







文章目录
前言
这篇文章的主要内容是我对软件构造课程-数据类型与类型检验部分的学习总结,以供未来使用。
内容主要包括
- 基本数据类型和对象数据类型
- 类型与引用的可变与不可变性
- 静态与动态类型检验、
- 快照图
- 集合框架的迭代器等。
文中所出现的表格以及图片均来自课程教师的讲义。
一、Java中的两大数据类型
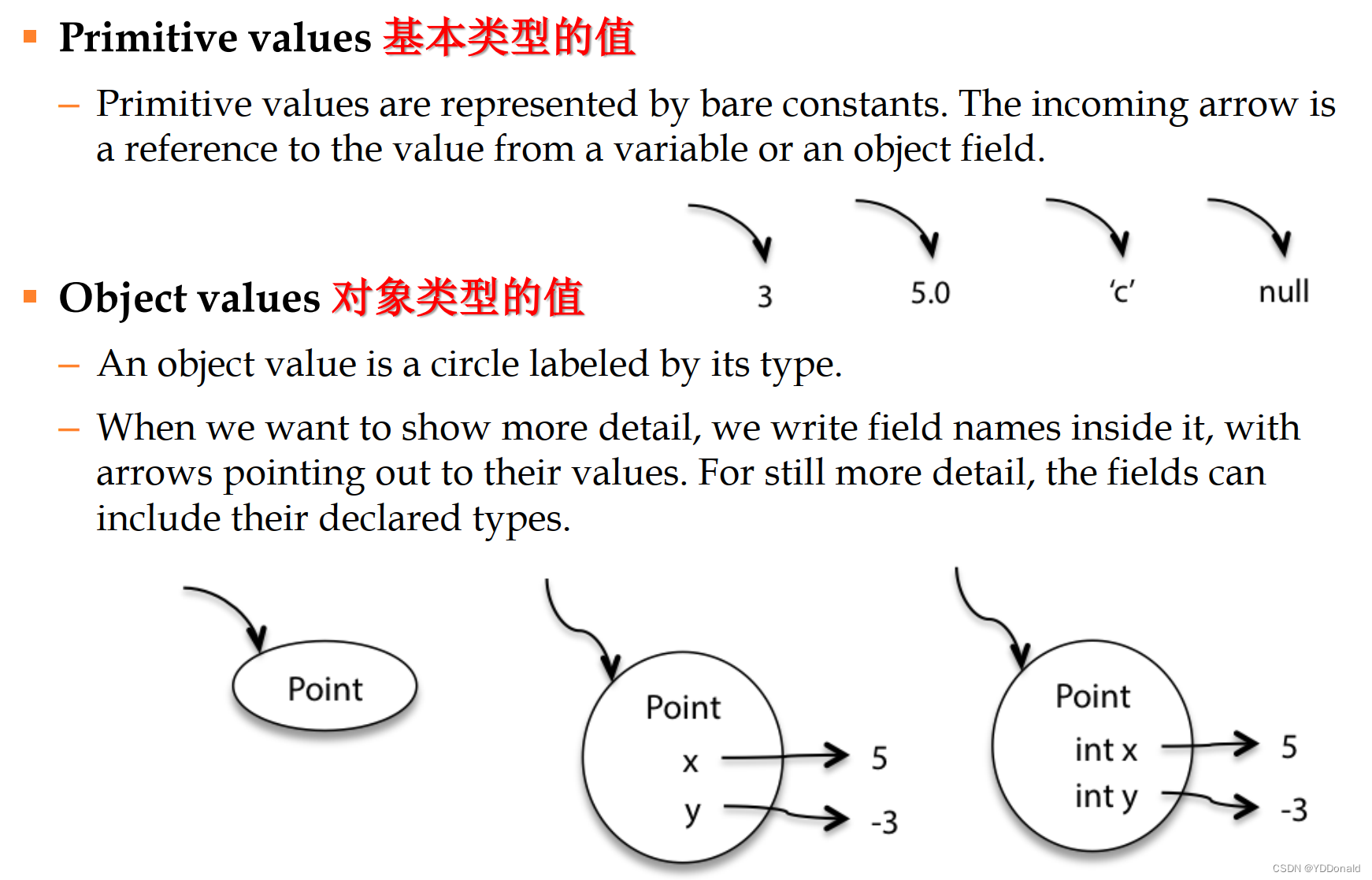
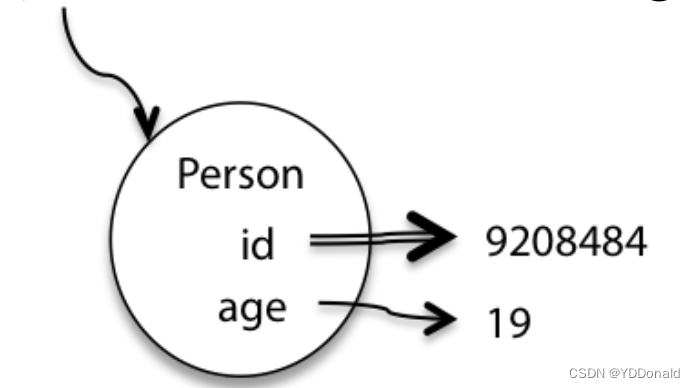
java语言包含两种数据类型:基本数据类型(primitive types)和对象数据类型 (object types)。二者区别如图所示:

底层实现
从底层实现来讲,二者的区别就在于引用类型不同。
举个具体的例子,详细说明变量赋值的过程:
int x = 5;
x = 10;
Object y = new Object();
在上面代码中,x是基本数据类型,而y是对象数据类型。
- 执行int x = 5;Java会在栈内存中分配一段存储空间来存储值’5’,然后将变量x指向这一段空间。也就是说x就代表着栈内存的一段空间,而这段内存空间是直接存储着int型的值’5’的。
- 当执行x=10时,x的值从5被修改到10。此时Java会为新的值’10’在栈内存中分配一段新的内存空间,并将x更新为这段内存空间。也就是说x=10并非在x原有的内存空间下直接修改,而是分配一段新的内存空间再更新x。
- 在执行Object y = new Object();时,Java同样的也会在栈内存中开辟出一段内存空间,将变量y指向它。但不同于x,该内存空间并不直接存储数据,而是存储对象y中数据的实际存储地址——堆内存中的地址。Java会在堆内存中分配一段内存以容纳对象y的数据,而这段内存的地址则被存储在栈内存中。
总的来说,基本数据类型和对象数据类型的变量均代表在栈内存中的一段存储空间,但不同的是,基本数据类型变量的对应空间直接存储数据,而对象数据类型变量的对应空间则存储其在堆内存中的地址,而在堆内存中存储数据。这就导致了二者的引用类型不同。
那么为何要将对象数据类型存储在堆内存中呢,主要有两大原因:
- 灵活性:堆内存允许动态分配和释放内存空间,这使得可以根据需要动态地创建和销毁对象。
- 对象的生存期不确定性:在Java中,对象的生命周期通常是不确定的,它们可能在任何时候被创建和销毁。如果对象在栈内存中分配,它们的生命周期将受到方法调用的限制,这可能会导致内存管理的困难和效率问题。堆内存中的对象不会随着方法调用的结束而被销毁,而是直到没有引用指向它们时才会被垃圾回收器回收。
联系之处
显然,对象数据类型是可以包含多个基本数据类型的,就比如实例变量。但基本数据类型的实例变量并非存储在栈内存中,而是存储在其对象的堆内存中。
Java还提供了名为包装类的对象数据类型,将相应的基本数据类型包装为对象,比如int -> Integer,double -> Double。包装类自身携带着许多功能,如解析、比较、转换等。包装类也可提供泛型支持,最常用的就是在集合类(如 ArrayList、HashMap 等)中存储基本数据类型的值,因为泛型只能使用对象数据类型。
