# 设置好主机名并添加hosts解析
主机名 IP地址 身份 master01 172.2.25.50 主Master master02 172.2.25.51 备Master node01 172.2.25.52 节点1 node02 172.2.25.53 节点2 node03 172.2.25.54 节点3
# Docker脚本文件
https://node-siyuan.oss-cn-beijing.aliyuncs.com/K8s%E6%96%87%E4%BB%B6/docker-install.tar.gz
# 解压并执行Docker安装脚本
[root@master01 opt]# ls
docker-install.tar.gz
[root@master01 opt]# tar -zxvf docker-install.tar.gz
docker-install/
docker-install/download/
docker-install/download/docker-compose-v2.23.0
docker-install/download/docker-20.10.24.tgz
docker-install/download/docker
docker-install/download/docker.service
docker-install/download/daemon.json
docker-install/install-docker.sh
[root@master01 opt]# cd docker-install/
[root@master01 docker-install]# ./install-docker.sh i
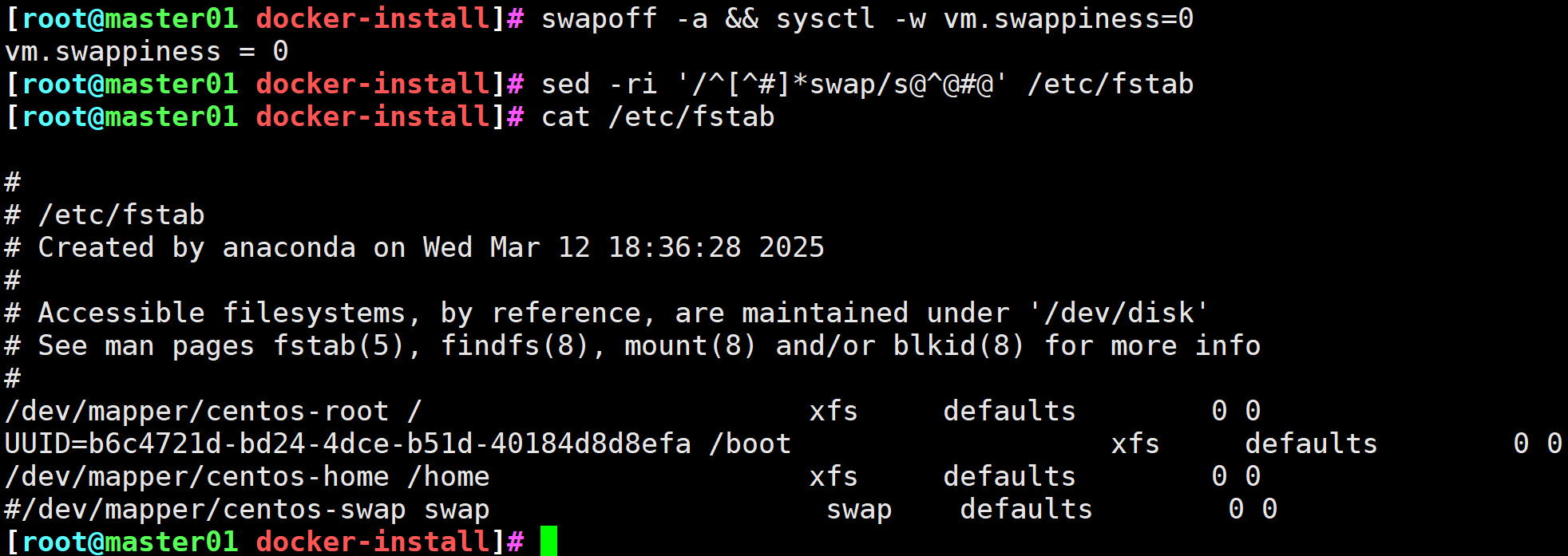
# 临时和永久关闭swap分区
[root@master01 docker-install]# swapoff -a && sysctl -w vm.swappiness=0
vm.swappiness = 0
[root@master01 docker-install]# sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab
图1 关闭swap分区
# 确保各个节点MAC地址或product_uuid唯一
[root@master01 docker-install]# ifconfig ens33 | grep ether | awk '{print $2}'
00:0c:29:5f:82:68
[root@master01 docker-install]# cat /sys/class/dmi/id/product_uuid
4FE74D56-8C86-11D7-9761-FF1D435F8268
# 温馨提示:
# 一般来讲,硬件设备会拥有唯一的地址,但是有些虚拟机的地址可能会重复。
# Kubernetes使用这些值来唯一确定集群中的节点。 如果这些值在每个节点上不唯一,可能会导致安装失败。
# 确保网络的连通性
[root@master01 docker-install]# ping -c 3 baidu.com
PING baidu.com (110.242.68.66) 56(84) bytes of data.
64 bytes from 110.242.68.66 (110.242.68.66): icmp_seq=1 ttl=128 time=40.6 ms
64 bytes from 110.242.68.66 (110.242.68.66): icmp_seq=2 ttl=128 time=41.1 ms
64 bytes from 110.242.68.66 (110.242.68.66): icmp_seq=3 ttl=128 time=37.2 ms
--- baidu.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 37.299/39.670/41.103/1.704 ms
# 允许iptable检查桥接流量
cat <<EOF | tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
# 设置Docker环境
[root@master01 docker-install]# systemctl enable --now docker
[root@master01 docker-install]# cat /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
[root@master01 docker-install]# systemctl restart docker.service
# K8s的RPM包下载
https://node-siyuan.oss-cn-beijing.aliyuncs.com/K8s%E6%96%87%E4%BB%B6/kubeadmin-rpm-1_23_17.tar.gz
# 解压并安装压缩包
[root@master01 opt]# tar -zxvf kubeadmin-rpm-1_23_17.tar.gz
