







我目前这个博客主要讲的是从0基础开始学python,到熟练写python,主要讲的是如下一些:
首先安装建项目就不需要我来告诉你们了把,你们就自己去找一下其他的博主就🆗了,还有语法之类的,你们就自己去找资源,很简单的。
(1)爬虫
(2)使用flask框架搭建项目,写一些简单的api接口(个人习惯用flask框架,你们也可以用其他框架)
(3)跨域(让外界进行访问接口,比如ajax请求)
(4)jinJa2模板引擎(通俗的说是在pycharm里面写html网页)
如果是想要知道以上知识的同学就往下看,如果没有有需要的就别往下看了,因为里面没有你们想要的东西,还会浪费你们的宝贵时间。
重要的说三遍!!!重要的说三遍!!!重要的说三遍!!!
对于python的个人简介:
前言:对于python我是通过爬虫才对python感兴趣的,我自己擅长的开发是.NET开发,不过学过.net的应该都知道,用.net写爬虫个人认为(说的有错请见谅)太麻烦,并且不容易上手,python的话很容易上手,并且代码简洁。接下来就奥里给吧!!!
(1)爬虫部分
1、首先爬虫要做的部分就是先安装库。必须的库有requests(请求网页的库)和解析网页的库,这个不是唯一的,解析网页有很多种,比如re(正则表达式解析)、BeatufiulSoup、html.parser与lxml,这些都是解析网页的库,我这里推荐用lxml,这个的话好用,方便,容易上手,那么安装库有两种方法:
第一种、通过在控制台输入命令:
pip install (库名)
第二种、手动安装,详细看图
在这里插入图片描述



按照上面步骤安装lxml库,就是接下来上代码:
import requests //请求网页的
header={ //这里定义的header变量是用来防止你去请求这个网址的时候被拦截,是 一种向访问网站提供你所使用的浏览器类型、
//操作系统及版本、CPU 类型、浏览器渲染引擎、浏览器语言、浏览器插件等信息的标识。如果你不定义的话,别人就会知道你用的是爬虫去请求的,
//就不会让你访问,这个在哪里可以看呢?请看下图(其实这个不一定要,就是有些网站有这个需要,正常情况下不需要),如果打印不出内容,
//建议加上
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.78',
}
respons = requests.get("https://weather.cma.cn/web/weather/57679.html",headers=header) //反扒机制
respons.encoding="utf-8" //指定中文编码格式,防止乱码
html = respons.text //返回网页源代码
print(html) //打印源代码
找到user-agent:左边随便点进去一个,

接下来这时上面代码打印在控制台的结果:

这时控制台就会输出这些内容,说明你成功访问到了,但是要访问到里面的内容你应该去解析,解析内容看如下:
import requests
from lxml import etree
header={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.78',
}
respons = requests.get("https://weather.cma.cn/web/weather/57679.html",headers=header) #反扒机制
respons.encoding="utf-8"
html = respons.text
tree = etree.HTML(html)//etree.HTML()可以用来解析字符串格式的HTML文档对象,
//将传进去的字符串转变成_Element对象。作为_Element对象,
//可以方便的使用getparent()、remove()、xpath()等方法。
print(tree)
如果你打印这个东西的话,不要紧张,正常现象。就是这样的
接下来我们来讲真正的如何解析,一般我们解析的话,会在谷歌浏览器中安装一个xpath-helper扩展工具,这个你们可以在谷歌浏览器里面更多工具中的扩展工具中去下载。

这个具体在哪里下,那里安装你们可以自行百度,我这边只告诉你们怎么用,这个真的非常好用。接下来我将演示怎么用。
首先打开代码中请求的网址,它是一个中国气象局天气预报,我们打开网址,按住ctrl+shift+X,就会弹出这么一个东西:

这个时候我们可以按住shift用鼠标悬浮在你想要爬取的网页具体位置:我現在按住shift鼠标悬浮在湖南这个字上,然后上面就会出现
路径和值,这个路径我们一会要用来解析的路径,现在我们获取这个位置的所有省份。

现在我们打开下拉框,用按住shift,吧鼠标放到上面:

上面左边的路径太长,并且只显示一个省份地区的,我们要获取所有怎么办的,这个你得再这个路径上面进行试:具体怎么试呢,你得看源代码,获取公共部分,这个你可以慢慢去掌握,这个一下子说不清楚。我这边直接在左边的框框中进行删改,然后得到所有的省份地区路径。

左边的路径经过我的删减和修改已经可以获得所有省份了,这个时候我们复制左边的路径进入到python中去进行解析获取打印。
import requests
from lxml import etree
header={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.78',
}
respons = requests.get("https://weather.cma.cn/web/weather/57679.html",headers=header) #反扒机制
respons.encoding="utf-8"
html = respons.text
tree = etree.HTML(html)
//加上这句代码进行解析,记住后面加上/text()转文字
resp = tree.xpath("//ul[@class='dropdown-menu province-select']/li/text()")
print(resp)