二、静态vs动态类型检验
有了数据类型,有了值,那么很重要的工作就是验证“型”与“值”的匹配性——类型检验。
举个例子:
double a = 2;
int b = (int)2.2;
double c = 2/3;
double d = (double)2/3;
上面的代码就是“型”与“值”不匹配的情况。
- double a = 2; 由于2是整型,会发生自动类型转换,将其转换为double。
- int b = (int)2.2;2.2是小数,但前加(int)会强制进行转换,舍弃掉小数部分得到2.
- 2/3是整数运算,得到的结果是0(忽略余数),但如果要得到精确的结果,就要使用(double)进行转换,或者可以使用2.0/3以进行浮点数运算。
如果没有这样的类型检查,程序很容易出错。
定义
Java是一门静态类型语言(statically-typed language)。与之相对的,比如Python就是一种动态类型语言(dynamically-typed language)。Java的变量类型必须在编译时确定,且不可随意改变。而Python的变量类型在运行时确定,且可以进行更改。
但实际使用过程中,二者均可以结合静态类型检查和动态类型检查两种方法来确保程序的类型安全性。
静态类型检查(static data type checking):
- 在编译时进行。
- 由编译器检查类型声明与类型使用是否匹配。
- 若发现类型错误,编译器会报错,并终止编译,直到修复。
其使用场景包括:

动态类型检查(dynamic data type checking):
- 在程序运行时进行。
- 在执行程序的过程中,当涉及到类型转换、方法调用等操作时,会动态地检查变量和表达式的类型是否匹配。
- 如果类型不匹配,程序可能会抛出类型异常或者执行相应的类型转换操作。
其使用场景包括:

二者区别
总的来说,静态类型检查与动态类型检查的最大区别就是检查的值在编译阶段确定还是在运行阶段确定。静态类型检查更倾向于表面上的型值对应关系,即某个变量应该具有哪种类型的值,这是在编译阶段即可确定的,但它对具体是什么值,是否会有特殊值引起错误并不关心。而动态类型检查更倾向于某些特殊值而引发的错误,比如下标越界,空指针等等,这一般在运行阶段被确定。
这两种类型检查各有优势,但对于程序的正确性与健壮性来说,静态类型检查要优于动态类型检查。因为程序的bug总是越早发现越早解决越好,静态类型检查可以在编译时发现错误并修正,避免了将错误代入运行阶段。
三、可变性与不可变性
正如第一部分所分析的那样,赋值的本质就是开辟一段内存空间写入特定值,然后将内存空间与变量(引用)关联到一起。而赋值操作与可变性(mutability)和不变性(immutability)紧密关联,它们影响着赋值操作的是否可行、具体实现以及安全性能问题。
类型不可变性 与 引用不可变性
