






Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。 举个例子,当有一个应用,需要在很大的图(graph)上进行Machine Learning的算法时,Spark会把整个图的数据存储在它的弹性分布式数据集(Resilient Distributed Dataset,RDD),如下图。Spark Client会存储需要运行的程序的各种数据, 并且把它map到对于集群(Cluster)的Spark-specific的指令上,而这个集群包括了许多的Workers。之后,Cluster Manager会把这些指令转变为任务,并在各个worker节点(node)上执行。每个集群需要让应用程序调度使其达到最大的利用率和性能的提升。
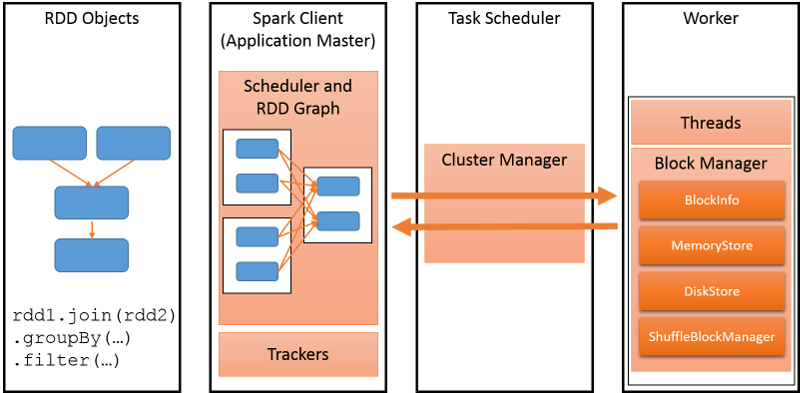
图 1
对于Spark来说,它最为重要的一部分就是它的弹性分布式数据集(RDD)。RDD是一个在大数据集上支持在内存间低容错运算的分布式存储抽象。程序员通过把能够在workers上复制并运行的闭包(函数)传递给workers,在RDD上调用各种指令。这部分会在博主之后的文章里作详细介绍。
程序员通过编写驱动(driver)程序来连接workers的集群,driver定义了一个或多个RDD,并且在RDD上调用各种actions。与此同时,driver会追踪每个RDD的“血统”(lineage),该“血统”以有向无环图(Directed Acyclic Graph,DAG)的形式,记录了整个RDD形成的过程。而之所以能够追踪到每一个RDD的“血统”,是因为workers的进程在整个应用程序运行的过程中一直保持存在,并且通过指令能够在RAM内存里存储所有的RDD分区(partition)。
图2是Spark的结构体系,SparkContext对象能够连接到不同类型的Cluster Manager,Cluster Manager负责对所有的应用和任务进行调配。Cluster Manager能够让各个Spark程序相互隔离,每个程序拥有自己的driver,并且运行在由Cluster Manager调配的相互隔离的executor上。目前,Spark能够支持由Java, Scala或Python所编写的应用程序。
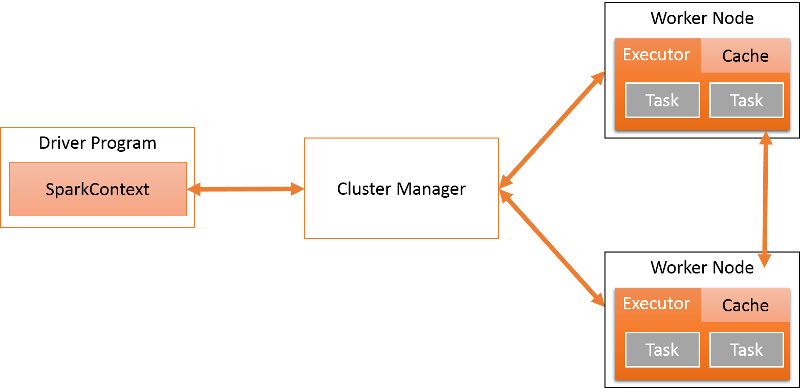
图 2
对于每一个在Spark上运行的程序,可以把它们看成是在相互隔离的集群上独立运行的进程集。Driver作为其中一个进程在应用程序中运行main()函数并且建造SparkContext。SparkContext协调Spark上的各个应用程序并且反过来连接负责在集群(cluster)上给所有应用程序分配资源的Cluster Manager。与此同时,SparkContext还包含了一些隐式转换(implicit conversions)和用于不同Spark特性的参数。
目前整个Spark系统支持三种Cluster Manager:
- Standalone
- Apache Mesos
- Hadoop YARN
一旦SparkContext连接上Cluster Manager,Spark便会在Worker Node上获取Executor, 并通过Executor进行计算和数据的存储。接着,Java/Scala/Python代码会被发送到Executor上运行并成为各种各样的tasks。因为每一个应用程序都拥有各自的Executor进程,这些进程能够在各个线程上执行各种tasks,所以Executor在应用程序的整个生命周期里都一直保持存在。
Spark采取上述方式的好处在于,应用程序之间能做到相互隔离,每个应用程序的driver在调度的决策上能够保持独立,不受其他应用程序的影响。不同应用程序里Executor的相互隔离,就像是每一个程序都运行在一个分离的JVM上。当然,这样做的话,如果要对应用程序之间进行数据分享,那就会变得十分困难。
正如上述所提到,Driver作为进程在应用程序中运行main()函数,它主要充当两个角色:
- 把user program转化为task:从宏观上看,Spark程序隐式地建造了一个指令的有向无环图(DAG),而Driver把这个转化为实际的物理层面上的运行计划。在这期间,各种各样的优化一直发生,把命令执行图转变成一些列状态,每个状态都包含了各种各样的任务。
- 在Executor上调配task:一旦这个物理层面上的执行计划建立起来后,driver能够调配Executor上的每一个task,从而在所有的Executor上起到了一个宏观调控的作用。
Executors作为worker进程一旦被建立起来,直到整个应用程序结束它们才会停止运行。总的来说就是Driver调配Executors,Executor运行各个task并返回结果。每个Executor还包含一个BlockManager,它以内存存储的形式来给RDD提供缓存。
当然,Spark的核心依然是RDD的执行和存储。本人将在下一篇文章作更为详细的讲解。















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









