






想要了解更多,可联系作者
625338393 v请备注来意,模块A环境搭建,模块B离线数据处理,模块E数据可视化
本机环境说明:
| 设备类型 | 软件类别 | 软件名称、版本号 |
| 服务器 | 大数据集群操作系统 | CentOS 7 |
| 大数据平台组件 | Hadoop 3.1.3 | |
| Hive 3.1.2 | ||
| Spark 3.1.1 | ||
| JDK 1.8 | ||
| 关系型数据库 | MySQL 5.7 | |
| PC机 | PC操作系统 | Ubuntu18.04 64位 |
| 开发语言 | Scala 2.12 | |
| 开发工具 | IDEA 2022(Community Edition) | |
| SSH工具 | Asbru-cm | |
| 文档编辑器 | WPS Linux版 | |
| 输入法 | 搜狗拼音输入法Linux版 |
补充环境说明:
服务端使用Asbru工具或SSH客户端进行SSH访问,主节点MySQL数据库用户名密码:root/1234(已设置远程连接)
Hive的配置文件位于/opt/module/hive/conf
Spark任务在Yarn上用Client运行,方便观察日志
子任务一:数据抽取
编写Scala代码,使用Spark将MySQL的shtd_store库中表user_info、sku_info、base_province、base_region、order_info、order_detail的数据增量抽取到Hive的ods库中对应表user_info、sku_info、base_province、base_region、order_info、order_detail中。
- 抽取shtd_store库中user_info的增量数据进入Hive的ods库中表user_info。根据ods.user_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这两个字段中较大的时间进行比较),只将新增的数据抽入,字段名称、类型不变,同时添加静态分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.user_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
说明:数据根据2023年任务书数据进行模拟,由于本人学校并没有服务器,所以环境纯为自己模拟,希望有经验的同学可以来向我指正,一起学习
1、创建ods库原始数据(比赛没有这一步,比赛库中有数据)
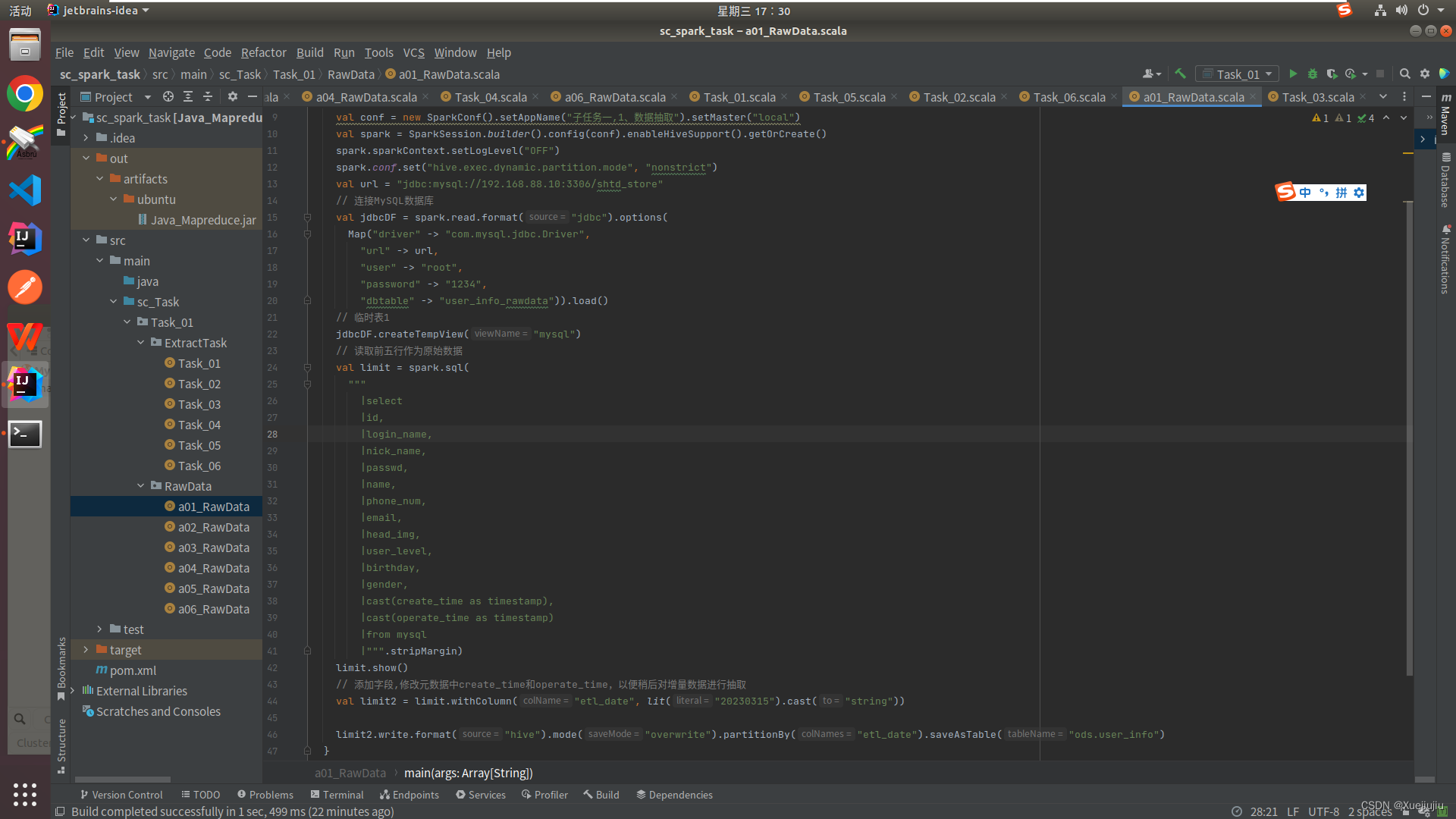
2、编写Scala代码,完成任务

3、打包程序,并发送至主机端

4、提交Spark作业

5、程序完成后,执行 show partitions ods.user_info命令

6、将任务粘贴至文件下
















 1352
1352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









