







 本文介绍了Hadoop MapReduce计算模型,包括JobTracker和TaskTracker的角色。MapReduce任务由Job初始化,分为Map和Reduce阶段。Map函数处理输入,Reduce函数处理中间结果。文章详细讲解了MapReduce的split、Map、Shuffle和Reduce四个执行阶段。
本文介绍了Hadoop MapReduce计算模型,包括JobTracker和TaskTracker的角色。MapReduce任务由Job初始化,分为Map和Reduce阶段。Map函数处理输入,Reduce函数处理中间结果。文章详细讲解了MapReduce的split、Map、Shuffle和Reduce四个执行阶段。
MapReduce计算模型
在Hadoop中,用于执行MapReduce任务的机器有两份角色:JobTracker和TaskTracker。JobTracker用于管理和调度工作,TaskTracker是用来执行工作的,一个Hadoop集群中只有一个JobTracker。
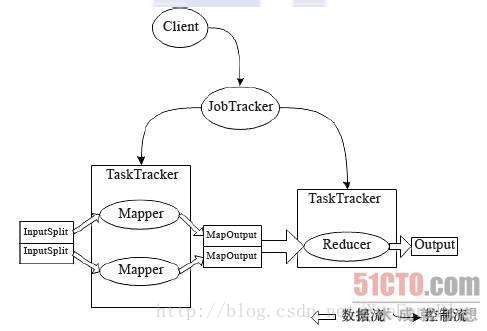
MapReduce Job
在Hadoop中,每个MapReduce任务会被初始化一个Job。每个Job可以分为Map阶段和Reduce阶段,可用Map和Reduce函数来表示。
Map函数接受一个<key,value>形式的输入,产生一个同样为<key,value>形式的中间输出,Hadoop将具有相同Key值的value集合到一起传递给Reduce函数,Reduce函数接受了一个如<key,list of value>形式的输入,Reduce对此进行处理,输出<key,value>形式的数据。
MapReduce 的四个阶段
Split阶段
Map阶段
Shuffle阶段
Reduce阶段




















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