[root@master01 opt]# yum localinstall -y kubeadmin-rpm-1_23_17/*.rpm
# 设置时区
[root@master01 opt]# ln -svf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 导入Docker镜像(注意:Master和Node分别导入到Master和Node主机,CNI插件所有主机都装上)
# Master节点镜像
https://node-siyuan.oss-cn-beijing.aliyuncs.com/K8s%E6%96%87%E4%BB%B6/%E5%88%9D%E5%A7%8B%E5%8C%96K8s%E9%95%9C%E5%83%8F/master-1.23.17.tar.gz
# Node节点镜像
https://node-siyuan.oss-cn-beijing.aliyuncs.com/K8s%E6%96%87%E4%BB%B6/%E5%88%9D%E5%A7%8B%E5%8C%96K8s%E9%95%9C%E5%83%8F/slave-1.23.17.tar.gz
# CNI插件
https://node-siyuan.oss-cn-beijing.aliyuncs.com/K8s%E6%96%87%E4%BB%B6/%E5%88%9D%E5%A7%8B%E5%8C%96K8s%E9%95%9C%E5%83%8F/cni-v1.5.1-flannel-v0.25.6.tar.gz
# 所有主机导入CNI镜像
[root@master01 opt]# docker load -i cni-v1.5.1-flannel-v0.25.6.tar.gz
30f8e4588c9e: Loading layer [==================================================>] 8.081MB/8.081MB
05bb1aee8d21: Loading layer [==================================================>] 2.836MB/2.836MB
Loaded image: flannel/flannel-cni-plugin:v1.5.1-flannel2
574b3797bb46: Loading layer [==================================================>] 3.223MB/3.223MB
8047f399ca1f: Loading layer [==================================================>] 16.68MB/16.68MB
# Master主机节点导入镜像
[root@master01 opt]# docker load -i master-1.23.17.tar.gz
cb60fb9b862c: Loading layer [==================================================>] 3.676MB/3.676MB
4e0ee8e33055: Loading layer [==================================================>] 1.538MB/1.538MB
f1f1d923ca19: Loading layer [==================================================>] 126.1MB/126.1MB
# Node主机节点导入镜像
[root@node03 opt]# docker load -i slave-1.23.17.tar.gz
1bb475414a7e: Loading layer [==================================================>] 7.67MB/7.67MB
895a9dd950c1: Loading layer [==================================================>] 9.353MB/9.353MB
290b7ce264c5: Loading layer [==================================================>] 14.91MB/14.91MB
# 所有主机开机自启Kubelet
[root@master01 opt]# systemctl enable kubelet
Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
# 在两个Master节点安装Nginx+Keepalived
[root@master01 opt]# cat /etc/yum.repos.d/nginx.repo
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[root@master01 opt]# yum -y install epel-release nginx keepalived nginx-mod-stream
