







文章目录
前言
在介绍这两大接口之前,先简单回顾下之前所说的,Java中提供了很多现成的类和接口供开发者使用,这些类和接口中有各种各样的方法开发者只需使用import导入后即可直接使用。
Java开发中常用的包:
java.lang :系统的基础类所在的包,String,Object (万物之母)此包JDK1.1开始默认导入
java.util:工具包,集合类都在这个包中Scanner
java.io : IO开发包,输入输出工具包
java.net :网络编程开发包
Socketjava.sql:数据库编程开发包
java.lang.reflect:反射开发包,反射是所有框架的基础
而本篇要讲的两个接口正是来自于java.lang包下的。
一、java.lang.Comparable
顾名思义,comparable接口是用来实现比较功能的,换句话说,当一个类实现了comparable接口,那这个类就具备了可比较的能力。先来看看源码:
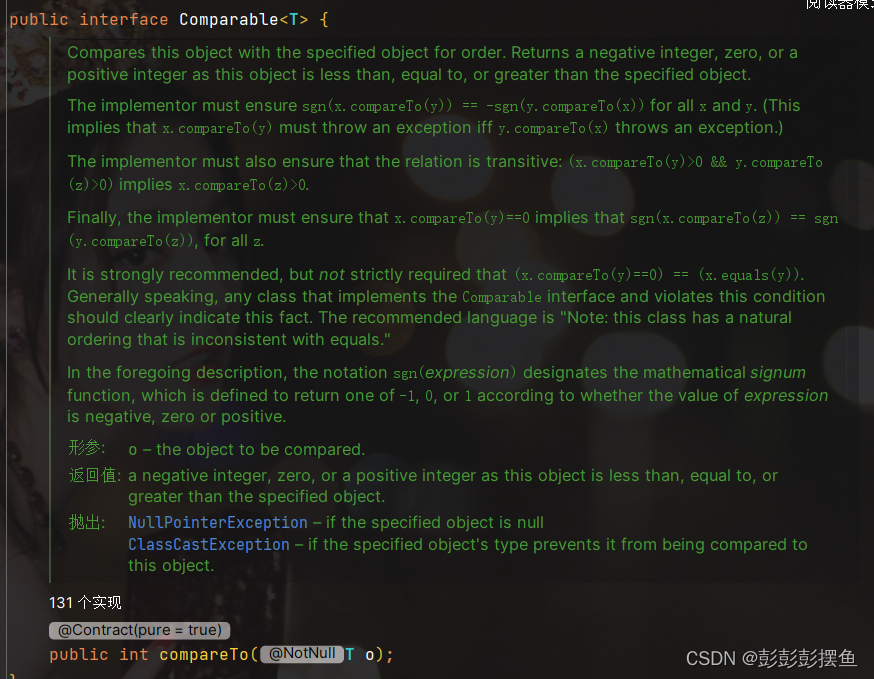
可以看到,其内部只有一个compareTo抽象方法, 返回值是int类型。
1、问题来了
当我们在编译器中自定义了一个Student类时,当我们使用这个类创建了一个对象数组,此时如果想对这个对象数组进行排序,那么如何排序呢?

