






什么样的技术能经历时间洗礼还历久弥新?
答案或许可以归总为一个“三部曲”般的规律——兴起、发展和大规模应用,外加这个过程再一次演进式的迭代。
以史为鉴,引领第一次工业革命的是蒸汽机,当它演进成为内燃机并开始普及时,第二次工业革命的颠覆者——电能本身以及与它相关的各种设备正处于初创期,而在电力设备走向微电子的迭代革新时,各种燃油引擎还在持续改良和普及中。
从这个规律来看,大语言模型(简称LLM)出现后虽然霸占了所有与AI相关的关键词,吸引了所有人的注意力,但这并不代表“LLM之前无AI”。
在大模型出尽风头的同时,此前以决策为特长的老一代机器学习应用,以及侧重感知能力的“传统”深度学习应用也没闲着,它们正走过喧嚣的青春期,步入稳扎稳打的实战阶段。

何以为证?
某芯片大厂就推出了一连串的AI实战手册,分别锁定制造与能源、医药、金融、交通与物流,以及教育行业的AI实践。
在今年更新的物流交通和医疗健康AI实战手册中,就记录了很多已经或正在落地的AI应用,及如何将它们顺利部署和充分释放其性能加速潜力,当然还有它们在一些耳熟能详的头部企业深入一线的应用实例。
所以,AI不是只有大模型。AI的大模型时代也 ≠ 只有大模型的AI时代。
成熟的AI,早就已经上岗了
或许你还不敢相信,现在哪怕小小的快递背后,都已经有AI技术在加持了。
没错,而且近乎涉足了物流全流程:下单、发货、分拣、转运、配送……AI现在统统都要“管一管”。
以经典的OCR(光学字符识别)技术为例,它在物流“技术界”的地位可谓是举足轻重,大幅提高了工作效率。