# 同时在master01和master02修改Nginx配置文件
[root@master02 opt]# cat /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 172.2.25.50:6443 weight=5 max_fails=3 fail_timeout=30s;
server 172.2.25.51:6443 weight=5 max_fails=3 fail_timeout=30s;
}
server {
listen 16443;
proxy_pass k8s-apiserver;
}
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
# 重启Nginx
[root@master02 opt]# systemctl restart nginx && systemctl enable nginx
# 编写Keepalived检查脚本
[root@master01 keepalived]# cat /etc/keepalived/check.sh
#!/bin/bash
# 定义日志文件路径
LOG_FILE="/var/log/nginx_keepalived_check.log"
MAX_LINES=1000 # 设置日志保留1000行(因为不做限制日志会无限增大,占用大量磁盘空间)
# 记录日志的函数,带有详细的时间格式,并保留最后1000行日志
log_message() {
local time_stamp=$(date '+%Y-%m-%d %H:%M:%S') # 定义时间格式
echo "$time_stamp - $1" >> $LOG_FILE
# 截取日志文件,只保留最后1000行
tail -n $MAX_LINES $LOG_FILE > ${LOG_FILE}.tmp && mv ${LOG_FILE}.tmp $LOG_FILE
}
# 检测 Nginx 是否在运行的函数
check_nginx() {
pgrep -f "nginx: master" > /dev/null 2>&1
echo $?
}
# 1. 检查 Nginx 是否存活
log_message "正在检查 Nginx 状态..."
if [ $(check_nginx) -ne 0 ]; then
log_message "Nginx 未运行,尝试启动 Nginx..."
# 2. 如果 Nginx 不在运行,则尝试启动
systemctl start nginx
sleep 2 # 等待 Nginx 启动
# 3. 再次检查 Nginx 状态
log_message "启动 Nginx 后再次检查状态..."
if [ $(check_nginx) -ne 0 ]; then
log_message "Nginx 启动失败,停止 Keepalived 服务..."
# 4. 如果 Nginx 启动失败,停止 Keepalived
systemctl stop keepalived
else
log_message "Nginx 启动成功。"
fi
else
log_message "Nginx 正常运行。"
fi
# 修改Keepalived配置文件
# master01的Keepalived
[root@master01 keepalived]# cat /etc/keepalived/keepalived.conf
global_defs {
router_id LVS_DEVEL
}
vrrp_script keepalived_nginx_check { # 这里是上一步骤添加的脚本,在这里进行调用
script "/etc/keepalived/check.sh" # 根据自己添加的脚本路径进行修改,建议还是放在这个目录下便于管理
}
vrrp_instance VI_1 {
state MASTER # 主修改state为MASTER,备修改为BACKUP
interface ens33 # 修改自己的实际网卡名称
virtual_router_id 51 # 主备的虚拟路由ID要相同
priority 100 # 优先级,备服务器设置优先级比主服务器的优先级低一些
advert_int 1 # 广播包发送间隔时间为1秒
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.2.25.100/24 # 虚拟IP修改为没有占用的IP地址,主备的虚拟IP相同就好
}
track_script {
keepalived_nginx_check # vrrp_script 定义的脚本名,放到这里进行追踪调用,Keepalived 可以根据脚本返回的结果做出相应的动作
}
}
# master02的Keepalived
[root@master02 keepalived]# cat /etc/keepalived/keepalived.conf
global_defs {
router_id LVS_DEVEL
}
vrrp_script keepalived_nginx_check { # 这里是上一步骤添加的脚本,在这里进行调用
