







程序在执行过程中会频繁的运行小范围的循环代码,而这些循环又会对数据存储器的局部区域反复访问。
Cache 同时使用了时间和空间的局部性原理。如果对存储器的访问受时间影响,在时间上有连续性,则这种时间上密集的访问被称为时间局部性访问;如果多次对存储器的地址访问相近,则这种空间上邻近的访问被称为空间局部性访问。
一.存储层次:

最顶层:存储层次的最顶层在处理器内核中,该存储器被称为寄存器文件。这些寄存器被集成在处理器内核中,在系统中提供最快的存储访问。
一级存储:紧耦合存储器( TCM ),一级 cache 和主存在这一级。
二级存储:辅助存储器(辅助存储器),用来存储正在运行的较大的程序未被使用的部分,或者存放当前没有运行的程序。
二.写缓冲器作为临时缓冲帮助 cache 释放存储空间。

三.逻辑MMU与物理MMU
如果带 cache 的处理器核支持虚拟存储,那么 cache 就可以放在处理器内核和存储管理单元 MMU 之间或者 MMU 与物理存储器之间。
逻辑 cache 在虚拟地址空间存储数据,它位于处理器和 MMU 之间。处理器可以直接通过逻辑 cache 访问数据而无需通过 MMU 。
物理 cache 使用物理地址存储数据,它位于 MMU 和主存之间。当处理器访问存储器时, MMU 必须先把虚拟地址转化为物理地址, cache 存储器才可向内核提供数据。
从 arm7 ~ arm10 都是使用逻辑 cache , arm11 使用物理 cache 。

四. Cache 的结构

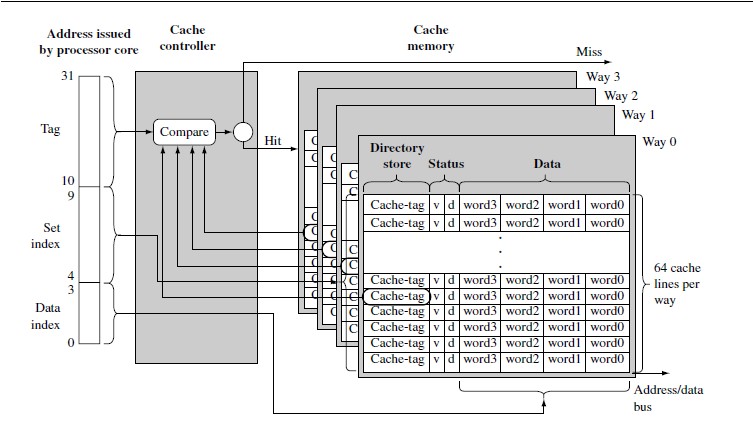
带有 cache 的 ARM 内核采用了 2 种总线结构:冯诺依曼结构和哈佛结构。在使用冯诺依曼结构的处理器内核中,只有一个数据和指令公用的 cache ,这种 cache 被称作统一 cache 。哈佛结构将指令总线和数据总线分离,存在指令 cache ( I-cache )和数据 cache ( D-cache ),这种类型的 cache 被称作分离 cache 。上边的图是统一 cache , cache 的两个主要组成部分 cache 控制器和 cache 存储器。 Cache 存储器是一个专用的存储器阵列,其访问单元称为 cache 行。 Cache 有 3 个主要的部分:目录存储段( directory store ),状态信息段( status information ),数据项段( data section )。每一个 cache 行都由这 3 部分组成。 Cache 使用目录存储段来记录每个 cache 行是由主存的什么地方拷贝而来。该目录项被称为“ cache 标签”。状态位用来记录状态信息, 2 个常见的状态位是有效位 (valid bit) 和脏位( dirty bit )。 Cache 存储器必须存储来自主存的信息,这些信息被放在数据项段里。
五. Cache 与主存的关系
1 )直接映射

主存的每个地址都对应着 cache 存储器的唯一的一行。如图,组索引( set index )可以确切的指出所有以 0x824 结尾的内存地址在 cache 中所唯一对应的存储地址;数据索引域可以确定字,半字或者字节在该 cache 行中的位置;标签域用来与 cache 行中的 cache-tag 相比较。
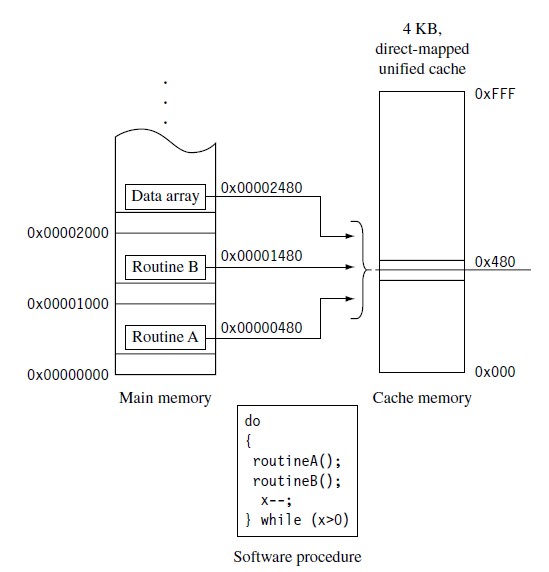
直接映射这种设计使每个主存块在 cache 中只有一个特定的行可以存放,那么如果程序同时用到对应于 cache 同一行的 2 个主存块,那么就会发生冲突。冲突的结果就是导致 cache 行的频繁置换。这就是直接映射 cache 的颠簸问题( Thrashing )。重复的 cache 失效导致 cache 控制器连续不断的将当前不用的过程置换出 cache ,这就是 cache 颠簸。
2 )组相联

