









robots
1、题目描述:X老师上课讲了Robots协议,小宁同学却上课打了瞌睡,赶紧来教教小宁Robots协议是什么吧。
2、本题考查的知识点为 robts.txt 协议
不管是企业网站还是门户网站,上面都会有些资料是保密而不对外公开的。怎么样做到不对外公开呢?唯一的保密的措施就是不让搜索引擎来搜录这些信息。这 样就会不在网络上公司,那么要实现这个网站页面不收录,就体了robots.txt的作用啦!robots.txt是一个简单的记事本文件,这是网站管理员和搜录引擎对话的一个通道。在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。
当一个搜索机器人(有的叫搜索蜘蛛)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取。
既然我们这里知道了什么是robots.txt,我们该如何来应用呢?
1、如果我们网站的内容为全部公开,则不需要要设置robots.txt或robots.txt为空就可以啦。
2、robots.txt这个文件名必需要是小写而且都要放在网站的根目录下http://www.hongtaoseo.com/robots.txt一般要通过这种URL形式能访问到,才说明我们放的位置是正确的。
3、robots.txt一般只写上两种函数:User-agent和Disallow。有几个禁止,就得有几个Disallow函数,并分行描述。
4、至少要有一个Disallow函数,如果都允许收录,则写: Disallow:,如果都不允许收录,则写:Disallow: / (注:只是差一个斜杆)。
写法说明
User-agent: *星号说明允许所有搜索引擎收录
Disallow: /search.html说明http://www.honbgtaoseo.com/search.html这个页面禁止搜索引擎抓取。
Disallow: /index.php?说明类似这样的页面http://www.www.hongtaoseo.com/index.php?search=%E5%A5%BD&action=search&searchcategory=%25禁止搜索引擎抓取。
常见的用法实例:
允许所有的robot访问
User-agent: *
Disallow:
或者也可以建一个空文件“/robots.txt” file
禁止所有搜索引擎访问网站的任何部分
User-agent: *
Disallow: /
禁止所有搜索引擎访问网站的几个部分(下例中的01、02、03目录)
User-agent: *
Disallow: /01/
Disallow: /02/
Disallow: /03/
禁止某个搜索引擎的访问(下例中的BadBot)
User-agent: BadBot
Disallow: /
只允许某个搜索引擎的访问(下例中的Crawler)
User-agent: Crawler
Disallow:
User-agent: *
Disallow: /
另外,我觉得有必要进行拓展说明,对robots meta进行一些介绍:
Robots META标签则主要是针对一个个具体的页面。和其他的META标签(如使用的语言、页面的描述、关键词等)一样,Robots META标签也是放在页面的中,专门用来告诉搜索引擎ROBOTS如何抓取该页的内容。
————摘自百度经验
3、解题过程
首先打开题目后发现是一个空网页,网页内没有任何内容

根据已知的robots.txt协议,于是我们在URL末尾加上“ /robots.txt ”
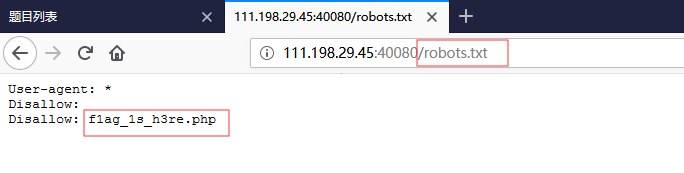
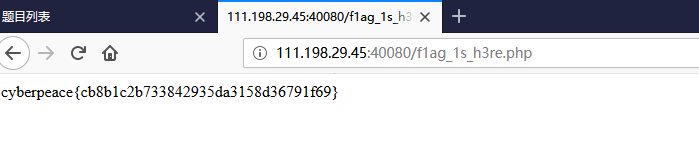
在打开“ Disallow ”后的flag_ls_h3re.php文件(将flag_ls_h3re.php放到URL末尾 ),
如下图所示便可获得flag















 1774
1774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









