







##MapReduce计算模型
在Hadoop中,用于执行MapReduce任务的机器有两份角色:JobTracker和TaskTracker。JobTracker用于管理和调度工作,TaskTracker是用来执行工作的,一个Hadoop集群中只有一个JobTracker。
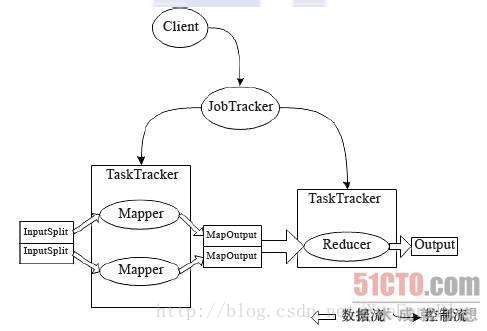
MapReduce Job
在Hadoop中,每个MapReduce任务会被初始化一个Job。每个Job可以分为Map阶段和Reduce阶段,可用Map和Reduce函数来表示。
Map函数接受一个<key,value>形式的输入,产生一个同样为<key,value>形式的中间输出,Hadoop将具有相同Key值的value集合到一起传递给Reduce函数,Reduce函数接受了一个如<key,list of value>形式的输入,Reduce对此进行处理,输出<key,value>形式的数据。

MapReduce入门程序WordCount
Map阶段
public class WordCount {
//输入key类型,value类型,输出key类型,value类型
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
//one表示单词出现一次
private final IntWritable one = new IntWritable(1);
//word用于存储切下的单词
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//对输入的行切词
StringTokenizer token = new StringTokenizer(value.toString());
while (token.hasMoreTokens()) {
//切下的单词存入word
word.set(token.nextToken());
//用context将key,value输出
context.write(word, one);
}
}
}Reduce阶段
public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
//输入key类型,value类型,输出key类型,value类型
//输入的格式是<key,list of value>形式
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
//计算value的和
for (IntWritable val : values) {
sum += val.get();
}
//用context将key,value输出
context.write(key, new IntWritable(sum));
}
} public static void main(String[] args) throws Exception {
//定义文件的输入输出地址
String[] paths = { "hdfs://master:9000/pxf/input/*.txt",
"hdfs://master:9000/pxf/output" };
//调用conf类来对MapReduce Job进行初始化并命名
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setJarByClass(WordCount.class);
//设置Job输出结果<key,value>的中key和value数据类型
//因为结果是<单词,个数>,所以key设置为"Text"类型,相当于Java中String类型。
//Value设置为"IntWritable",相当于Java中的int类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置Job处理的Map(拆分)、以及Reduce(合并)的相关处理类
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(paths[0]));
FileOutputFormat.setOutputPath(job, new Path(paths[1]));
job.waitForCompletion(true);
}
}














 4450
4450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









