-1 机器学习研究步骤
2.2 图像识别的研究步骤
基于机器学习的图像识别的研究步骤和一般的机器学习步骤有很多类似的地方,但是在原始数据集的收集、数据的预处理上又有一些不同。比如和文本分析的不同是文本分析需要对原始文本进行分词、停用词处理、向量化表示,而图像则需要的是解析图像,首先将图像转化为矩阵表示,然后要对图像的原始数据进行压缩,可以使用更小的数据表示原始图像,然后对数据进行规整化,即将数据规整到一定范围内,一般是0到1之间,最后进行模型训练、模型评估、模型预测、应用解释等工作。
2.3 浅层神经网络
机器学习方法中按照模式的不同有连接主义和非连接主义两个流派。非连接主义以符号主义和逻辑推理为主要代表,而连接主义的机器学习以神经网络为主要代表。
Frank Rosenblatt在1957年提出了一个可以模仿人类神经的机器学习模型,最早被称为感知器,这是人类第一次提出神经网络。2006年,以Hinton在《自然》上面发表的深度学习的论文把神经网络的学习和研究推向了新的高潮。
神经网络的基本单元是一个神经元,神经元是一个由若干个输入和一个阈值函数以及输出组成的一个结构。神经元的内部表述用数学语言描述如下:

(2-1)
其中,w是神经元的权重,也是神经网络要训练的未知参数,x是输入,s是神经元的外部状态,用来控制神经元的内部状态,如果不需要的话可以设置为0,θ是一个用来控制神经元是否激活的阈值。神经元的输出是以u为自变量的函数,一般有阈值函数、sigmoid函数等。
神经网络一般由若干个输入和若干个输出层组成,最简单的是前馈性神经网络。前馈性神经网络中,每一层的神经输出都是下一层神经的输入,依次向前传递神经状态,最终输出结果。每一层的输入和上一层的输出之间的关系可以使用公式(2-1)来表示。前馈性网络的表示如图2-2所示。
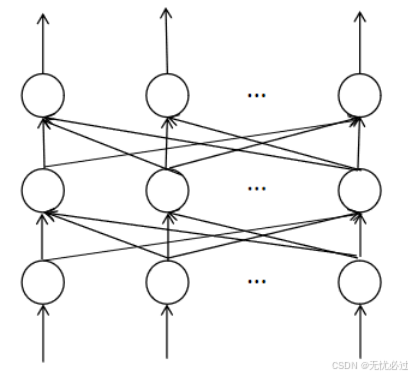
图2-2 前馈性神经网络示意图
前馈性神经网络可以使用反向传播算法来求得神经网络中的权值数据,从而最终训练出模型,其基本思路是,首先初始化一个网络参数,然后根据整个神经网络的输入计算神经网络的输出,计算到输出之后,再用计算得到的输出值和神经网络的标记值进行对比,然后按照一定的比率来反向调整参数,使得最终的参数可以满足训练数据。反向传播算法如式(2-2)所示。
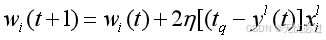
(2-2)
其中,t代表时间序列因素,η表示调整步幅,x表示输入,y表示输出。
3 深度学习
3.1 深度学习基本概念
我国著名学者周志华在西瓜书中对深度学习的论述是“典型的深度学习就是很深层的神经网络”[13]。
广义来讲,有多个层数的神经网络就是深度学习,单隐层的多层前馈神经网络(比如RBM)可以有较强的训练效果,如果进一步增加隐层的数量,就可以提升模型的复杂度,而且增加隐层的数量可以更有效,因为增加了隐层不仅增加了激活函数的神经元,而且还增加了激活函数的嵌套层数,但是多隐层的神经网络存在一些问题,比如无法使用标准BP算法进行训练,因为那样的话可能会在拟传播时候,存在发酸的现象而不发收敛到稳定状态。
有一些学者(Hinton等)提出了使用“预训练”和“微调”的方式进行模型训练,使用这些方法可以提升模型训练。本文借鉴了这些思想,但在实际处理过程中会有不同,本文在预处理中通过一些技术对图像进行压缩处理,实现了数据降维,然后在训练的时候也可以提升其训练效果,并且对算力的要求也会较之前大幅降低。
基于深度神经网络的循环神经网络在文本分析中有一定应用,但是由于其存在梯度消失和梯度爆炸的问题,基于卷积神经网络的CNN(Convolutional Neural Networks,CNN)模型可以在一定程度解决这些问题。具体来讲,CNN采用可视野可以降低计算复杂度,使用卷积、最大池化和全连接层等算法和技术完成模型训练。
3.2 循环神经网络