可变性与不可变性体现在两大方面:类型方面与引用方面。
类型不可变性:就是指一旦一段内存空间被写入了值,那么这个值是不可被改变的。
所有的基本数据类型都是不可变的。也就是说如果要对基本数据类型进行重新赋值,那么就必须开辟新的内存空间写入新值,并重新与变量关联。
引用不可变性:就是指变量一旦被确定了其指向的内存空间,那么指向关系就不可改变。
Java中最常见的实现方式是使用关键字final。如果编译器无法确保final修饰的变量后续没有改变,那么就会报错,这属于静态类型检查。
举个例子
final int x = 5;
final MyObject y = new MyObject();
对照第一部分的分析,
- final int x = 5; 这句代码声明了x变量是final的,也就是引用不可变。此时x指向栈内存中的一段区域,且x只能指向这一区域。如果后续使用x = 10;由于x是基本数据类型(不可变类型),需要在栈内存中开辟新的内存空间重新关联,但由于x的指向关系不能改变,故会发生报错。
- final MyObject y = new MyObject();这句代码声明了y变量同样具有引用不可变性,此时y同样指向栈内存的一段区域,该区域存储的是对象数据实际存储地址(在堆内存中),且该地址是不可修改的。如果后续执行y = new MyObject(),则需要将该地址修改为新的对象的地址,但由于final的作用,指向关系无法改变,所以也会发生报错。
由于MyObject是对象数据类型,可以设计为可变的类型,所以即使其使用final关键字限定了引用不变性,但这仅仅代表其栈内存存储的地址不可改变,而在堆内存中存储的对象的实际数据是可以修改的,也就是可以进行删除、修改、添加元素等等操作。这也是引用不变性与类型不变性的重要区别。
更深入的理解
对于基本数据类型(均为不可变类型)而言,由于其指向的栈内存直接存储数据的值,不可对栈内存直接修改,所以赋值操作只能重新开辟一段新的栈内存写入新的值,再更新变量与内存的指向关系。假如又对该变量使用final修饰,那么指向关系又不可改变,所以该变量只能指向一段特定的不可修改的栈内存区域,这样就会导致该变量的值无法被改变。
对于对象数据类型而言,其既可以是不可变类型也可以是可变类型(取决于实现方法)。如果是可变类型,那么就可以对其在堆内存中的数据进行修改、删除、添加等操作。但如果其引用是不可变的,那么就意味着变量在栈内存中存储的堆内存地址无法改变,该变量就不能指向其他的同类型对象,只能指向该对象,但该对象的值仍然可以在堆内存中被修改。如果该对象被设计为不可变类型,那么该对象在堆内存中的值就无法被修改了。此时若引用可变,那么可以对变量赋值到另一个同类型的变量。若引用不可变,那么变量只能指向该对象,而该对象的值无法被修改。
总之,类型不变性和引用不变性是相互独立,互不影响的。
可变类型与不可变类型
简单来讲,二者的区别就是是否可以对值进行修改。
但从性能、安全性上来讲,二者具有很大的不同。
对不可变类型的“修改”操作
一个简单的问题:
- 如何对不可变类型实现“修改”操作?