script "/etc/keepalived/check.sh" # 根据自己添加的脚本路径进行修改,建议还是放在这个目录下便于管理
}
vrrp_instance VI_1 {
state BACKUP # 主修改state为MASTER,备修改为BACKUP
interface ens33 # 修改自己的实际网卡名称
virtual_router_id 51 # 主备的虚拟路由ID要相同
priority 90 # 优先级,备服务器设置优先级比主服务器的优先级低一些
advert_int 1 # 广播包发送间隔时间为1秒
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.2.25.100/24 # 虚拟IP修改为没有占用的IP地址,主备的虚拟IP相同就好
}
track_script {
keepalived_nginx_check # vrrp_script 定义的脚本名,放到这里进行追踪调用,Keepalived 可以根据脚本返回的结果做出相应的动作
}
}
# 重新启动Keepalived和Nginx配置文件
[root@master01 keepalived]# systemctl daemon-reload && systemctl restart nginx
[root@master01 keepalived]# systemctl restart keepalived && systemctl enable keepalived
图2 查看Master01主机生成的VIP
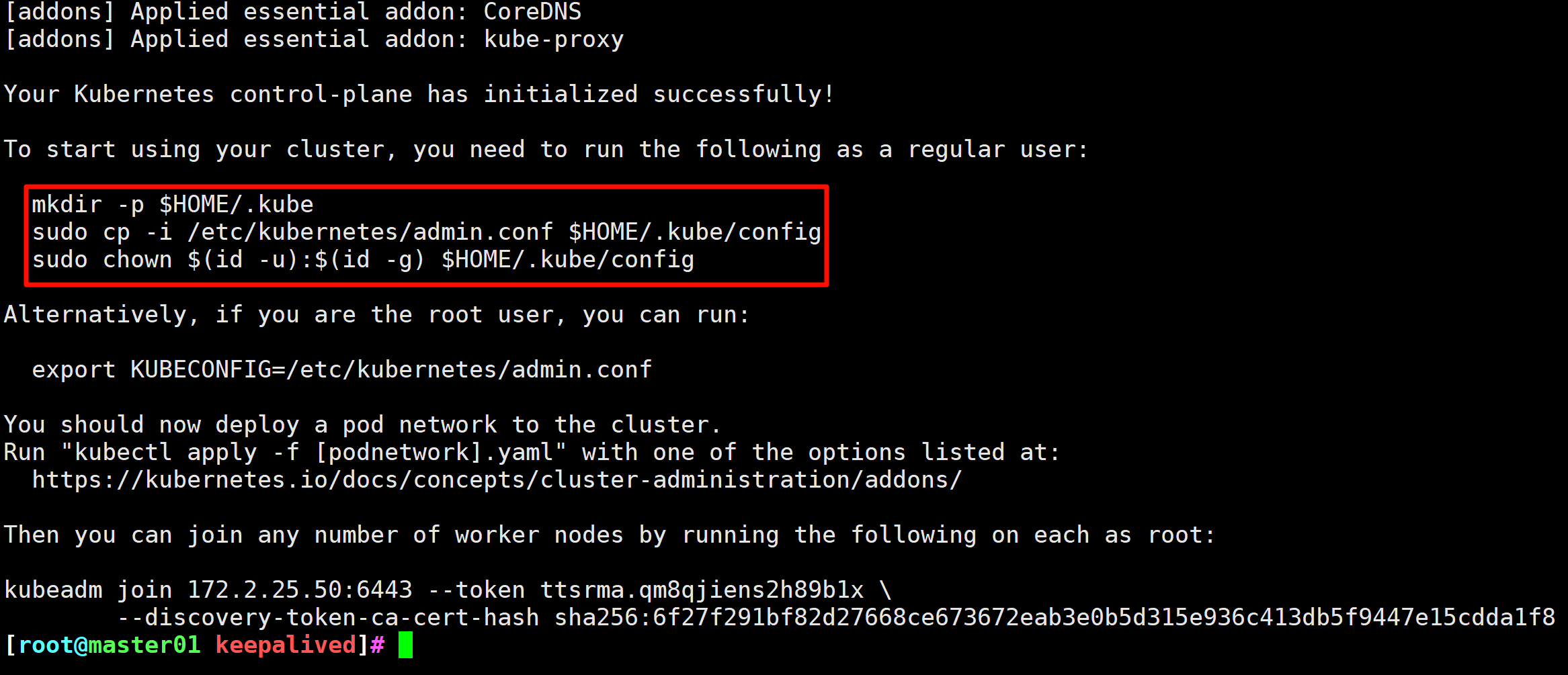
# 在第一台节点上执行初始化操作
[root@master01 opt]# kubeadm init --kubernetes-version=v1.23.17 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=172.22.0.0/16 --service-cidr=172.125.0.0/16 --service-dns-domain=xy.com --apiserver-advertise-address=172.2.25.50
# 如果有多块物理网卡时 --apiserver-advertise-address很有效,单块网卡无需配置此选项。
# 初始化成功,执行这三条命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
图3 初始化成功,并让Node节点加入
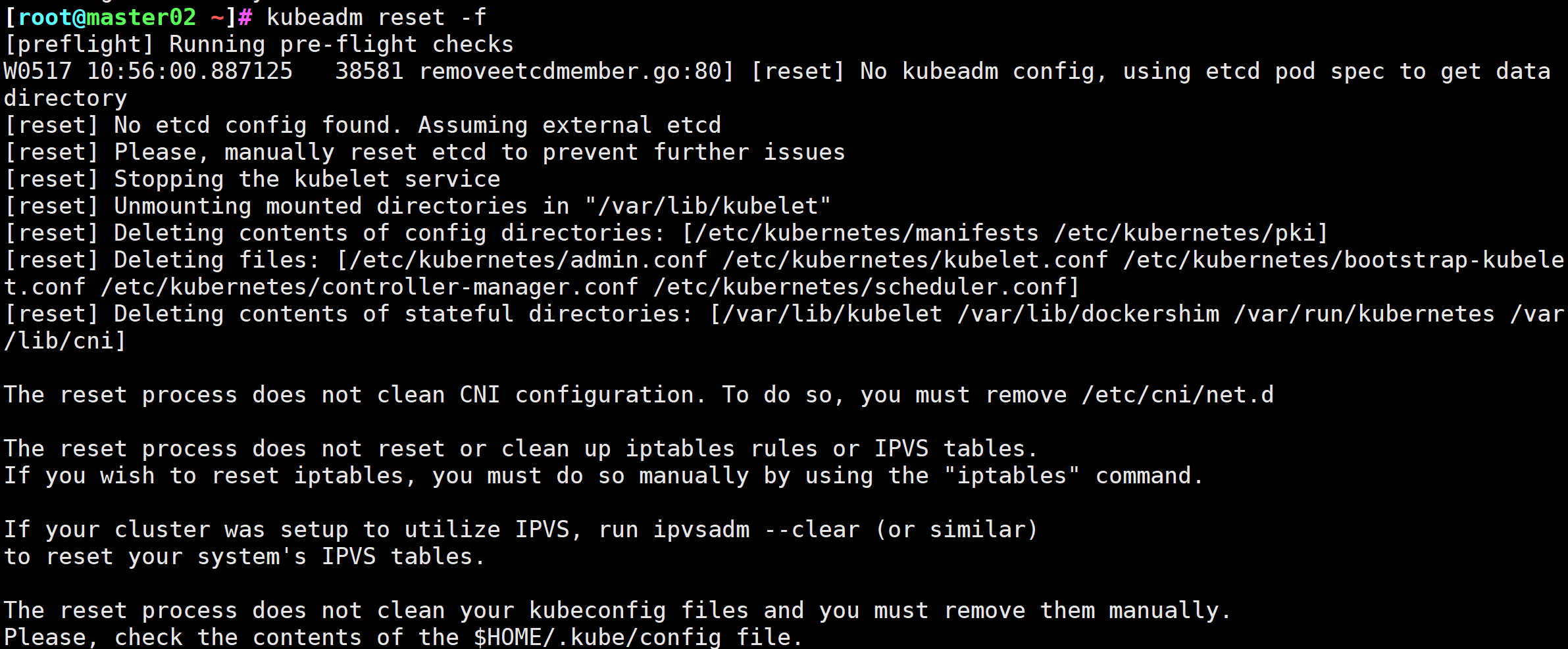
# 如果初始化失败执行下面这条命令
[root@master02 ~]# kubeadm reset -f
图4 初始化失败执行这条命令
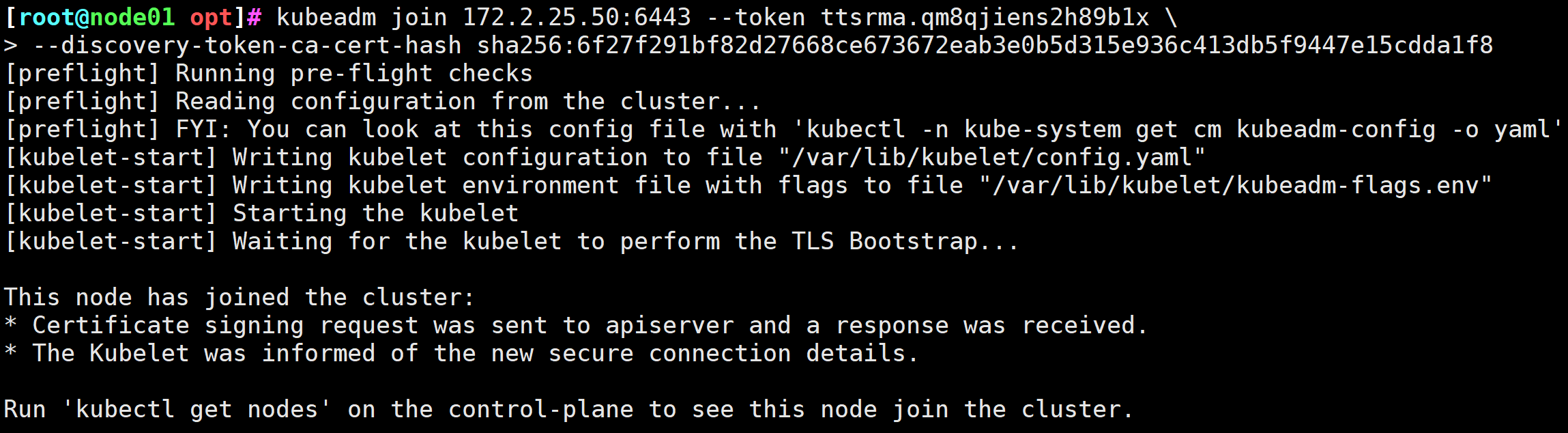
[root@node01 opt]# kubeadm join 172.2.25.50:6443 --token ttsrma.qm8qjiens2h89b1x \
> --discovery-token-ca-cert-hash sha256:6f27f291bf82d27668ce673672eab3e0b5d315e936c413db5f9447e15cdda1f8
图5 添加work节点成功
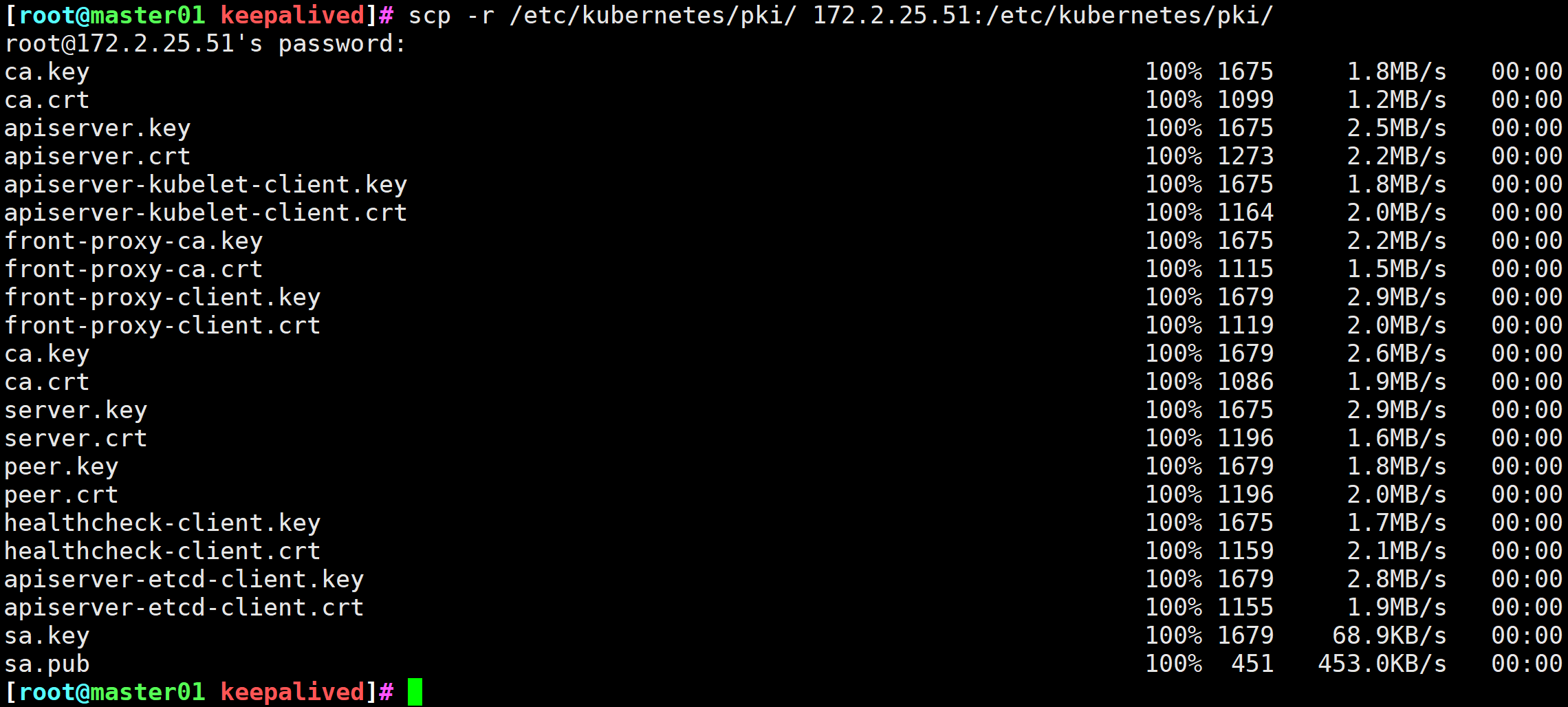
# 拷贝证书到Master02节点,先在master02创建目录
[root@master02 ~]# mkdir -pv /etc/kubernetes/pki/etcd/
# 在Master01拷贝证书到master02节点
[root@master01 ~]# scp -r /etc/kubernetes/pki/ca.crt root@172.2.25.51:/etc/kubernetes/pki/
[root@master01 ~]# scp -r /etc/kubernetes/pki/ca.key root@172.2.25.51:/etc/kubernetes/pki/
[root@master01 ~]# scp -r /etc/kubernetes/pki/sa.key root@172.2.25.51:/etc/kubernetes/pki/
[root@master01 ~]# scp -r /etc/kubernetes/pki/sa.pub root@172.2.25.51:/etc/kubernetes/pki/
[root@master01 ~]# scp -r /etc/kubernetes/pki/front-proxy-ca.crt root@172.2.25.51:/etc/kubernetes/pki/
[root@master01 ~]# scp -r /etc/kubernetes/pki/front-proxy-ca.key root@172.2.25.51:/etc/kubernetes/pki/
[root@master01 ~]# scp -r /etc/kubernetes/pki/etcd/ca.crt root@172.2.25.51:/etc/kubernetes/pki/etcd/