循环神经网络是基于深度神经网络的基础上提出的一种解决序列问题的神经网络,在循环神经网络中,把前项的输出和当前项的输入一起作为输入进行处理。一般前项输入的结果是上一个周期中的值,而当前的输入是本周期的输入值,可以结合上一个周期的结果和当前的输入共同构成当前的输入,从而完成在神经网络中引入序列的目的。其基本示意图如图3-1所示。
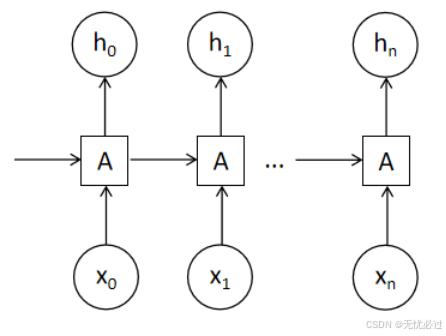
图3-1 循环神经网络神经关系示意图
3.3 卷积神经网络
基于深度神经网络的循环神经网络在图像分析中有一定应用,但是由于其存在梯度消失和梯度爆炸的问题,基于卷积神经网络的CNN(Convolutional Neural Networks,CNN)模型可以在一定程度解决这些问题。具体来讲,CNN采用可视野可以降低计算复杂度,使用卷积、最大池化和全连接层等算法和技术完成模型训练。

图3-2 n维滤波器过滤m维数据
上图中的原始数据是m维,滤波器基于n×n维原始数据进行过滤,过滤器是m×m(这里m=3)的滤波器,在下一层就生成了m-n+1维的数据。滤波器有时候也被叫做核函数,卷积的核心可以认为是核函数,它就是在此基础上发展的。
卷积神经网络是在深度神经网络的基础之上,由输入层、卷积层、激活函数、池化层和全连接层构成的前馈型神经网络。输入层和神经网络中的输入层含义一致,前述滤波器主要在卷积层工作,激活函数是一类具有映射关系的过程或者函数,典型的有ReLU函数,池化层是指利用降低采样率的方式去表示上一层的数据,一般有平均池化函数和最大池化函数,而全连接层在整个网络的尾部,也算是隐藏层中的一部分。
在机器学习中,大多数时候CNN都应用在计算机CV领域,然而,在2014年,Yoon Kim基于CNN做了某些调整和优化,使得CNN可以应用到文本分析和自然语言理解领域,他提出的模型就是TextCNN。因此,CNN被扩展到图像分析和分析领域,在这两个领域都有很多应用,大幅扩大了CNN的使用范围。
CNN的整体结构表示如下图3-3所示。
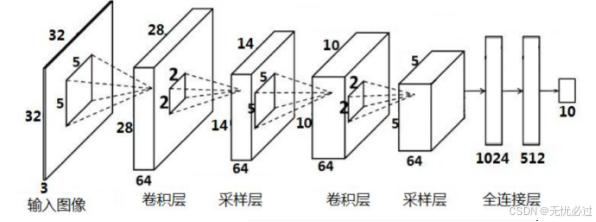
图3-3 CNN结构说明图
3.4 AlexNet
AlexNet是2012年Hinton和他的学生Alex在ImageNet的大赛中提出来的一个现在被称为经典神经网络的深度神经网络。该神经网络的重要贡献一是通过使用ReLU对以前神经网络中在网络深度较深的时候发生的梯度弥散问题有了解决办法,提出来了使用ReLU作为神经网络的激活函数,在神经网络的层数较浅的时候,ReLU超过了sigmoid的效果,在神经网络较深的时候解决了梯度弥散问题;二是提出了既有GPU加快了网络的训练速度;三是首次提出了使用Dropout解决神经网络中存在的过度你和问题。Alex和Hiton提出的AlexNet在图像分类中表现出了非常优异的表现,但是网络结构本省也足够复杂。训练的网络结构如图3-4所示。
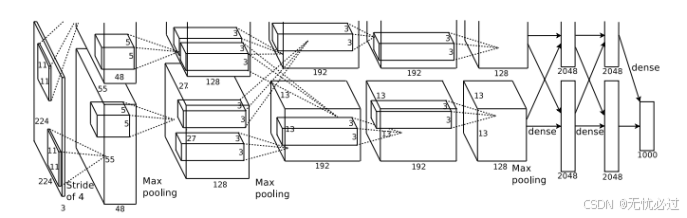
图3-4 Alex网络模型结构
3.5 GoogleNet
在神经网络的训练中,提升网络性能的办法在传统意义上无非两类,一是增加深度,二是加大宽度,深度是指网络的层次,宽度是指每一个层上面的神经网络节点数量。但是随着网络规模越来越复杂,这些方法也逐渐失效,网络无法永远进行横向和纵向的发展。在网络持续扩张的过程中出现了如下问题,一是参数过多,二是计算难度过大,对算力的消耗越来越多,三是深度越深,出现梯度消失问题。甚至有人戏说深度学习就是深度调参。解决这些问题的方法当然就是在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接变成稀疏连接。但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。