比如发货时的寄件人填报地址、身份信息,电商仓库核对出货的货品信息,都可以借助OCR,“啪地一下”,实现一键录入。
随着AI技术的愈发完善和应用的加深,这种速度做到了“没有最快只有更快”。

我们熟知的韵达快递就是如此,在三段码OCR识别过程中,它原本希望AI能将OCR识别的准确率达到95%。
结果现在的AI却给韵达“上了一课”,不仅准确率直接飙到接近98%,甚至时间也给“打了下去”:从130ms降至114ms。
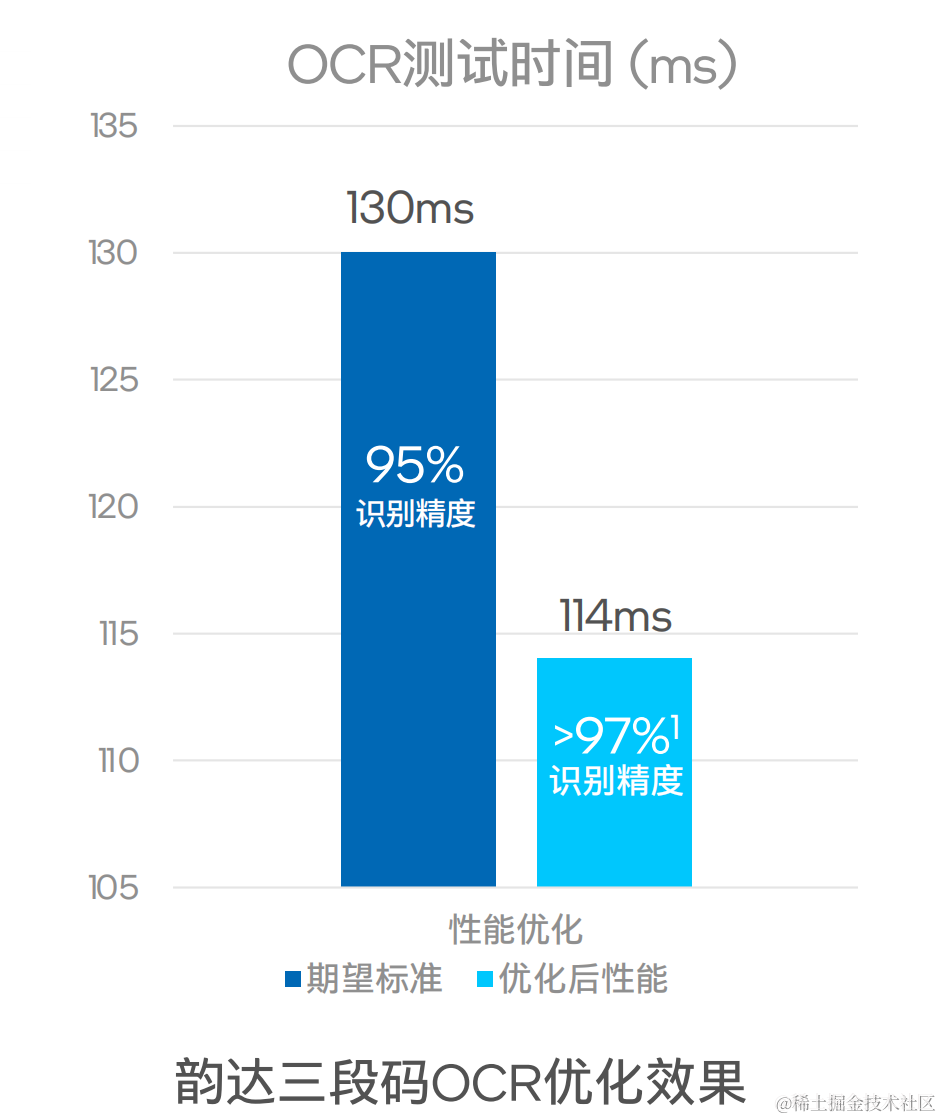
△性能测试结果基于韵达于2022年10月进行的测试
而且OCR识别还仅仅是AI涉足物流行业的小小一隅,一张图来看感受下它现在所起到的power:
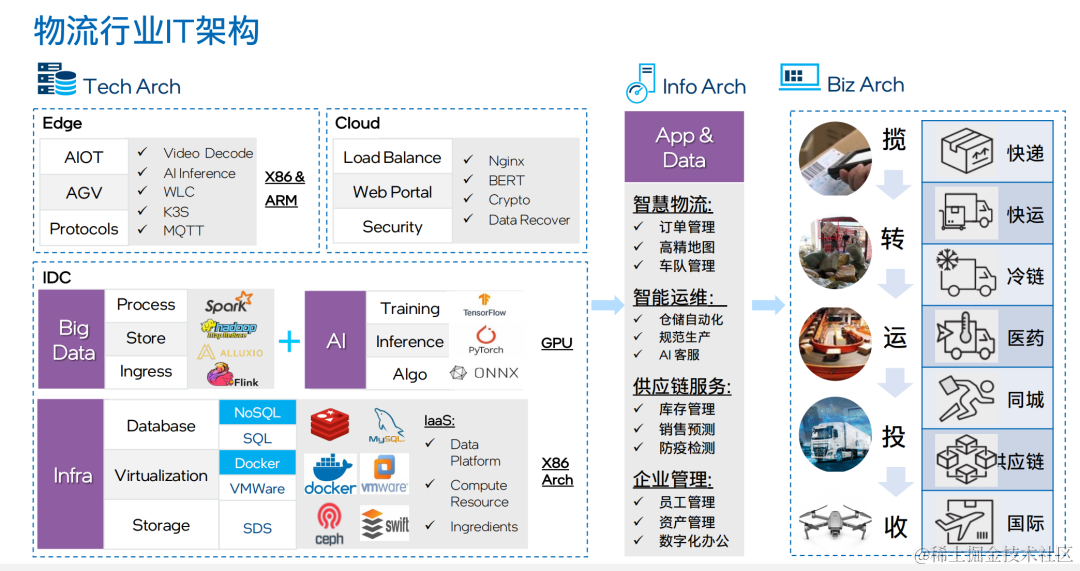
嗯,AI如此all in,怪不得国内物流的速度都要起飞了呢。
不过朋友,这还仅仅是AI加速千行百业的一个案例,其实我们现在每天的出行,同样也是充斥着AI的“味道”。
例如AI视频分析技术,可以针对高速公路上的路况做到实时地分析。
不论是车流流量监控、车辆车牌识别,亦或是事故预警等等,AI可谓是将一切尽收眼底。
如此一来,便可以有效且精准地对路面状况做到把控。
再如机场,在AI技术加持下的摄像头,也可以细粒度识别航空器、车辆、人员,以及违边等情况,这样便对飞行区域的安全提供了一定的保障。
……
从以上几个小小用例中不难看出,“成熟”的AI,或者说几年前那些当红明星类的AI应用看似风光不在,但它们实则已深入到我们生活中的方方面面,并且主打的就是一个“节支增效”。
那么如此“节支增效”背后,到底是怎么做到的?