首先要明确,在程序中我们修改一个类型的值,一般要借用变量名来实现。而变量(引用)总是指向一段内存(值或地址)。不可变类型意味着该类型的值无法改变,但是却可以利用引用的可变性来隐式地实现修改操作。也就是说,对于不可变类型的“修改”,并非是在其值上直接修改,而是先开辟一段新的内存空间,将原有的值拷贝于此,再在这段新的空间上进行修改,完成后再与变量(引用)关联起来。这个过程中变量指向的内存地址发生的变化。
举个例子:
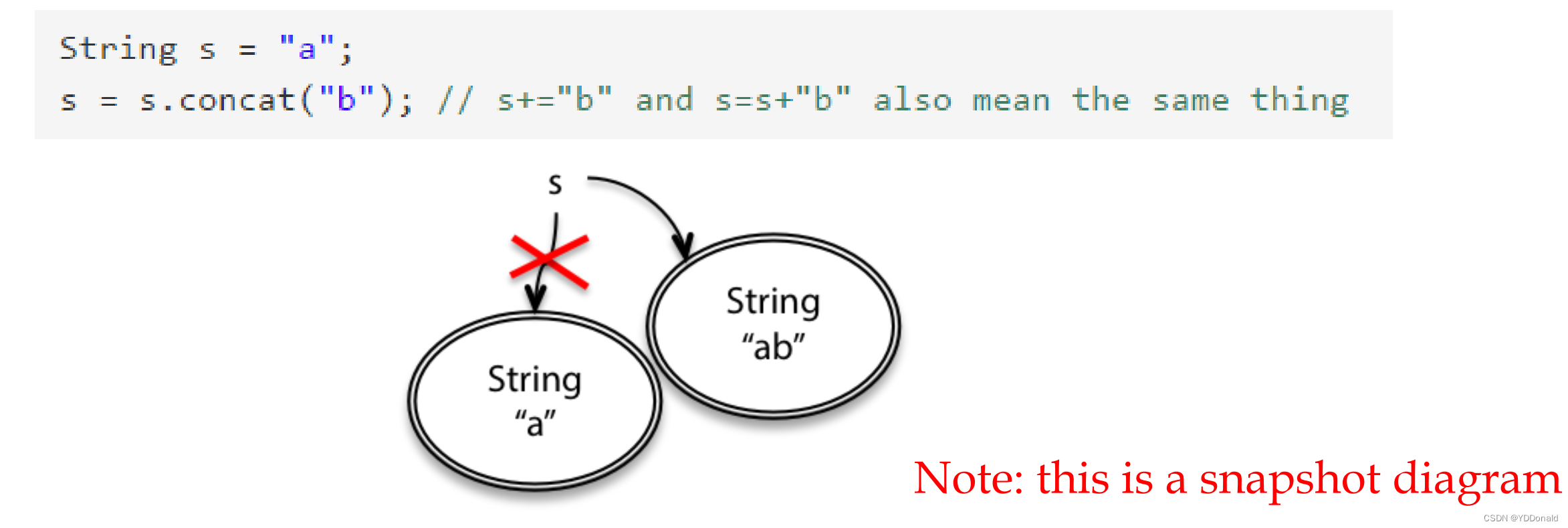
String是不可变类型。调用.concat()方法在原有字符串后面加上新的字符串时,看似是在原有的字符串上添加,实则是在新开辟的内存空间上进行操作。
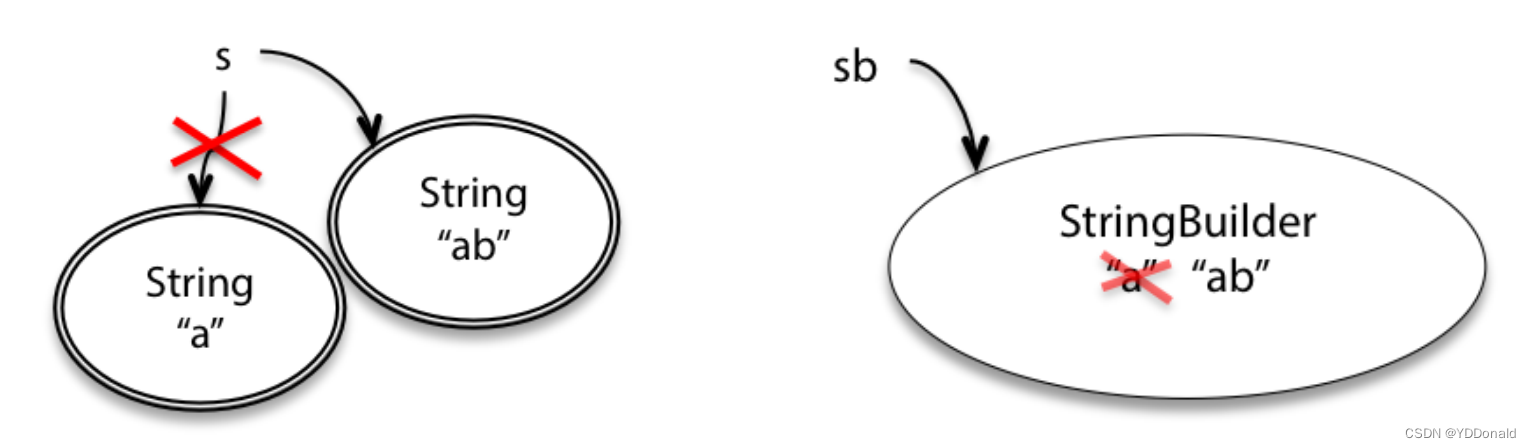
当然,如果使用可变类型的StringBuilder,情况就会完全不同:直接在原内存空间上进行修改

这两个操作的结果是相同的,最终都会使变量指向一个存储着"ab"的内存空间。
但是,如果存在着多个变量,可变与不可变类型的差异就非常明显:

这里使用t=s以及tb=sb,使得t与s,tb与sb指向相同的内存空间。这种变量=变量的形式,对于可变和不可变类型来说结果都是一样的,并不会发生拷贝。
但如果对t和tb进行修改操作:
由于t指向不可变类型,所以必须先进行拷贝再修改。结果是s和t 指向不同的内存空间,s中存储着原始数据,而t中存储着修改后的数据。
由于tb指向可变类型,所以可以直接在内存空间上修改值。结果是sb和tb 均指向存储着修改后的数据的内存空间。