[root@master01 ~]# scp -r /etc/kubernetes/pki/etcd/ca.key root@172.2.25.51:/etc/kubernetes/pki/etcd/
图6 拷贝证书
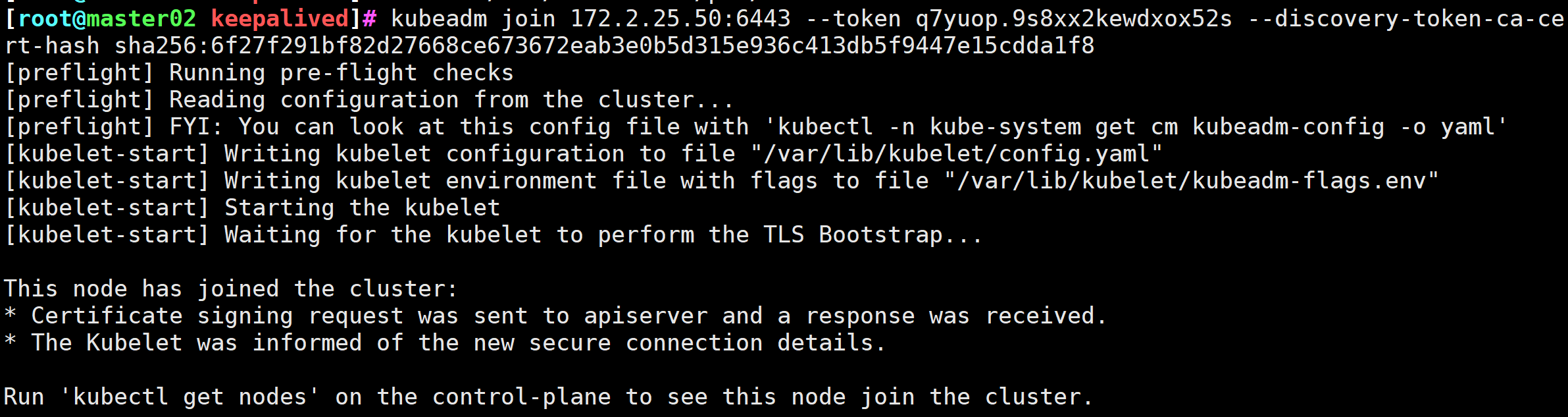
# 在Master01节点生成加入控制节点的Token
[root@master02 keepalived]# rm -rf /etc/kubernetes/pki/ca.crt
[root@master01 keepalived]# kubeadm token create --print-join-command
kubeadm join 172.2.25.50:6443 --token q7yuop.9s8xx2kewdxox52s --discovery-token-ca-cert-hash sha256:6f27f291bf82d27668ce673672eab3e0b5d315e936c413db5f9447e15cdda1f8
图7 加入控制节点成功
# 编写flannel配置文件
[root@master01 opt]# cat kube-flannel.yml
apiVersion: v1
kind: Namespace
metadata:
labels:
k8s-app: flannel
pod-security.kubernetes.io/enforce: privileged
name: kube-flannel
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: flannel
name: flannel
namespace: kube-flannel
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: flannel
name: flannel
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: flannel
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-flannel
---
apiVersion: v1
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "172.22.0.0/16",
"EnableNFTables": false,
"Backend": {
"Type": "vxlan"
}
}
kind: ConfigMap
metadata:
labels:
app: flannel
k8s-app: flannel
tier: node
name: kube-flannel-cfg
namespace: kube-flannel
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: flannel
k8s-app: flannel
tier: node
name: kube-flannel-ds
namespace: kube-flannel
spec:
selector:
matchLabels:
app: flannel
k8s-app: flannel
template:
metadata:
labels:
app: flannel
k8s-app: flannel
tier: node
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
containers:
- args:
- --ip-masq
- --kube-subnet-mgr
command:
- /opt/bin/flanneld
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: EVENT_QUEUE_DEPTH
value: "5000"
image: docker.io/flannel/flannel:v0.25.6
name: kube-flannel
resources:
requests:
cpu: 100m
memory: 50Mi
securityContext:
capabilities:
add:
- NET_ADMIN
- NET_RAW
privileged: false
volumeMounts:
- mountPath: /run/flannel
name: run
- mountPath: /etc/kube-flannel/
name: flannel-cfg
- mountPath: /run/xtables.lock
name: xtables-lock
hostNetwork: true
initContainers:
- args:
- -f
- /flannel
- /opt/cni/bin/flannel
command:
- cp
image: docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel2
name: install-cni-plugin
volumeMounts:
- mountPath: /opt/cni/bin
name: cni-plugin
- args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
command:
- cp
image: docker.io/flannel/flannel:v0.25.6
name: install-cni
volumeMounts:
- mountPath: /etc/cni/net.d
name: cni
- mountPath: /etc/kube-flannel/
name: flannel-cfg
priorityClassName: system-node-critical
serviceAccountName: flannel
tolerations:
- effect: NoSchedule
operator: Exists
volumes:
- hostPath:
path: /run/flannel
name: run
- hostPath:
path: /opt/cni/bin
name: cni-plugin
- hostPath:
path: /etc/cni/net.d
name: cni
- configMap:
name: kube-flannel-cfg
name: flannel-cfg
- hostPath:
path: /run/xtables.lock
type: FileOrCreate
name: xtables-lock
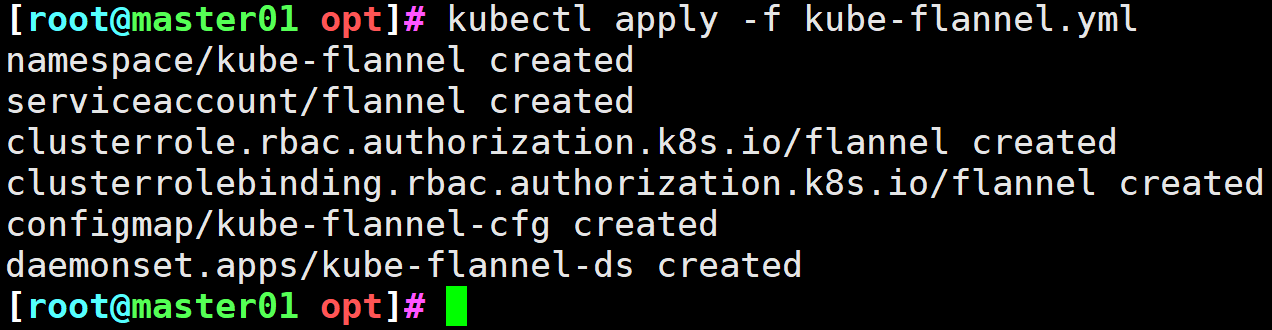
# 执行yml文件,安装flannel组件
[root@master01 opt]# kubectl apply -f kube-flannel.yml
namespace/kube-flannel created
serviceaccount/flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
图8 执行flannel安装脚本
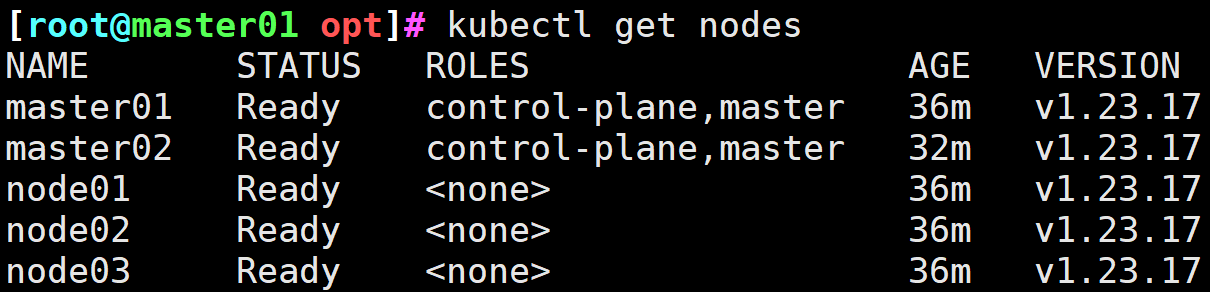
图9 看到两个节点为控制平面节点
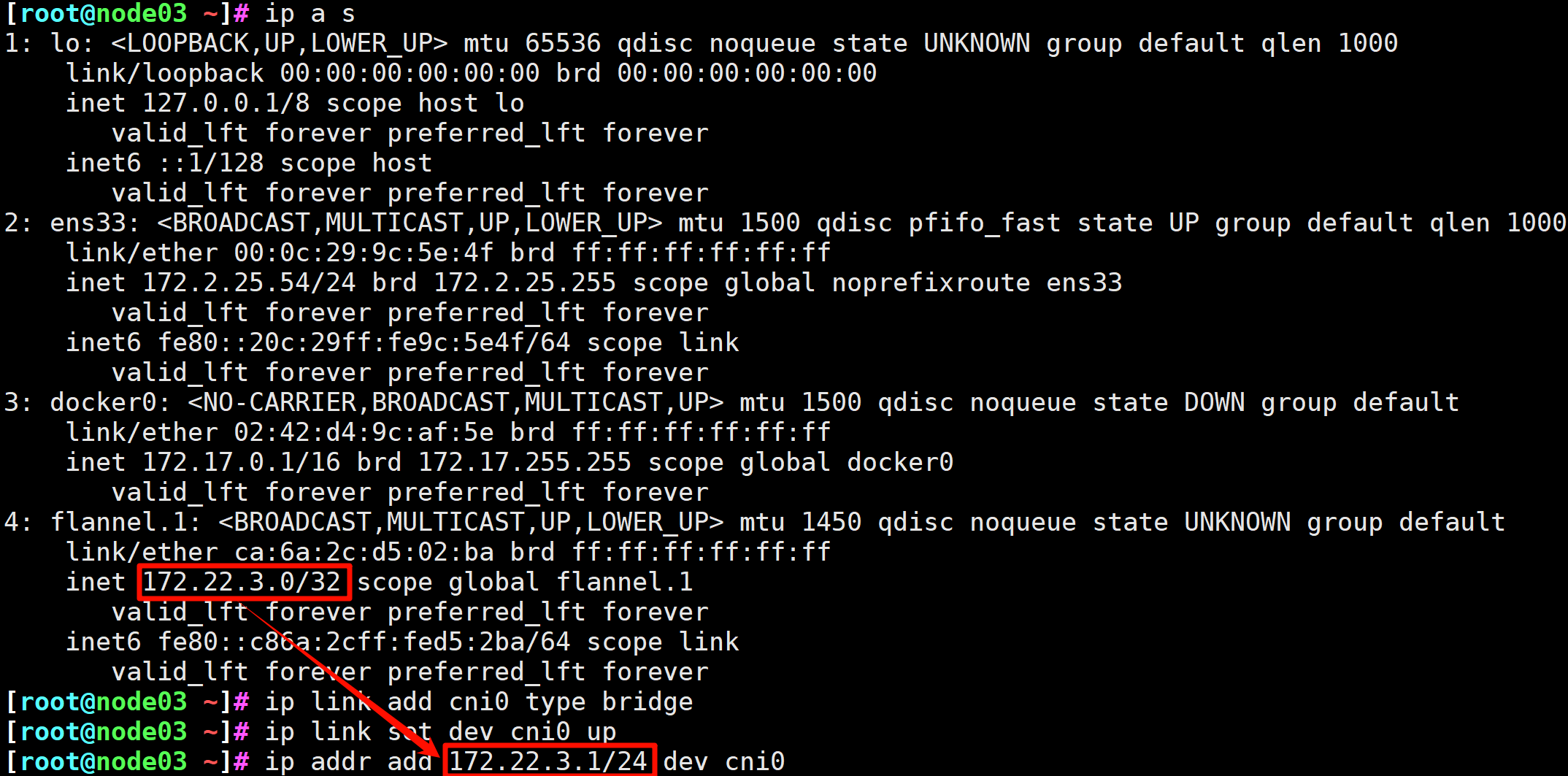
# 此时,我们使用ip a s查看ip的时候会看到flannel.1和cni0网卡
# 如果缺少,使用命令添加
# fannel网卡cni0网卡缺失解决方案
# 问题描述
# 部分节点不存在cni0网络设备,仅有flannel.1设备,此时我们需要手动创建cni0网桥设备哟。
# 解决方案
# 如果有节点没有cni0网卡,建议大家手动创建相应的网桥设备,但是注意网段要一致
# 手动创建cni0网卡
# 假设 K8s01的flannel.1是172.22.0.0网段。
# 添加网卡,注意网段
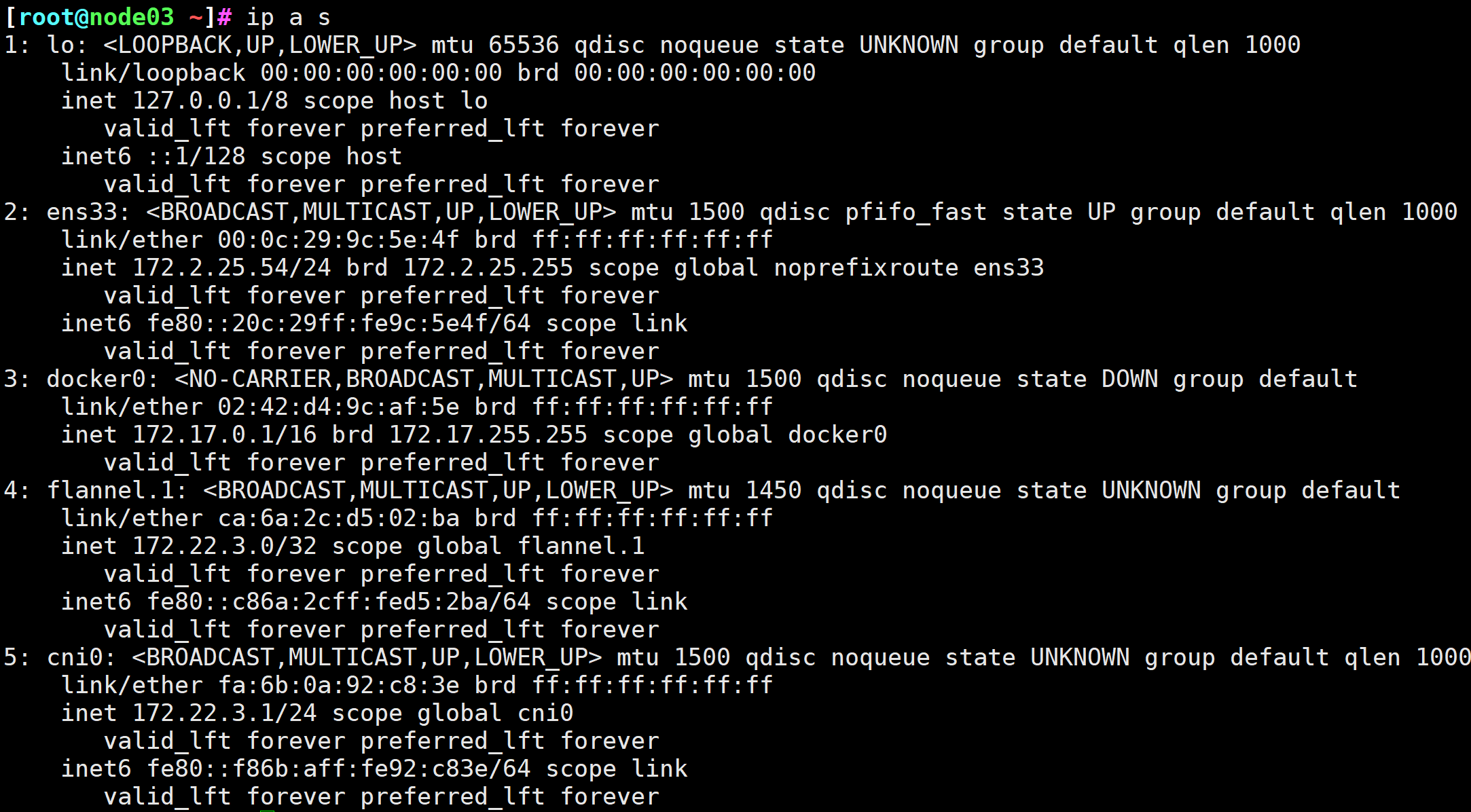
[root@node03 ~]# ip link add cni0 type bridge
[root@node03 ~]# ip link set dev cni0 up
[root@node03 ~]# ip addr add 172.22.3.1/24 dev cni0
图10 注意flannel.1和cni0的网段是对应的
图11 可以看到新创建的网卡
# 使用kubectl工具实现自动补全功能
[root@master01 ~]# kubectl completion bash > ~/.kube/completion.bash.inc
[root@master01 ~]# echo source '$HOME/.kube/completion.bash.inc' >> ~/.bashrc
[root@master01 ~]# source ~/.bashrc
图12 可以看到成功自动补全
# K8s巡检脚本
[root@master01 opt]# cat xunjian.sh
#!/bin/bash
# 定义颜色代码
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[0;33m'
NC='\033[0m' # No Color
# 1. 检查master组件状态
echo -e "${YELLOW}=== 检查master组件状态 ===${NC}"
kubectl get cs 2>/dev/null | while read -r line; do
if [[ "$line" =~ "NAME" ]]; then
continue
fi
if [ -n "$line" ]; then
component=$(echo "$line" | awk '{print $1}')
status=$(echo "$line" | awk '{print $2}')
if [ "$status" != "Healthy" ]; then
echo -e "${RED}警告: $component 状态异常: $status${NC}"
else
echo -e "${GREEN}$component 状态正常: $status${NC}"
fi
fi
done