不卖关子,直接上答案——
提供帮助的正是英特尔的平台,特别是至强®️ 可扩展处理器。同样,我们前文所指的某芯片大厂也是英特尔,给出多个行业AI实战手册的还是它。

但解锁如此能力的,可不仅仅是一颗CPU这么简单,而是有英特尔软件层面上的优化加成;换言之,就是 “软硬一体” 后的结果。
简单归结:至强®️ 可扩展处理器及其内置的AI加速器,以及OpenVINO™️ ,oneAPI等一系列AI框架和优化软件打辅助。
当前影响AI应用性能的要素无非两个:算力和数据访问速度。
目前最新的第四代至强®️ 可扩展处理器的单颗CPU核数已经增长到最高60核。而在数据访问速度上,各级缓存大小、内存通道数、内存访问速度等都有一定程度的优化,另外在CPU Max系列中还集成了HBM高带宽内存技术。
此外,在CPU指令集上也做了优化,内置了英特尔®️ 高级矩阵扩展(英特尔®️ AMX)等硬件加速器,负责矩阵计算,加速深度学习工作负载,堪称CPU加速AI应用的C位。
它有点类似于GPU里的张量核心(Tensor Core)。
AMX由两部分组成,一部分是1kb大小的2D寄存器文件,另一部分是TMUL模块,用来执行矩阵乘法指令。它可同时支持INT8和BF16数据类型,且BF16相较于FP32计算性能更优。
有了AMX指令集加持,性能比前一代至强®️ 可扩展处理器内置的矢量神经网络指令集VNNI提升达8倍,甚至更高。
除了核心硬件平台外,实际情况中帮助这些行业实战AI应用落地的,还有一系列英特尔“亲生”但不“私享”的AI软件工具。
例如前面提到的OCR加速就离不开OpenVINO™️ 的优化,它删减了很多训练部分所需的冗余计算,主要支持推理部分。
而且也是专门针对英特尔硬件打造的优化框架,只需5行代码就可以完成原有框架的替换。
用户可以针对不同业务场景,来优化OpenVINO™️ 运行参数。
这样一套软硬件组合拳打下来,英特尔不仅充分释放了CPU计算潜力,而且在实际的推理场景中也实现了近乎GPU的性能,同时还有成本低、门槛低、易上手等附加优势。
然而,这些仅仅是已经成熟上岗的AI技术在英特尔®️ 平台得到的优化,英特尔的能力还远不止如此。
这就要说回大模型了。
当红大模型,也在被加速
目前大语言模型正被全球各大科技公司竞相追逐,毕竟现在科技圈都将它视为未来发展的趋势所在。
虽然相比那些成熟的AI技术和应用,它距大规模落地还有段距离,但其技术领先性不容置疑,乃至“老一辈”的AI应用也有望在与它结合,或被它改造后重焕新生。
英特尔作为基础算力输出者和应用性能加速器,同样在这场你追我赶的竞技场中未雨绸缪,早有布局。
首先,大模型再先进,也需要有更多人用上它,才可充分变现其价值。要想“玩转”它,在其庞大的体量面前,成本便是一个老大难的问题。
因此,英特尔就祭出了一款增强型的“减(量)重(化)神(工)器(具)”,可以让一个十亿参数的大语言模型瘦身3/4,增强其准确性,还能有效地提升大模型在英特尔®️ 平台上的推理性能。

具体而言,所用到的是SmoothQuant技术,英特尔将其适配到自己的平台,并实现其增强。此方法已经整合至英特尔®️ Neural Compressor。这是一个包含量化、剪枝(稀疏性)、蒸馏(知识提炼)和神经架构搜索等多种常用模型压缩技术的开源Python库,它已经支持多款英特尔®️ 架构的硬件,并且已经兼容TensorFlow、PyTorch、ONNX Runtime 和MXNet等主流框架。