很容易看出,这样就会发生问题:比如我们在程序编写的过程中使用了可变数据类型StringBuilder,并只对tb变量的值进行修改。我们很可能想当然的认为sb仍然指向着原始的数据,但实际情况是sb指向的内存空间已经被另一个变量糟糕的修改掉了。但如果使用不可变的数据类型,那么可以保证各个变量之间的独立性,却又使得频繁的修改操作产生大量的临时拷贝,需要垃圾回收机制及时回收,同时又对程序的性能产生了较大的影响。
二者各自的优势与不足
由此可见,可变类型与不可变类型实际上各有优劣,在编写代码的过程中需要程序员自己采取折中的方案综合考虑来进行选择。
可变类型的优势:
- 具有更好的性能
- 适合多个模块之间共享数据
- 更灵活,可动态修改
不可变类型的优势:
- 更加安全
- 适合需要缓存的情况
- 变量之间独立性高,不易出错
安全性的考量:使用不可变类型
但实际应用过程中,我们还是尽量使用不可变类型。因为使用可变类型往往会发生难以察觉的错误。相比于性能,还是程序的安全性和正确性更加重要。
举例:
方法对接收的参数变量进行修改

sumAbsolute()函数非常糟糕的修改了参数变量list的值,导致后序的sum()函数计算结果出错。
返回可变类型的结果

这个错误比较难以察觉。注意到startOfSpring()返回了可变类型Date的变量groundhogAnswer。该变量是类的实例变量,如果为空的话则需要调用askGroundhog()来计算今年春天的第一天对groundhogAnswer进行赋值。调用partyPlanning()方法,想要获取聚会举办的时间——春天开始后的一个月。使用partyDate变量获取这个日期然后再修改月份为+1。
逻辑上没有任何问题,但是由于Date是可变类型,对partyDate的修改会导致groundhogAnswer一并修改(因为二者指向同一内存空间)。而作为实例变量的groundhogAnswer会想当然的被认为依然存储着“春天的第一天”这一结果,但实际上已经被错误的修改掉了。