# 2. 检查工作节点状态
echo -e "\n${YELLOW}=== 检查工作节点状态 ===${NC}"
kubectl get nodes -o wide | while read -r line; do
if [[ "$line" =~ "NAME" ]]; then
continue
fi
if [ -n "$line" ]; then
node=$(echo "$line" | awk '{print $1}')
status=$(echo "$line" | awk '{print $2}')
if [ "$status" != "Ready" ]; then
echo -e "${RED}警告: 节点 $node 状态异常: $status${NC}"
else
echo -e "${GREEN}节点 $node 状态正常: $status${NC}"
fi
fi
done
# 3. 检查flannel组件状态
echo -e "\n${YELLOW}=== 检查flannel组件状态 ===${NC}"
kubectl get pods -n kube-flannel -o wide | while read -r line; do
if [[ "$line" =~ "NAME" ]]; then
continue
fi
if [ -n "$line" ]; then
pod=$(echo "$line" | awk '{print $1}')
status=$(echo "$line" | awk '{print $3}')
restarts=$(echo "$line" | awk '{print $4}')
node=$(echo "$line" | awk '{print $7}')
if [ "$status" != "Running" ]; then
echo -e "${RED}警告: Pod $pod 在节点 $node 上状态异常: $status (重启次数: $restarts)${NC}"
else
echo -e "${GREEN}Pod $pod 在节点 $node 上运行正常: $status (重启次数: $restarts)${NC}"
fi
fi
done
# 4. 检查cni0和flannel网卡是否存在
echo -e "\n${YELLOW}=== 检查网络接口 ===${NC}"
for node in $(kubectl get nodes -o jsonpath='{.items[*].metadata.name}'); do
echo -e "\n${YELLOW}检查节点 $node:${NC}"
if [ "$node" == "master231" ]; then
# 如果是本地节点,直接检查
cni0_exists=$(ip link show cni0 2>/dev/null | grep -q "cni0" && echo "存在" || echo "不存在")
flannel_exists=$(ip link show flannel.1 2>/dev/null | grep -q "flannel.1" && echo "存在" || echo "不存在")
else
# 如果是远程节点,通过SSH检查(需要配置SSH免密登录)
cni0_exists=$(ssh "$node" "ip link show cni0 2>/dev/null | grep -q 'cni0'" 2>/dev/null && echo "存在" || echo "不存在")
flannel_exists=$(ssh "$node" "ip link show flannel.1 2>/dev/null | grep -q 'flannel.1'" 2>/dev/null && echo "存在" || echo "不存在")
fi
if [ "$cni0_exists" != "存在" ]; then
echo -e "${RED}警告: 节点 $node 上缺少cni0接口${NC}"
else
echo -e "${GREEN}节点 $node 上cni0接口存在${NC}"
fi
if [ "$flannel_exists" != "存在" ]; then
echo -e "${RED}警告: 节点 $node 上缺少flannel.1接口${NC}"
else
echo -e "${GREEN}节点 $node 上flannel.1接口存在${NC}"
fi
done
# 5. 验证网络是否正常
echo -e "\n${YELLOW}=== 验证网络连通性 ===${NC}"
# 测试节点间的网络连通性
nodes=($(kubectl get nodes -o jsonpath='{.items[*].metadata.name}'))
for i in "${!nodes[@]}"; do
for j in "${!nodes[@]}"; do
if [ "$i" -ne "$j" ]; then
src_node="${nodes[$i]}"
dest_node="${nodes[$j]}"
echo -e "\n测试从 $src_node 到 $dest_node 的网络连通性..."