tips:创建对象数组后并没有产生新的对象,所有数组的值默认都是null,后面四条语句才是创建新对象放入数组中。
对于两个不同的student对象来说,有可能按照年龄比较大小,也有可能按照分数比较大小,有的场景还需要按照姓名比大小。编译器就不知道到底按照哪些属性去比较两个Student对象的大小关系了。 对于自定义的类,java编译器并不知道按照这个类中哪个属性去决定谁大谁小。不像基本类型int [ ] 就是按照数值大小去比较。
2、解决办法
对于自定义的类,要让它具备可比较的能力,可以实现java.lang.Comparable接口,覆写其中的compareTo方法
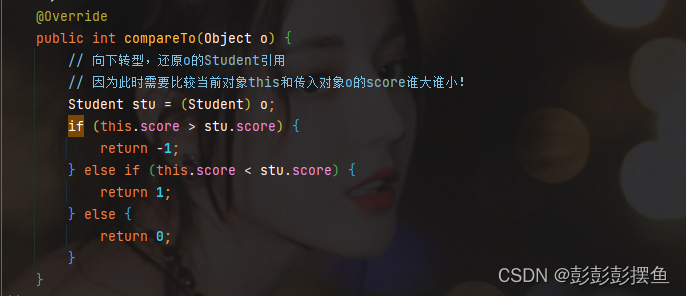
这里将compareTo进行重写,比较的是两个学生类的成绩,当我们把score换成age,就是根据年龄来进行比较了。
关于返回值:
在JVM看来,它只看方法的返回值,返回值<0就认为当前对象是小于传入对象的,返回>0就认为当前对象大于传入对象。
可以利用该返回值,当返回值小于0时,将传入对象与当前对象进行位置交换
我们写一个对Student进行排序的方法:

与冒泡排序类似,但是这里时根据重写的compareTo的返回值来决定是否进行交换,形参中的comparable其实就是Student这个类。
arr [j] .compareTo(arr [j+1])>0 :该条语句就是判断方法的返回值,从而得出j处的对象和j+1处的对象谁的score更大。
当返回值>0时,证明j+1处的是大于j处的 进行交换。
isSwaped只是提高代码效率的,这个无关紧要。
另外,我们还可以重写Object类里的toString方法 来打印对象数组里的每个对象(因为java里所有类都默认是Object类的子类,所以都有tostring方法)
在Student类中写一个showStu方法来打印学生信息:

写到这里,就已经可以对Student对象数组进行排序了!并且可以根据其中的任意属性来进行排序(只要这个属性可以比较)下面看一下测试代码:
public class Test {
public static void main(String[] args) {
// 数组有个工具类Arrays.sort(数组对象) 排序,默认排升序
int[] data = new int[] {1,6,4,2,3,9,8,7,5};
// 调用JDK的默认排序方法,默认升序排序
Arrays.sort(data);
System.out.println(Arrays.toString(data));
// 创建了一个对象数组
Student[] students = new Student[4];
students[1] = new Student("彭于晏",90,35);
students[0] = new Student("吴彦祖",80,39);
students[2] = new Student("胡歌",60,36);
students[3] = new Student("霍建华",100,40);
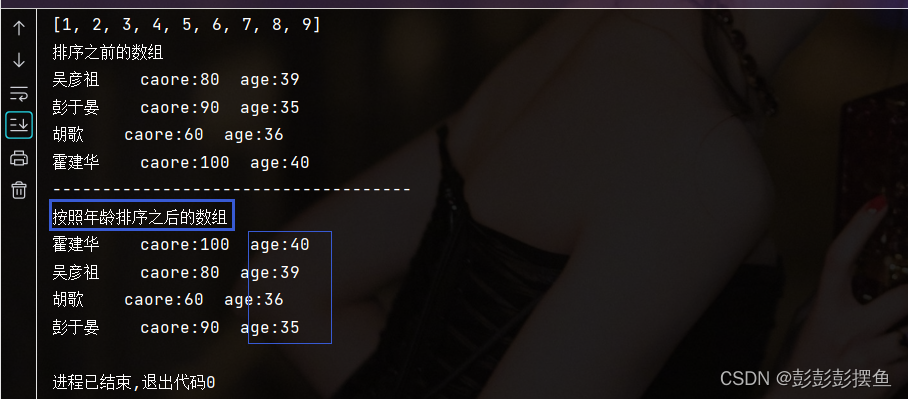
System.out.println("排序之前的数组");
for (Student stu : students) {
stu.showStu();
}
// 我想现在根据每个学生的成绩进行排序,按照分数升序排序
sort(students);
System.out.println("------------------------------------");
System.out.println("按照成绩排序之后的数组");
for (Student stu : students) {
stu.showStu();
}
}
/**
* 调用sort方法时,不知道也不关心具体的子类是什么类型,只要子类实现了Comparable接口
* 都可以调用sort方法!