为了解决这一问题,谷歌GoogleNet团队提出了使用Inception的网络结构,来搭建一套稀疏高性能的网络结构。沿着这个思路他们一直进行了多次实验和探索,分别贡献了对应版本的学术成果,在学术界将这些成果分别称之为V1、V2、V3和V4。其基本思路是提出了一种Inception的网络结构,整个inception结构就是由多个这样的inception模块串联起来的。inception结构的主要贡献有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。可以使用1x1的卷积类完成降维,可以降低计算的复杂度。降维的图示如图3-5所示。
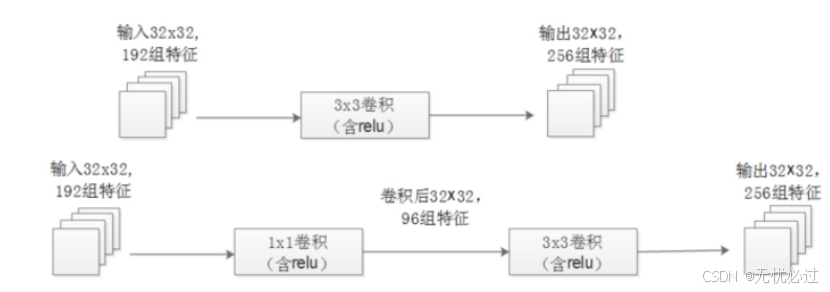
图3-5 利用1x1降维示意图
4 垃圾分类算法设计
4.1 数据收集
机器学习中的数据是一切算法开展的基础,在很多机器学习的算法研究中也发生了由于缺少数据而导致拟合不足的问题。随着机器学习的兴起,在数据的标记方面也产生了一些新的职业。专门机器学习数据集的标记师,可见有质量的数据对于机器学习的训练来讲是多么的重要。在进行生活垃圾分类的算法设计的时候,必须要有垃圾分类的原始标记数据,然后采用有师监督学习的方式进行训练。有师监督学习的方式是区别于无师监督学习的算法的。有师监督学习主要是指利用已有的代标记的数据。对已有的数据进行训练,训练过程中主是将这些数据经过神经网络的模型训练,而拟合到带有标记的那个数值上面去,当然标记一般在模型训练的时候是要进数值化的。本文收集的数据来自于https://blog.csdn.net/ai_faker/article/details/107952683,这个数据集里面收集了大约两万条以上的数据,主要包括除余垃圾和可回收垃圾,是目前已知的垃圾分类相关数据集里面比较齐全的一个数据集,其中厨余垃圾大概有1万条以上,而回收垃圾大概有1万条左右。数据集都是.jpg格式的,符合次次训练所需要的数据精度,也也收集到的数据中的图像,其长宽都大于128,而在后面训练的时候拟采用128*128矩阵进行训练,因此符合数据精度要求。
收集的数据基本情况如表4-1所示。
表4-1 数据集说明
| 厨余垃圾 | 可回收垃圾 |
|---|---|
| 12567条 | 9999条 |
4.2 图像预处理
图像在我们日常生活中非常常见,在互联网的精彩世界里,不像占据非常大的比重和空间。图像存储的数据密度比起文本来讲有深很多,在图像中,是由。不同的。行行列组成的像素点去构成一个图像,每一个像素点有自己的色彩,种色彩的表示,一般使用rgb去表示,此外,还会对颜色采用一个透明度去表示,这种表示方法就是典型的rgba表示方法,rgba表示方法从四个维度去表示一个图像,其中的rgb代表的是颜色值,而a代表的是透明度。
图像按照图像中颜色的表示方法可以分为多个模式,前面所说的rgba是最常用的,除此之外还有其他的模式。比如1表示的是1位像素,只有黑白之分,这种图像的表现方式简单,训练的时候对算力的要求较低,但是由于精准对较低,因此图像非常粗糙;其他下你告诉比如CMYK、YCBCR等模式主要使用在视频展示等方面,在计算机视觉和图像处理中使用较少。按照表现的色彩形式和色相的程度分为为不同的模式,比如灰度或者真彩色等。表4-2表示图像的不同模式。
表4-2 图像模式
| 图像模式 | 模式说明 |
|---|---|
| 1 | 1位像素,黑和白,存成8位的像素 |
| L | 8位像素,黑白 |
| P | 8位像素,使用调色板映射到任何其他模式 |
| RGB | 3× 8位像素,真彩 |
| RGBA | 4×8位像素,真彩+透明通道 |
| CMYK | 4×8位像素,颜色隔离 |
| YCBCR | 3×8位像素,彩色视频格式 |
一般我们见到的是RGB和RGBA模式,但是这两种模式的特点是,由于可以对颜色的分类非常精细,自然要占用更多存储空间,在计算机视觉表示的时候则需要更多存储空间,在机器学习的训练过程中则需要更多的算力和时间开销,因此在做计算机视觉的时候必须要在模型的训练精准度和算力之间进行权衡,基于此,本文拟采用将rgb图像转换成L类型的图像表示。转换后的图像精度是128*128,即用矩阵表示就是128个行像素和128个列像素。