这就是可变类型的不正确使用给程序带来的巨大风险。
防御式拷贝
从上面的例子中我们可以看出,正是可变类型的不当使用导致了错误的产生。如果使用不可变类型那么上面的错误很自然的就会被避免。但假如我们在某些情况下(比如出于性能、灵活性、方便的考量)不得不使用可变类型,其实上面的错误也是可以通过一种手段避免的。这种手段就叫做防御式拷贝。
防御式拷贝(Defensive Copying)是一种编程技术,用于确保不可变性和安全性。它通常用于处理可变对象的参数或返回值,以防止外部对象对内部对象的状态产生不良影响。
在防御式拷贝中,当需要将一个可变对象传递给方法的参数或者返回给调用者时,首先创建该可变对象的一个副本(拷贝),然后将副本传递给方法或返回给调用者。这样做可以确保原始对象的状态不会被修改,从而保护程序的安全性。
虽然这种方法跟不可变类型一样,可能会造成内存的浪费,但在需要保证程序安全性和正确性的情况下,防御式拷贝是一种非常有用的技术。但既然如此,使用不可变类型显然更加方便,因为它不需要显式地进行各种拷贝操作。
举例:
上面的第二个例子,我们只需要将startOfSpring()方法的返回值修改为:
return new Date(groundhogAnswer.getTime());
通过创建可变对象的副本(使用new实现,即接收原对象的所有信息构造新的对象)即可避免错误的出现。
四、快照图
快照图(snapshot diagram)是指软件系统或系统的某个部分在特定时间点的结构图或状态图。其通常用于描述程序运行过程中的内部状态——栈内存以及堆内存。
快照图提供了一个清晰直观的表示,便于刻画各变量随时间的变化。