* 这就是向上转型的参数统一化
* @param arr
*/
public static void sort(Comparable[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
boolean isSwaped = false;
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j].compareTo(arr[j + 1]) > 0) {
Comparable tmp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = tmp;
isSwaped = true;
}
}
// 内层没有元素交换,整个区间已经有序
if (!isSwaped) {
break;
}
}
}
}
运行结果:
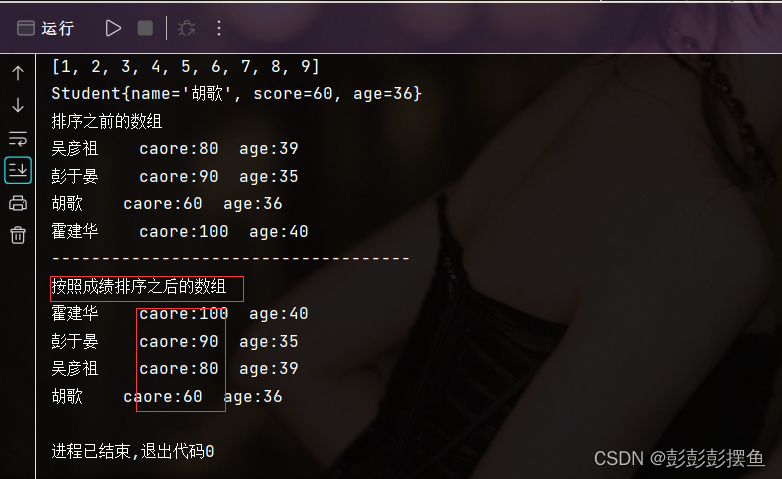
当我们把compareTo中的score改为age后,此时排序则是按照年龄来排序的:
以上,就是Comparable的具体使用方法和原理!也表明了接口的便利性和实用性,有了这个接口,万物皆可比较!
二、java.lang.Clonable
1、干什么用的
先谈谈为什么需要这个接口,按道理来说,当我们需要复制一个变量时例如 student a=(age:10); 复制它只需要一句 student b=a;就行了。
但是,这种复制相当于创建了两个引用来指向了同一个对象,即 相当于在内存中,有一块内存存储了10这个数,变量a指向这块内存,变量b=a实际上是也指向了a指向的内存。(这也是后面要讲的浅拷贝)
我们需要的克隆,是产生一个新的,完全独立的,即使a没了b丝毫不受影响的对象。A和B除了地址不同,其他完全相同,这种操作就称之为对象的克隆。
当一个类实现了Clonable接口,这个类就具备了可以被克隆的能力。看看源码:
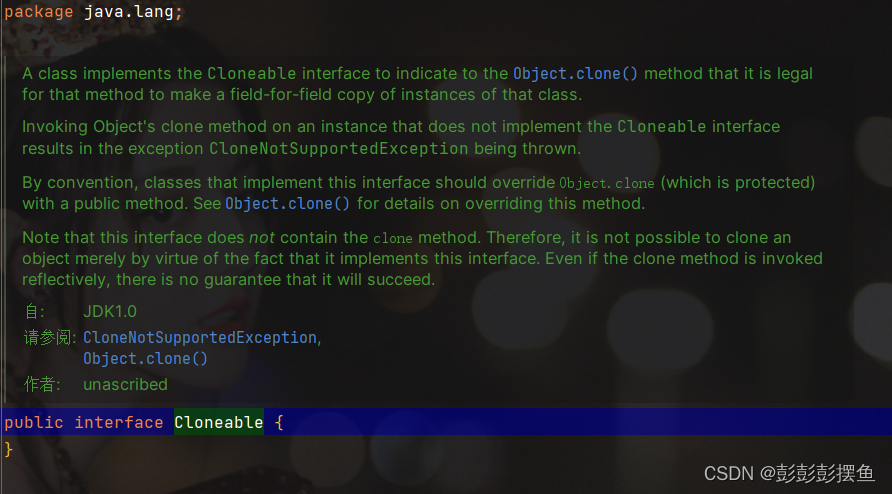
奇怪的是,这个接口没有任何的抽象方法!,在java中,这种接口称之为标记接口 ,JVM只会识别所有带这个clonable接口的子类,打上可以复制的标记。
如何理解标记?
猪厂在猪成熟之后,准备拉去宰了之前,会有专门的检验人员检查猪的身高体重以及健康情况,若都正常,就拿个章子在猪屁股上盖个"检验合格"章,这个章就是标记!