4.3垃圾分类算法设计
使用图像作为原始数据,然后使用基于神经网络的训练算法给图像进行分类,然后识别出来图像中的物体是什么垃圾,这是本文的核心算法。在此过程中,需要先对图像进行梳理和转换,转换后生成128*128的矩阵表示图像。在机器训练中,如果训练的数据不足,容易造成拟合不足的问题,拟合不足会导致系统的模型无法较好拟合相关数据,从而模型质量不高,在进行预测的时候,其预测的精准度就无法切近实际情况,误差率较高。解决拟合不总的办法一般是可以通过增加样本,然后进行训练,这样就可以更好拟合数据,还有就是需要选择合适的模型,否则如果对特定问题找的基本模型不合适也容易造成欠拟合。还有一种训练的极端情况是过拟合,过拟合一般是因为模型在训练的过程中陷入了局部最优的情况,这个时候的表现是模型在训练数据上面有很好的效果,但是在其他数据集比如测试集上面的表现则不好。
垃圾分类算法的整体思路,先是对原始图像进行预处理,将原始数据处理的过程中,可以采用统一编号的方式对图像进行编号,这样便于程序的循环处理,可以采用序列编号的方式给所有涉及的数据进行编号,编号必须是连续的,如果终端则在训练的过程中就会出现报错。原始图像的编号采用序列的方式从1开始,逐步递增;在编号的时候,还需要对不同种类的图像进行编号,并且要保证这些编号之间相互独立不能彼此影响。在将这些图像进行预处理的过程中,可能会需要对缺失值进行处理,如果可以按照既定方案对图像进行编号,但是由于某种原因会导致这些图像的编号有缺失,可以采用忽略的方式,或者将相邻的图像复制一根,并用缺失编号对其进行编号。然后对图像集进行划分,将图像划分为训练集合和测试集合,训练集合用来训练模型,用这些数据就可以训练一个模型,然后用这个模型在测试集上面进行预测,如果在训练集合测试上面都表现较好,就取得了较好的实验结果,否则如果在训练集合上面表现良好,而在测试集合中表现不好,其预测准确率较低,就说明可能存在过拟合的问题。接着,使用神经网路的基本模型,设置好层数和各层的节点数量,就可以对数据进行训练,训练完成之后可以将模型保存下来,然后在测试集上面进行验证。最后,可以将这些训练结果进行比对,或者使用合理的评判标准来评判算法,典型的有p和r,其中p表示机器学习的准确度,而r表示回收率,除了使用精准度和回收率之外,还有一些其他的公式来表示算法的拟合能力。整体垃圾分类算法如图4-1所示。

图4-1 垃圾分类算法设计
模型训练是整个图像分类问题的重点工作,深度神经网络在垃圾分类的问题中的主要工作是基于输入层的图像,并按照有师学习的两个标签(分别是厨余垃圾和其他垃圾),然后构建一个多层级,每层有多个节点的多隐层的深度学习网络。整个模型结构如图4-2所示,其中最下面是输入的128*128的图像数据,最上层是标签,一个是厨余垃圾(用0表示),一个是可回收垃圾(用1表示),要训练的重点就是中间的网络结构。
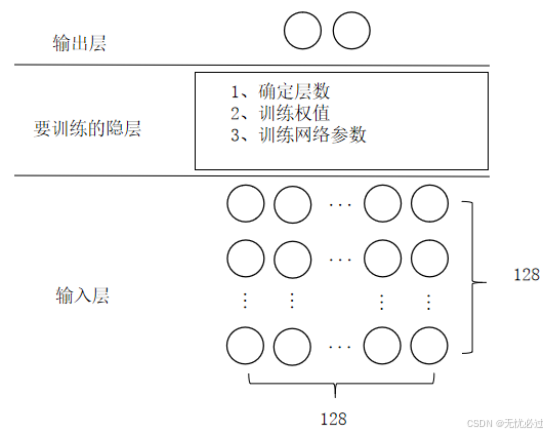
图4-2 模型结构
5 实验与分析
5.1 实验环境
在机器学习相关的场景中,一般使用的编程语言有python、matlab、julia、R语言等,其中python由于其使用场景较广,而且被谷歌等头部企业所采纳,加之有很多流行的框架,因此python在机器学习中使用较多。因此本文拟采用python作为编程语言。在本文中使用较多的有对图像的处理和深度神经网络,对图像的处理选用pillow包,这个包中包括有对图像的常见操作的函数,在图像的处理过程中使用起来很方便;在深度神经网络中使用tensorflow框架进行,tensorflow目前有两个大的版本,分别是1.X和2.X版本,由于2.X版本较新,在很多地方都和1.X不一样,虽然该版本是官方推荐使用的,但是由于版本较新,社区的支持程度不是很高,而且相关的可供搜索和借鉴的方法和研究方法较少,因此仍然选用1.X版本就行开发。