为了减少 cache 的颠簸频率,某些 cache 使用了其他设计。将 cache 分成一些容量相同的小单元,称作路( way )。这里一个组索引对应多个 cache 行,即在每一路里都有一个 cache 行与之对应,组索引相同的 cache 行被称作处于同一个组( set )里,这也是组索引命令的由来。拥有相同组索引的 cache 行称为组相联的。在 cache 的同一个组当中,数据放置的位置具有排他性,可以防止同样的数据被重复放在一个组的不同的 cache 行。
3 )全联
随着 cache 控制器的相联度提高,冲突的可能性减小了。理想的目标是,尽量提高组相联程度,使主存地址能够映射到任意 cache 行,这样的 cache 被称为全相联 cache 。
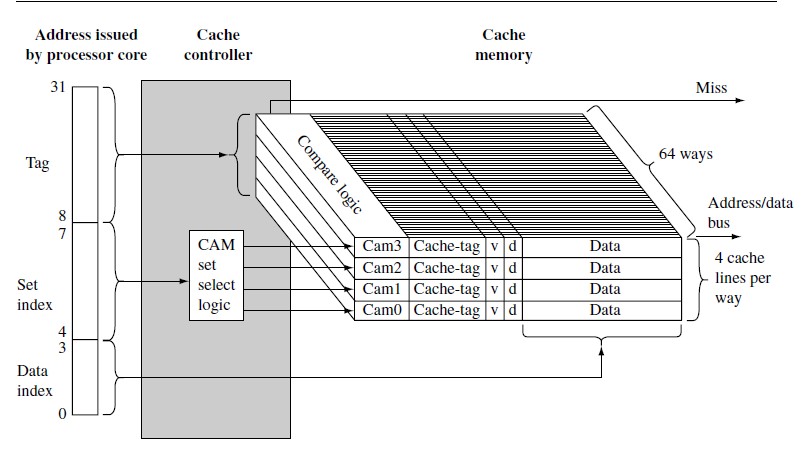
硬件设计者提高相联度的一种方法就是使用内容寻址存储器 CAM ( Content Addressable Memory )。在 ARM920T 处理器核中, ARM 使用了 CAM 来定位 cache-tag 。 ARM920T 中的 cache 是 64 路组相联的。 CAM 使用一组比较器,以比较输入的标签地址和存储在每一个有效 cache 行中的 cache-tag 。 CAM 采用了与 RAM 相反的工作方式: RAM 是得到一个地址后再给出数据;而 CAM 则是在检测到给定的数据值在存储器中后,再给出该数据的地址。如图是 ARM940T 的 cache 结构图。访问地址的 tag 部分被作为 4 个 CAM 的输入,输入标签同时与存储在 64 路中的所有 cache 标签相比较。如果有一个匹配,那么数据就由 cache 存储器提供;如果没有匹配,存储器控制器就会产生一个失效( miss )信号。
六. Cache 策略
Cache 策略包括写策略,替换策略及分配策略。
1 )写策略
写策略包括直写法( writethrough )和回写法( writeback )。
直写法:
如果 cache 控制器使用直写策略,那么处理器核写 cache 命中时,将同时修改 cache 和主存中的内容,以确保 cache 和主存数据的一致性。
回写法:
如果 cache 控制器使用回写策略,那么处理器核写 cache 命中时,只向 cache 存储器写数据而不立即写入主存。配置成回写法的 cache 要使用到 cache 行的状态信息块中的一个或多个脏位( dirty bit )。当回写 cache 控制器向 cache 存储器中某一行写入数据时,它会将脏位设置为 1 。如果 cache 控制器要将一个脏位被置位的 cache 行替换出 cache 存储器,那么该 cache 行数据会自动被写到主存单元中去。
2 )替换策略
带 cache 的 ARM 核支持两种替换策略:伪随机替换法和轮转法。当一个 cache 访问失效时, cache 控制器必须从当前有效的组中选择一个 cache 行来存储从主存中取得的新信息。被选中的 cache 行被称为丢弃者( victim )。如果丢弃者中包含有效的脏数据,那么在该 cache 行被写入新数据之前,控制器必须把该行的数据写入到主存。选择和替换丢弃 cache 行的过程被称作淘汰( eviction )。
3 )分配策略
在 cache 失效发生时, ARM 的 cache 可以采取两种策略来分配 cache 行:第一种叫做读操作分配( read-allocate )策略 ; 第二种叫做读 / 写操作分配( read-write-allocate )策略。如果 cache 未命中,那么对于读操作分配策略,只有进行存储器读操作时 , 才分配 cache 行。如果被替换的 cache 行包含有效数据,那么在该行被新的数据替换之前,要先把原来的内容写入主存中。
采用读 / 写操作分配策略时,不管是存储器读操作,还是存储器写操作,在 cache 未命中时,都将分配 cache 行。
七.清除( flush )和清理( clean ) cache
清除 cache 的意思是清除 cache 中存储的全部数据,对处理器而言,清除操作只要清零相应 cache 的有效位即可。然而,对于采用回写策略的 D-cache ,就需要使用清理( clean )操作。
八. Cache 锁定
Cache 锁定是将 cache 中的部分代码和数据标记为非替换( exempt of eviction )的。被锁定的代码和数据有更快的系统反应能力,因为这些数据和代码一直存放在 cache 中。 Cache 在正常操作时,经常会涉及到行替换,这种替换会带来代码执行时间不确定的问题,而 cache 锁定会避免这种不确定性。 ARM 内核为 cache 锁定分配固定的 cache 单元。一般来讲,分配 cache 锁定的 cache 单元是一个路( way )。
文章出处: http://blog.csdn.net/woshixingaaa/archive/2011/03/09/6235181.aspx















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