其次,在硬件层面上,英特尔也有所发力。
例如最近大火的ChatGLM-6B,其借助第四代至强®️ 可扩展处理器内置的英特尔®️ AMX,让模型微调计算速度得以大幅提升;利用至强®️ CPU Max系列处理器集成的HBM,满足大模型微调所需的大内存带宽。
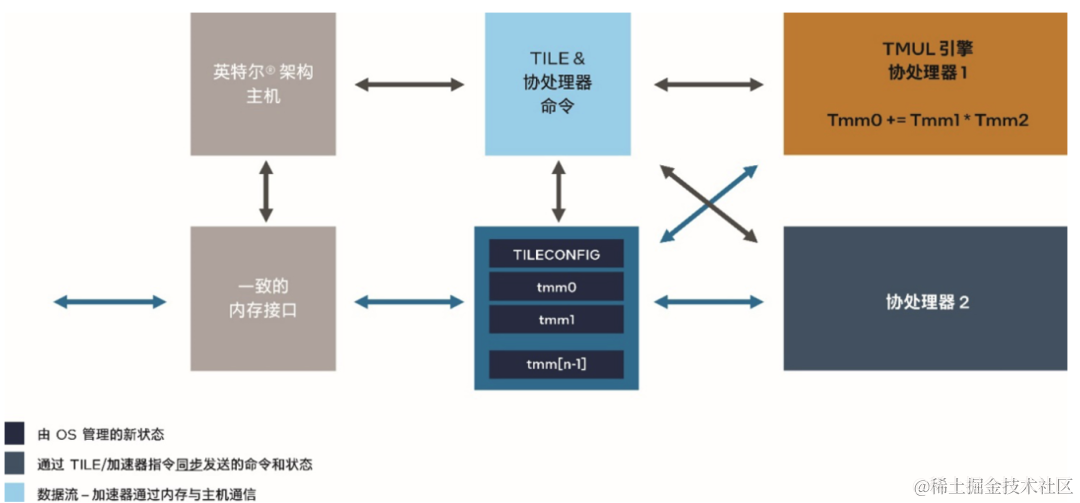
△英特尔® AMX 技术架构
除了CPU,英特尔还有专用的深度学习加速芯片Habana®️ Gaudi®️2 ,其能在单个服务器内部署8张加速卡(称为Habana处理单元,即Habana Processing Unit,简称为HPU),每张卡内存高达96 GB,可提供足够的空间来容纳大模型。
因此即使是BLOOMZ这样拥有1760亿参数的千亿级大语言模型,经英特尔优化后也能将性能时延控制在3.7秒。对于参数量为70亿的较小模型BLOOMZ-7B,在Gaudi®️2的单设备时延约为第一代Gaudi®️ 的37.21%;而当设备数量都增加为8后,这一百分比进一步下降至约24.33%。
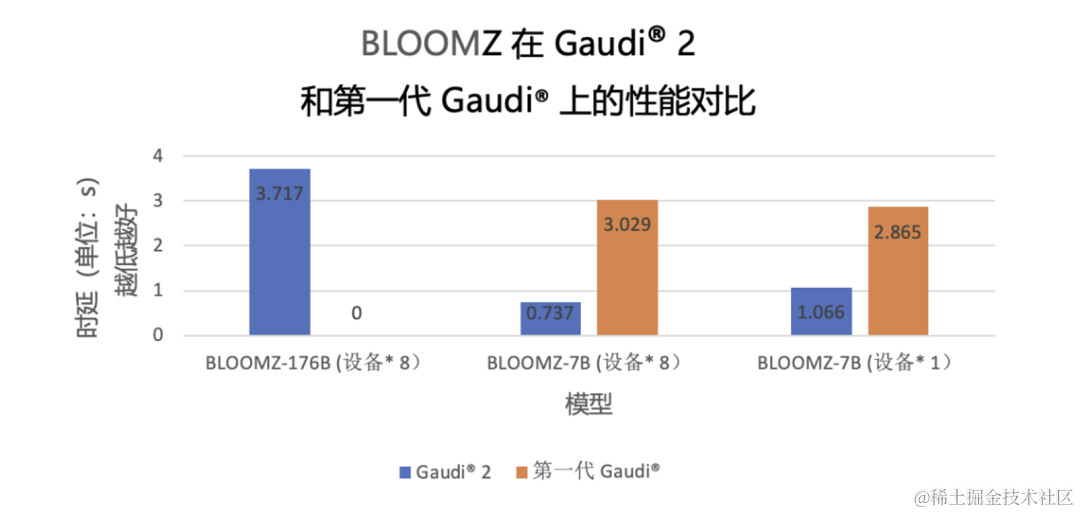
△BLOOMZ 在 Gaudi®️2 和第一代 Gaudi®️ 上的推理时延测试结果
而后在软件层面上,针对像ChatGLM这样大受欢迎的大语言模型,英特尔还可以通过为其创建 OpenVINO™ stateful模型来实现优化:压缩权重以降低内存带宽使用率,提升推理速度。
这便是英特尔“软硬一体”打法在大模型应用上的直接体现了。而且硬件还不再仅限于CPU,更是有可在训练和推理性能上都可与GPU比肩,在性价比上馋哭大家的Gaudi®️ 。
最后在安全方面,英特尔也是做到了“鱼与熊掌兼得”:基于英特尔®️ SGX/TDX的可信执行环境(TEE)可为大模型提供更安全的运行环境,还不需要拿性能做交换。
这便是英特尔在AI大模型时代中的“加速之道”了。
还会带来怎样的变革?
纵观AI技术的发展之路,不难发现英特尔在其中履行着一条非常清晰的准则——用起来才是硬道理。甚至只在数据中心和边缘中用都不够,最好每个人的每台电脑,每个信息终端设备都有独立加速AI应用的能力才能“芯”满意足。
因此英特尔已将创新使命调整为:在各种硬件产品中加入AI能力,并通过开放、多架构的软件解决方案,推动AI应用的普及,促进“芯经济”的崛起。
英特尔的“加速之道”不仅是让技术更快落地和普及,更是要以用促用,以用促新,以用促变,为下一世代的技术变革埋下伏笔。
如何系统的去学习AI大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的所有 ⚡️ 大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
全套 《LLM大模型入门+进阶学习资源包》↓↓↓ 获取~
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