在开发工具的选择中,选用jupyter进行开发,jupyter是基于ipython的一款开发工具,在开发的过程中,非常适合调试和渐进式开发,可以边写代码边查看结果和调试,而且jupyter工具的使用基于cell,可以满足分模块设计和编程的思想,非常适合本实验,因而开发工具选用jupyter notebook工具。
基础平台基于windows平台进行开发,虽然tensorflow建议在基于gpu的硬件上进行运行,这样可以使用基于gpu的计算机硬件,可以加速算法的执行速度,然而由于受到资源限制,本文在开发中选用基于cpu的硬件进行开发。总之,系统涉及到的平台、工具、软件和包如表5-1所示。
表5-1 实验环境说明
| 硬件 | cpu:Corei9 GPU CUDA |
|---|---|
| 内存:三星16G | |
| 存储:SSD 256G | |
| 操作系统 | Windows 10 专业版 |
| 编程环境 | Python:3.6 |
| 相关包 | tensorflow:1.15.0 pillownumpy |
5.2 实验过程
5.2.1图像预处理
图像预处理的过程是对原始的图像经过变换,最终生成128*128矩阵的数据。处理的流程是现先分类读取图像,然后分类对图像进行处理,处理之后将这些数据放到新的路径下存储。原始图像和新图像的变化如图5-1所示。左侧是原始图像,右侧是处理后的“L”模式的图像,上面两个是厨余垃圾,下面两个是可回收垃圾。

图5-1 原始图像和预处理后的图像对比
将原始图像转换为压缩图像,也就是给原始数据降维的代码如附录1所示。
将原始的数据从原始的目录移动到新目录的基本逻辑就是先读取原始文件,然后将生成的新的图像放到新的路径下,方便后续处理,这样做的好处还有一个就是可以不影响原来的图像。
相关代码如附录2所示。
5.2.2训练集和测试集分离
在模型训练中,既需要按照原始数据进行模型训练,这个时候就是使用数据feed模型,其结果是模型,重点是训练模型参数,在模型训练完成之后,就需要用模型在测试集合上面来进行测试,这个时候可以展示模型的效果,因此需要有训练集和模型集。但是训练集和测试集必须要分开,也就是使用模型机进行训练,但是测试集中的数据最好不要包括训练集中的数据,这样可以客观判断模型训练效果。
5.2.3模型训练
模型训练是系统的核心功能,模型训练的任务是寻找合适的网络层数和每层的节点数,并且对网络进行训练获得模型参数。训练的原始输入是128*128的数据,训练模型的最终输出结果是2维数据,分别是厨余垃圾和可回收垃圾。根据模型训练的一般经验,在设置层数的时候,可以采用逐层减少的方式,而隐层不宜过多,如果隐层过多,一是增加了模型训练的复杂度,二是容易陷入过拟合。经过实验,在模型中的隐层数为5的时候,模型在测试集上的表现会降低,最终选用的模型层数中隐层一共有四层,分别有1000、500、256、128个节点。在本文中选择不同的隐层和节点的时候,取得的实验结构如下表5-2所示,实验结果表明当选用4层隐层的时候,取得了较好的训练效果和拟合效果。
表5-2 实验过程
| 隐层数 | 各层节点数 | 准确率 |
|---|---|---|
| 2 | 800、400 | 67.31 |
| 3 | 800、400、200 | 76.35 |
| 4 | 800、600、400、200 | 83.26 |
| 4 | 1000、500、256、128 | 93.22 |
| 4 | 400、600、800、400 | 84.32 |
| 5 | 1000、800、600、400、200 | 90.3 |
| 6 | 1000、800、600、500、400、300 | 83.4 |
训练代码如附录4所示。
训练过程如下图5-2所示。
图5-2 训练过程展示
5.2.4实验分析