- 基本类型和对象类型
- 不可变类型(双线椭圆)和可变类型(单线椭圆)
- 不可变的引用(双线箭头)和可变的引用(单线箭头)
使用快照图可以很方便的表示出各个变量的变化,尤其是有较多的可变与不可变类型的变量时:
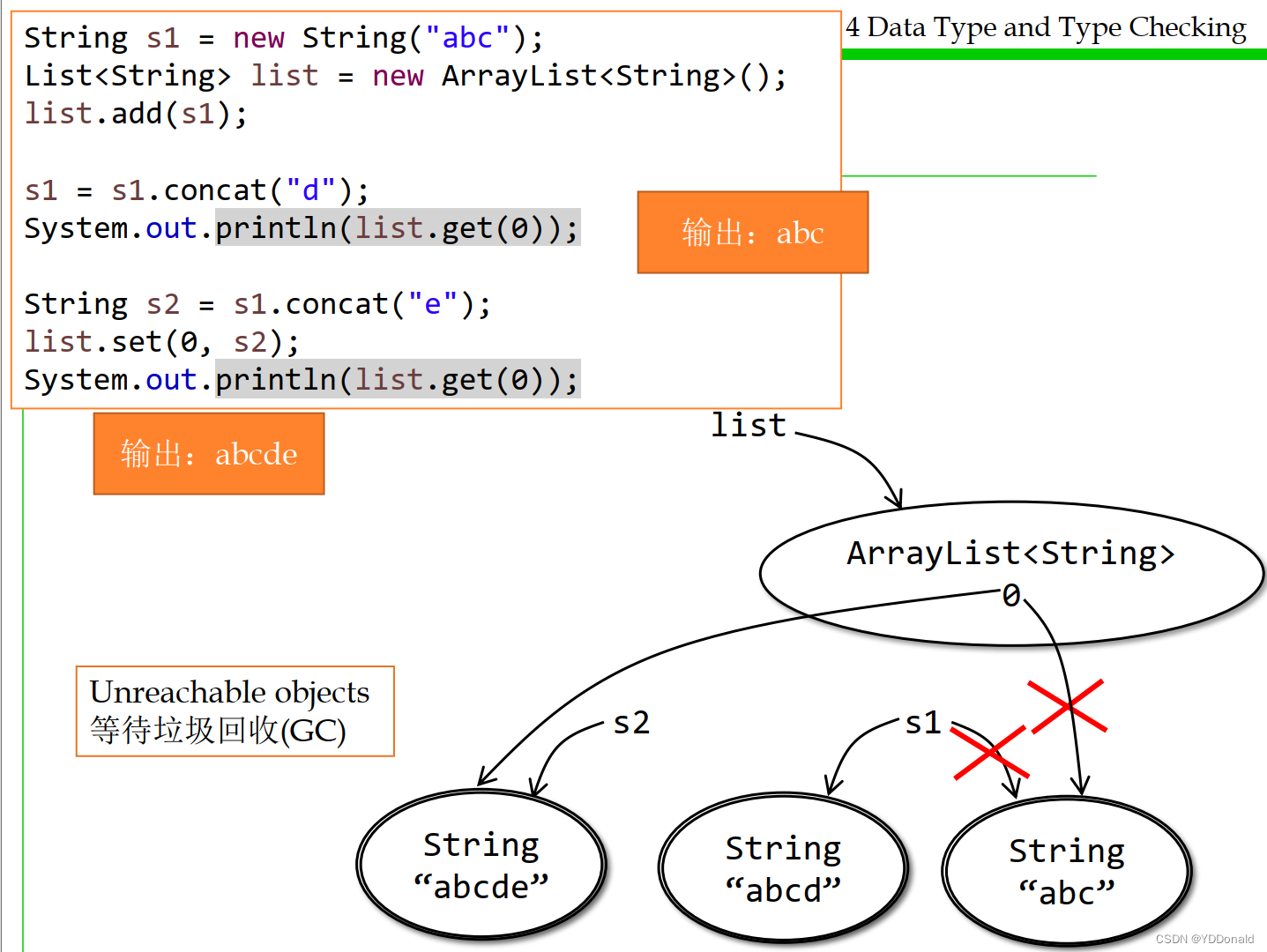
这里值得注意的是,list中添加s1后,实际上添加的是s1指向的内存地址。之后如果s1进行变化,由于其类型不可变,故不会影响list中下标为0的元素。所以对s1修改后,仍然输出abc。而使用set()方法,则会更改下标为0的元素指向s2指向的空间,于是输出abcde。
五、复杂数据类型与迭代器
集合框架下的复杂数据类型
java提供了许多常用的集合框架下的对象数据类型:Array、Set、List、Map等。
其中List/Map/Set都是接口,需要具体的实现:
- List: ArrayList 和 LinkedList
- Set: HashSet
- Map: HashMap
它们的基本使用方法这里不多介绍。
迭代器
迭代器(Iterator)是用于遍历集合中元素的对象。它是集合框架中的一部分,用于提供一种统一的方式来访问集合中的元素,而不需要了解集合的内部结构。迭代器属于可变数据类型。
迭代器一般具有两个方法:
- boolean hasNext(): 判断集合中是否还有下一个元素(实际上是是否遍历结束)。
- E next():返回集合的下一元素,并移动到下一个位置。
于是便可以使用这两个方法对集合元素进行遍历:
List<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Orange");
// 获取集合的迭代器