这样就爬取到了你想要的数据了,如果你想要其他的数据也是可以爬取的,接下来的爬虫之路就靠你自己了。你们可以运用爬虫爬取网站上的图片,视频都是可以的,不过这些你们可以百度,
(2)使用flask框架搭建项目,写一些简单的api接口部分
我们就用上面的爬虫爬到的数据作为接口返回值吧,这样能够连贯起来。写接口之前我们要安装flask库,可以参照之前的步骤,进行安装。
import requests
from lxml import etree
from flask import Flask #导入flask
app = Flask(__name__) #实例化flask对象
@app.route("/s",methods=["get","post"]) #配置路由 “/s”代表是你的路径,这个可以自己设置,但是要以/开头,基本上都是/加
#函数名
def datainfo():
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.78',
}
respons = requests.get("https://weather.cma.cn/web/weather/57679.html", headers=header) # 反扒机制
respons.encoding = "utf-8"
html = respons.text
tree = etree.HTML(html)
resp = tree.xpath("//ul[@class='dropdown-menu province-select']/li/text()")
info = {"listinfo":resp} #转为json字符串,listinfo是名字,可以自己随便取
eturn json.dumps(info,ensure_ascii=False) #转为json对象
if __name__ == "__main__": #执行函数,相当于main()函数
app.run(host="127.0.0.1") #host="127.0.0.1" 本地 host=“0.0.0.0” 任何主机都可以访问,只要知道AP
这个时候你执行就会出现如下界面,点击蓝色链接就会出现下面的界面就说明你成功了


好了这是基本一个接口的写法,但是还不能通过ajax去调用,如果你强制去调用的话就会出现跨域的问题,那么接下来我们将解决一下跨域的问题!
(3)跨域(让外界进行访问接口,比如ajax请求)
跨域是指:浏览器A从服务器B获取的静态资源,包括Html、Css、Js,然后在Js中通过Ajax访问C服务器的静态资源或请求。即:浏览器A从B服务器拿的资源,资源中想访问服务器C的资源。那么接口的访问也是很简单的,就是需要安装CORS包,这个是专门用来跨域用的,详细代码如下:
这边跟你讲解一下**
CORS(app,resource=r’/*’)
**的意思。这个很重要!!!你们可以参考这篇博客,这篇博客讲的很详细
https://www.cnblogs.com/anxminise/p/9814326.html
import json
import requests
from lxml import etree
from flask import Flask
from flask_cors import CORS #跨域问题
app = Flask(__name__)
CORS(app,resource=r'/*')
@app.route("/datainfo",methods=["get","post"])
def datainfo():
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.78',
}
respons = requests.get("https://weather.cma.cn/web/weather/57679.html", headers=header) # 反扒机制
respons.encoding = "utf-8"
html = respons.text
tree = etree.HTML(html)
resp = tree.xpath("//ul[@class='dropdown-menu province-select']/li/text()")
info = {"listinfo":resp}
print(resp)
return json.dumps(info,ensure_ascii=False)
if __name__ == "__main__":
app.run(host="127.0.0.1") #host="127.0.0.1" 本地 host=“0.0.0.0” 任何主机都可以访问,只要知道AP
这个时候你们就可以用ajax进行接口的访问,我这里简单的进行一下访问输出:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="js/jquery-3.4.1.js"></script>
</head>
<body>
<div id="content">
</div>
<script>
$.ajax({
url:"http://127.0.0.1:5000/datainfo",
type:"get",
dataType:"json",
success:function(data){
var str = JSON.stringify(data); //object类型转为json字符串
var str1 = JSON.parse(str); //json字符串转为json对象
console.log(data)
$("#content").text(str1.listinfo);
}
})
</script>
</body>
</html>

看,这就请求到了这个数据,很简单了!
(4)jinJa2模板引擎(通俗的说是在pycharm里面写html网页)
Flask使用jinja2作为框架的模板系统,是有着强大的自动HTML转义系统。接下来我们将粗略讲解一下他的用法:
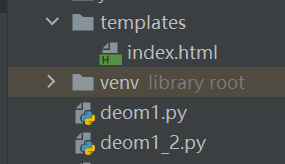
这个我们还是用上面所爬取到的数据进行一个页面渲染。首先我们新建一个templates文件夹,在templates文件夹里面新建一个html网页,记住templates文件夹的位置要和.py后缀的文件在同一级
就像这种,你只要把他们的位置关系放到同一级就好,外面套多少层文件夹都无所谓
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
//这里用到for循环去展示我们的数据,content是返回数据中的一个变量名,
<ul>
{% for i in content %}
<li>
{{i}}
</li>
{% endfor %} //结束for循环
</ul>
</body>
</html>
import requests
from lxml import etree
from flask import Flask,render_template #这里引入了render_template库
app = Flask(__name__)
@app.route("/datainfo",methods=["get","post"])
def datainfo():
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.78',
}
respons = requests.get("https://weather.cma.cn/web/weather/57679.html", headers=header) # 反扒机制
respons.encoding = "utf-8"
html = respons.text
tree = etree.HTML(html)
resp = tree.xpath("//ul[@class='dropdown-menu province-select']/li/text()") #这里返回的是一个数组
return render_template("index.html", content=resp) #引用index.html这个文件,content是变量名,自己取,resp是数据
if __name__ == "__main__":
app.run(host="127.0.0.1") #host="127.0.0.1" 本地 host=“0.0.0.0” 任何主机都可以访问,只要知道AP
然后我们直接运行这个.py文件,下面会出来一个链接,然后我们点进去,不过地址要输入对,地址主要跟你自己定义的路由有关系,
我这里定义的路由地址是 /datainfo 那么我一会运行地址的时候我手动加上,看结果:


ok这就是对jinja2模板引擎的简单运用。
那么我们的知识点讲到这里也该收尾了,感谢大家能够阅读到这里,希望得到大家的一个关注!有什么不好的地方希望大家指出来。















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