模型评估的方法较多,但是一般采用的都是指标有准确率、精确率、召回率等指标,和这些指标相关的一些基本信息是数据本身的真伪和训练结果的真伪的比较。将本身是正例而训练的结果也是正例的数据称之为真阳,而相应的数据的数量就是真阳数据量,简称真阳,用TP表示;真阴是指数据本身是反例,而且预测的结果也是反例的数据量,用TN表示;假阳是数据本身是反例,而预测的结果是正例的数据,用FP表示;假阴是指数据本身是反例,而预测的结果是反例的数据,使用FN表示。在众多的模型评估指标中,准确率是使用广泛的一个指标,如式5-1所示。
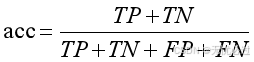
式5-1
本模型评估的最终的准确率是93.22%,可以满足应用落地的实际需求。
在实验中训练了200epoch,下图记录了连接着的10此epoch的acc均值,将每一个epoch得到的训练结构都是用测试集来验证结果。整个实验过程如图5-3所示。
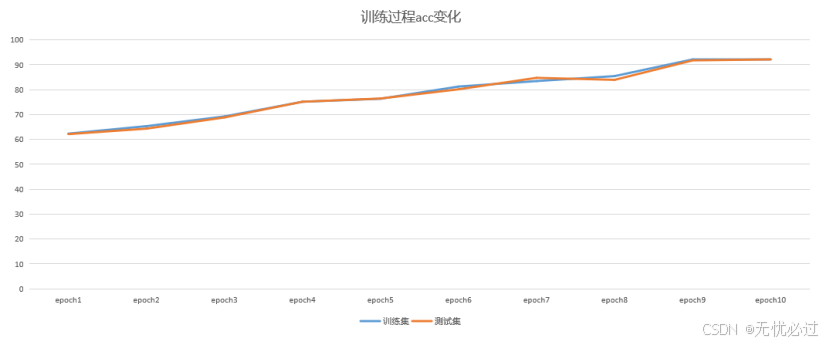
图5-3 训练过程acc变化
实验中使用的数据超过2万条,每种类型的数据有1万条左右,这说明数据量足够大,数据的预测准确率达到了90%以上,说明具有一定的应用价值,可以继续推广使用算法,落地工业上的应用产品。
在选用不用的隐层和节点的时候,实验的结果都有不同的表现,但是当隐层为4,每层节点数逐层减少而且步长也逐步降低的时候,取得了最好的效果,当节点数更少或者更多的时候,其准确率都相对较低;当隐层是4层的时候,采取节点数均匀减少的方式或者先减少后增加的方式,其准确率表现都不如逐层减少而且步长页逐步减少的方式。
5.2.5预测过程
在完成了训练之后,就会训练并完成了一个训练的模型,将这个模型保存下来,就可以在有一个新的图像的时候,对新的图像进行预测。也是模型应用的最主要方面,模型的预测过程就是应用已经训练好的模型去预测新的图像,训练的代码如附录5所示。
比如对如下图5-3的图像预测的结果是可回收垃圾,预测概率是0.67。可以看到这个图像是一个可以回收的矿泉水瓶。

图5-3 预测图像
6 总结与展望
垃圾分类在日常生活中有重要的意义,对社会的循环经济也有重大作用。在源头对垃圾分类可以有效缓解后续垃圾处理的压力,降低垃圾处理成本,提升垃圾处理效率。可以使用图像识别的方法对垃圾进行分类技术进行研究,本文基于当前热门的深度神经网络技术对垃圾进行分类,经过图像收集、图像预处理、模型训练、模型预测等步骤的研究,验证了可以使用基于深度神经网络的方法对垃圾进行分类,经过验证,分类准确率达到90%以上,这说明基于图像识别的垃圾技术有一定的应用前景。
然而,本文还存在一定不足,一是数据的质量有待进一步提高,本文的数据是通过收集公开数据集的方式完成,然而这些数据和实际中的垃圾数据还有一定距离,因此在真正落地的过程中如果能有质量更高的数据进行训练,可以进一步提升应用的可用性。二是基于神经网络的分类算法还需要与其他硬件或者设备一起使用才能发挥更好的作用,比如和智能垃圾桶一起工作,在使用图像进行分类之后就可以将垃圾通过机械装置或者物联网设备放入到对应的垃圾桶中,三是限于算力的限制,算法还有一定的提升空间,如果可以收集到更多和质量更高的数据,则可以进一步提升训练的模型质量。
致 谢
略
附录
附录1 图像压缩代码
import numpy as np
from PIL import Image
Xtrue=np.empty((12567,128,128))
def readImgIntoX(X,dirr,index):
im=Image.open(dirr)
data = im.getdata()
data = np.matrix(data)
data = data.reshape((128,128))
X[index]=data
附录2 图像处理存储代码
from PIL import Image
def loadImage(dirr,copyDir,num):
image =dirr+num+“.jpg”
im = Image.open(image)
im1=im.convert(“L”)
