







先看个例子
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedHashMap;
import java.util.LinkedHashSet;
import java.util.LinkedList;
import java.util.Map;
import java.util.TreeMap;
import java.util.TreeSet;
public class Test {
public static Collection fill(Collection<String> collection){
collection.add("aa");
collection.add("cc");
collection.add("bb");
collection.add("cc");
return collection;
}
public static Map fill(Map<String,String> map){
map.put("aa", "aly");
map.put("cc", "aly");
map.put("bb", "aly");
map.put("cc", "aly");
return map;
}
public static void main(String[] args){
System.out.println( fill(new ArrayList<String>()) );
System.out.println( fill(new LinkedList<String>()) );
System.out.println( fill(new HashSet<String>()) );
System.out.println( fill(new LinkedHashSet<String>()) );
System.out.println( fill(new TreeSet<String>()) );
System.out.println( fill(new HashMap<String,String>()) );
System.out.println( fill(new LinkedHashMap<String,String>()) );
System.out.println( fill(new TreeMap<String,String>()) );
}
}
执行之后console显示:
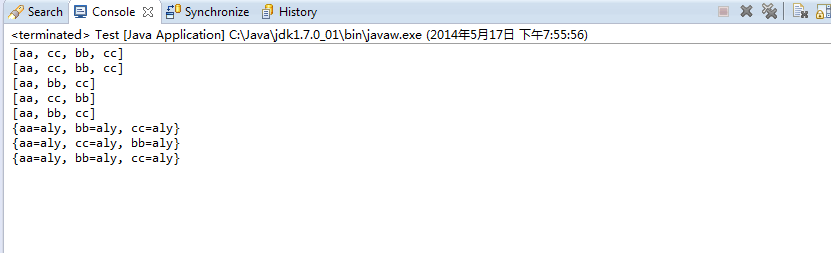
List:分ArrayList和LinkedList,
ArrayList就像一个数组,你可以使用get(0)来访问第一个元素,它存储的顺序与你放入的顺序相同。
LinkedList是用链表来实现的,它也不会改变元素放入时的顺序。
所以从上面实验的结果,是一样的
Set:分HashSet,LinkedHashSet,TreeSet。Set的一个共同点是重复的元素只存储一个。
HashSet采用了Hash算法来计算存储位置,所以它的速度是最快的。
LinkedHashSet是链表结构,所以元素的位置跟插入的时候一样,同时保留了HashSet的查询速度。
TreeSet是按结果集的升序来保存对象。
Map:分HashMap,LinkedHashMap,TreeMap。Map是存储的键值对。跟对应的Set的效果差不多。















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