屠宰厂只会识别所有屁股上带"合格"标记的猪处理,没有这个标记就不处理
2、如何使用
使用方法其实已经写在上面了hhh,毕竟没有方法需要覆写,当一个类implements了该接口后,就可以通过调用Object里的clone方法实现自己的克隆方法了。
先把代码贴上(不停截图真的🤮了):
public class Person implements Cloneable{
private String name;
private int age;
public Person clone() {
Person per = null;
try {
// Object类的clone方法,所有对象都有,但是只有实现了Cloneable接口的子类才能真正使用
per = (Person) super.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException(e);
}
return per;
}
//构造方法
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public void showPer() {
System.out.println("this.name = " + name + ",this.age = " + age + ",sal = " + money.sal);
}
public static void main(String[] args) {
Person per = new Person("彭于晏",18);
// 这个不是对象clone,两个引用,一个对象
Person per1 = per.clone();
System.out.println(per1);
System.out.println(per);
per1.showPer();
per.showPer();
}
}
clone方法是Object类内的方法,我们需要自己定义一个返回值是Person类的方法,在写时使用super.clone()调用父类Object中的方法,修改其返回值类型,否则就会报错。运行上面那段代码:
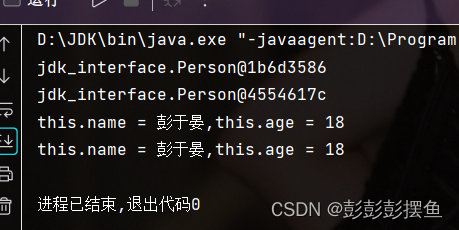
可以看到这两个变量除了地址不同,内容完全相同。这就完成了一次拷贝。而不是像per1=per这样简单的将per1指向per所指向的地址
没有实现Clonable接口,即没有打上“标签”,在主函数调用clone方法就会报错

三、拓展:深拷贝与浅拷贝
深浅拷贝是针对引用数据类型的概念,因为基本数据类型在赋值时就会开辟了物理空间。(下一篇准备写一下java中几个特殊的类,感兴趣可以点点关注~)
1、浅拷贝
浅拷贝:对象内部若包含其他类对象,浅拷贝只会复制其地址,并不会产生新的对象。
举栗子:
比如说在上面的代码中添加一个内部类Money,将其作为属性添加进Preson中:
class Money {
double sal = 100.5;
}
public class Person implements Cloneable{
private String name;
private int age;
Money money = new Money();
public static void main(String[] args) {
Person per = new Person("彭于晏",18);
// 这个不是对象clone,两个引用,一个对象
Person per1 = per.clone();
System.out.println(per1);
System.out.println(per);
per1.showPer();
per.showPer();
System.out.println("修改per的money对象值为66.6");
per.money.sal = 66.6;
System.out.println(per.money.sal);
System.out.println(per1.money.sal);
}
public Person clone() {
Person per = null;
try {
// Object类的clone方法,所有对象都有,但是只有实现了Cloneable接口的子类才能真正使用
per = (Person) super.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException(e);
}
return per;
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public void showPer() {
System.out.println("this.name = " + name + ",this.age = " + age + ",sal = " + money.sal);
}
}
此时运行上述代码可以看到:
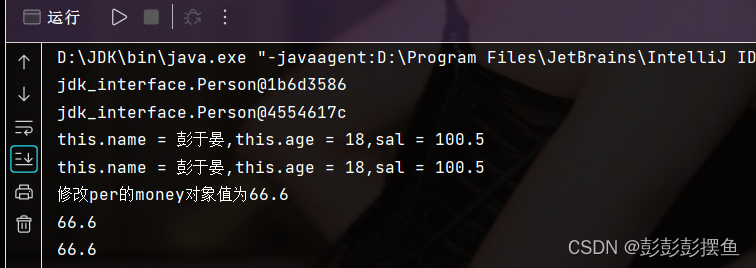
划重点!!:
我们拷贝了per中的属性给了per1,包括内部的Money引用,但这里的引用拷贝时仅仅拷贝了money的地址,并没有将money中的值拷贝过来,所以当修改per中money的值时,per1中money的值也随之改变了!这就是浅拷贝!!!