# 获取目标节点的IP
dest_ip=$(kubectl get nodes "$dest_node" -o jsonpath='{.status.addresses[?(@.type=="InternalIP")].address}')
if [ "$src_node" == "master231" ]; then
# 本地节点测试
ping_result=$(ping -c 3 "$dest_ip" | grep -E "packets transmitted|0% packet loss")
else
# 远程节点测试(需要配置SSH免密登录)
ping_result=$(ssh "$src_node" "ping -c 3 $dest_ip" 2>/dev/null | grep -E "packets transmitted|0% packet loss")
fi
if [[ "$ping_result" =~ "0% packet loss" ]]; then
echo -e "${GREEN}网络连通性正常: $src_node 可以访问 $dest_node ($dest_ip)${NC}"
else
echo -e "${RED}警告: 网络连通性问题: $src_node 无法正常访问 $dest_node ($dest_ip)${NC}"
echo -e "详细信息: $ping_result"
fi
fi
done
done
echo -e "\n${YELLOW}=== 巡检完成 ===${NC}"
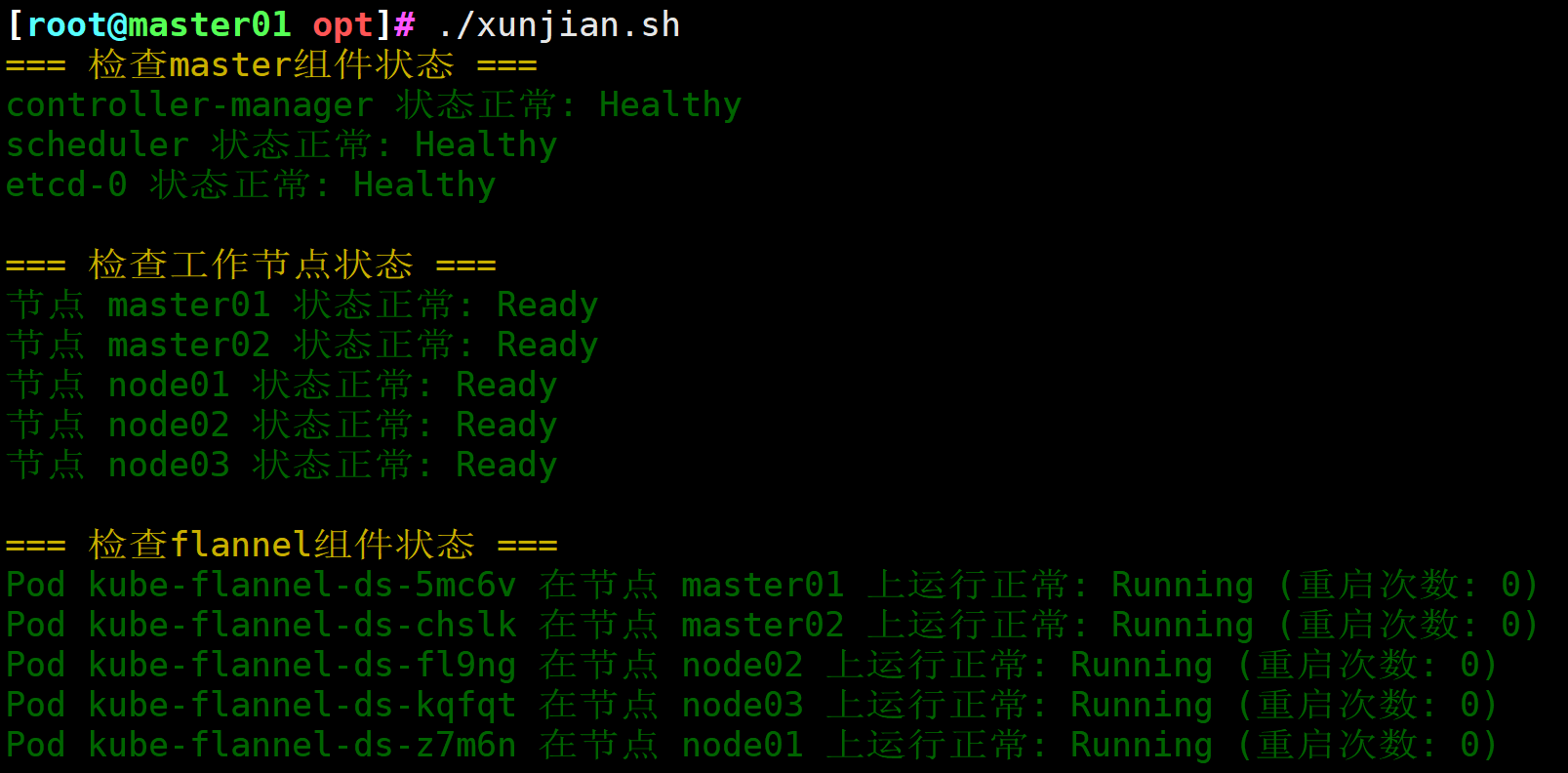
图13 巡检结果



























 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