im2 = im1.resize((128,128))
imageCopy =copyDir+num+“.jpg”
im2.save(imageCopy)
def dealTrueImg():
i = 1
while i < 12568 :
ii = “O_”+str(i)
dirr=“G:\work\anaconda\envs\litter\code\data\raw\O\”
copyDir=“G:\work\anaconda\envs\litter\code\data\trimed\O\”
loadImage(dirr,copyDir,ii)
i+=1
def dealFalseImg():
i = 1
while i < 10000 :
ii = “R_”+str(i)
dirr=“G:\work\anaconda\envs\litter\code\data\raw\R\”
copyDir=“G:\work\anaconda\envs\litter\code\data\trimed\R\”
loadImage(dirr,copyDir,ii)
i+=1
dealTrueImg()
dealFalseImg()
附录3 数据集分割代码
def splitTrainAndTest(data1,data2,ratio):
indices = np.random.permutation(len(data1))
testSize = int(len(data1)*ratio)
tti = indices[:testSize]
ti= indices[testSize:]
return data1[ti],data2[ti],data1[tti],data2[tti]
Xtrain,Ytrain,Xtest,Ytest=splitTrainAndTest(X,Y,0.2)
train_images=Xtrain/255
train_labels=Ytrain
附录4 模型训练代码
from tensorflow import keras
model = keras.Sequential([
keras.layers.Flatten(input_shape=(128, 128)),
keras.layers.Dense(1000, activation=‘relu’),
keras.layers.Dense(500, activation=‘relu’),
keras.layers.Dense(256, activation=‘relu’),
keras.layers.Dense(128, activation=‘relu’),
keras.layers.Dense(2)
])
model.compile(optimizer=‘adam’,
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[‘accuracy’])
model.fit(train_images, train_labels, epochs=200)
附录5 预测代码
probability_model = keras.Sequential([model,keras.layers.Softmax()])
predictions = probability_model.predict(train_images)
probability_model = keras.Sequential([model,keras.layers.Softmax()])
predictions = probability_model.predict(Xnew/255)
i,j=predictions[0]
if j > 0.5 :
print(“本图片的预测结果是可回收垃圾”)
else :
print(“本图片的预测结果是厨余垃圾”)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