浅拷贝只会复制其地址,并不会产生新的对象
浅拷贝时内存的示意图:

2、深拷贝
深拷贝:克隆对象内部若包含其他对象的引用,会创建新的对象,将原对象的内容复制过来
那么如果在拷贝per1时,将其中的Money也拷贝一份呢,这样做的话就属于深拷贝了,关键在于,如何办到?
方法上面已经说了其实,那就是让Money类也实现Clonable接口,并且在Person的clone方法中加上克隆money属性。
代码更改如下(我将不同的地方标注了出来):
class Money implements Cloneable{
double sal = 100.5;
//**************************************************
public Money clone() {
try {
return (Money) super.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException(e);
}
}
//***************************************************
}
public class Person implements Cloneable{
private String name;
private int age;
Money money = new Money();
public static void main(String[] args) {
Person per = new Person("彭于晏",18);
// 这个不是对象clone,两个引用,一个对象
Person per1 = per.clone();
System.out.println(per1);
System.out.println(per);
per1.showPer();
per.showPer();
System.out.println("修改per的money对象值为66.6");
per.money.sal = 66.6;
System.out.println(per.money.sal);
System.out.println(per1.money.sal);
}
public Person clone() {
Person per = null;
try {
// Object类的clone方法,所有对象都有,但是只有实现了Cloneable接口的子类才能真正使用
per = (Person) super.clone();
//***************************************************
per.money = money.clone();
//***************************************************
} catch (CloneNotSupportedException e) {
throw new RuntimeException(e);
}
return per;
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public void showPer() {
System.out.println("this.name = " + name + ",this.age = " + age + ",sal = " + money.sal);
}
}
此时再运行上面这段代码可以看到:修改per的值并没有影响到per1,此时的per1就是深拷贝得到的。

划重点!!:
我们拷贝了per中的属性给了per1,包括内部的Money引用,此时这里因为per的clone方法中也包括了Money的克隆,因此在克隆时针对内部的引用类也会开辟一个新的空间将Money中的值复制一份保存了!这就是深拷贝!!!
深拷贝会创建新的对象将原引用对象的内容复制过来
深拷贝时内存示意图:
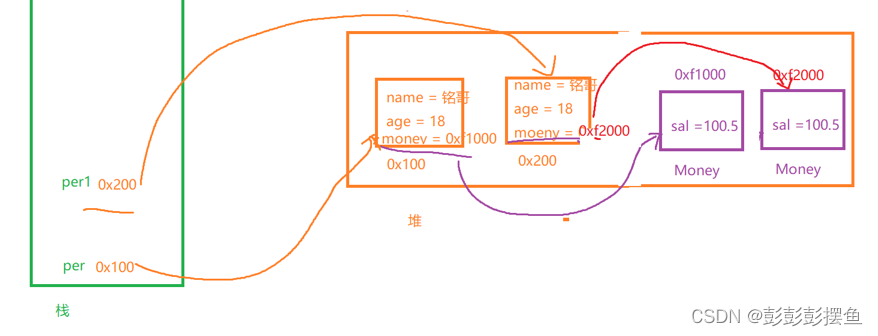
3、深浅拷贝的总结
关于浅拷贝:
个人觉得浅拷贝其实就是引用类型的指来指去,类似于c语言里的指针,创建一个新的指针变量指到一个变量指向的地方就是完成了对该变量的浅拷贝(我是这么理解的,不对的话欢迎指出~)
关于深拷贝:
java中可以递归调用clone方法来实现深拷贝,或者通过序列化的方式实现深拷贝。将任何对象变为字符串的过程就是序列化,从字符串中还原原来对象的过程称之为反序列化。(这些我搜来的,具体怎么码代码怎么实现我是不会的)
深浅拷贝的东西听说面试中问的挺多的,所以觉得还是有必要写一写加深一下理解,以上内容都是下午边总结边想的,有错的地方欢迎各位大佬指出啊哈哈哈。
总结
本篇博客总结了java中常见的两大接口Comparable(通过重写compareTo方法)和Clonable(通过打上标签)的作用和使用方法,同时通过clonable引出并总结了深浅拷贝的相关知识,写了整整一个下午,希望看到的老铁多多支持啊QAQ。下周准备写java中的几个特殊类以及使用(Flag)~















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