Iterator<String> iterator = list.iterator();
// 使用迭代器遍历集合
while (iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}
Java同时也提供了增强型for循环来遍历集合元素的方法。虽然这种方法没有显式地使用迭代器,但实际上其底层仍然使用了迭代器来遍历集合的元素。
// 创建一个 ArrayList 对象并添加一些元素
List<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Orange");
// 使用增强型 for 循环遍历集合中的元素
for (String str : list) {
System.out.println(str);
}
当然,我们可以自己编写一个迭代器,如图所示:
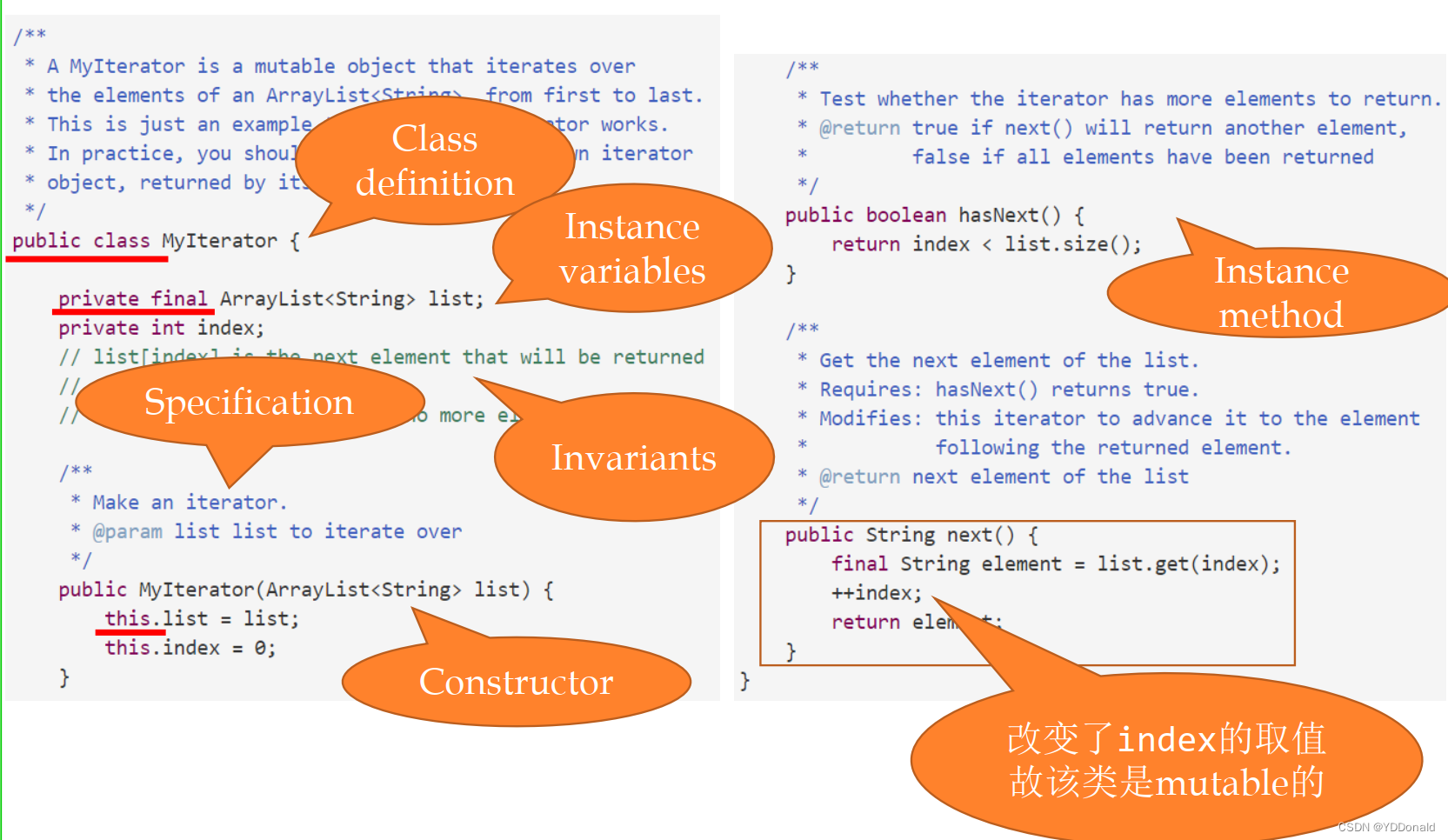
这里通过对元素下标的判断与处理实现了一个ArrayList< String >类型的迭代器。由于next()方法对实例变量index进行了修改,所以这个迭代器的数据类型是可变的。
值得注意的是,不建议在遍历过程中修改集合(虽然java的迭代器提供了remove()操作),否则容易出现意想不到的错误。其根本原因就是迭代器在遍历的过程中实例变量index在不断变化,而对集合的修改操作如删除元素,会导致集合中元素的下标与迭代器中的下标出现偏差。
比如使用迭代器遍历一个列表,删除所有以“6.”开头的元素。
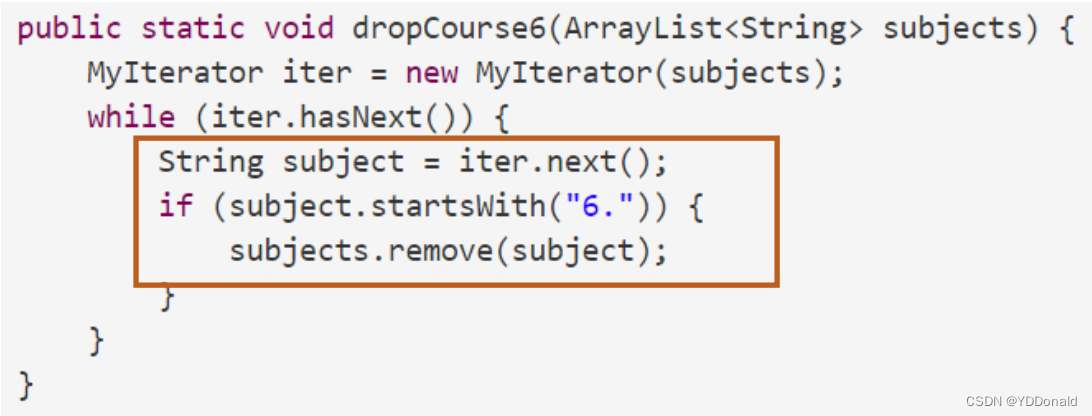
画出快照图:
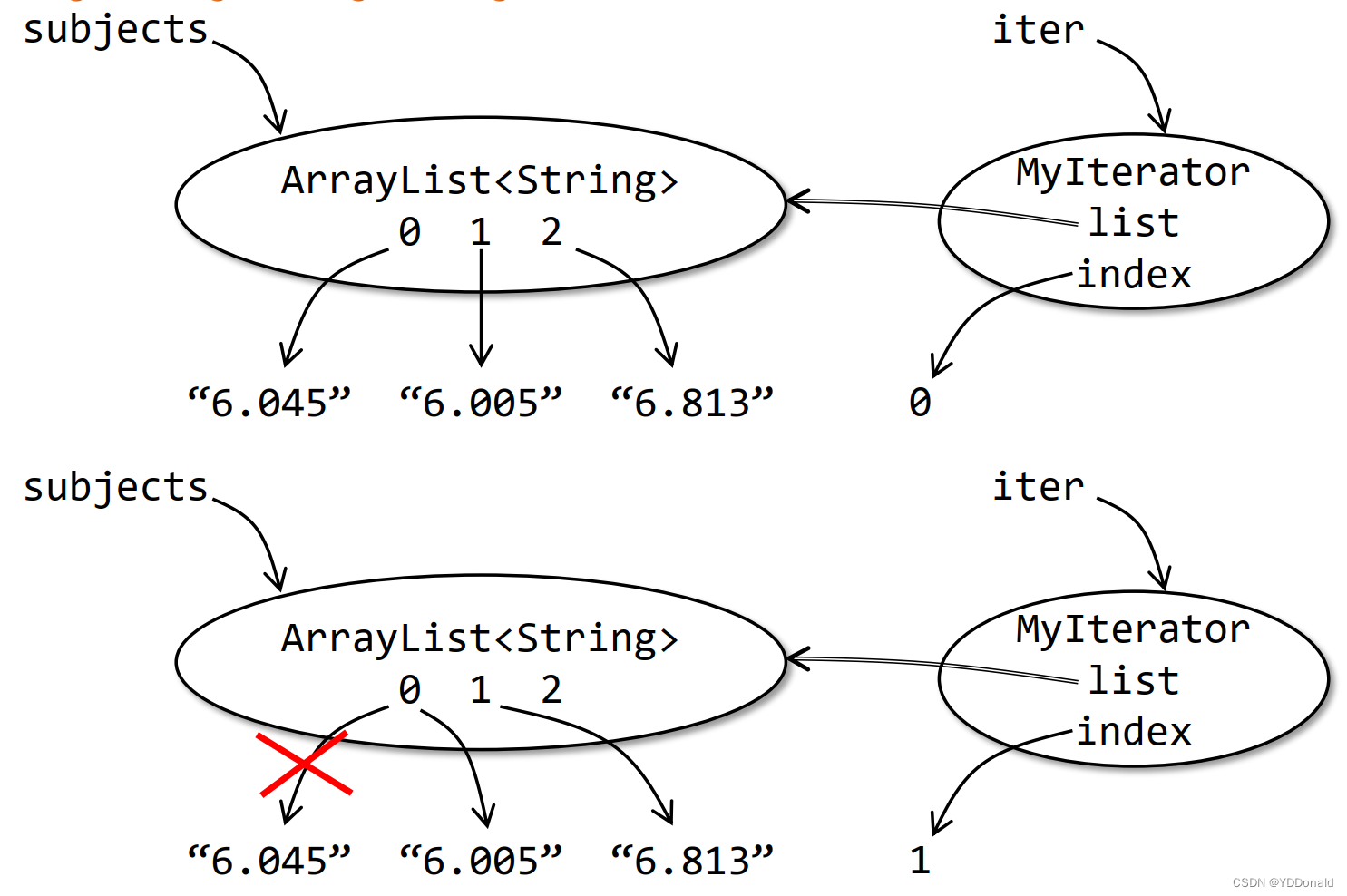
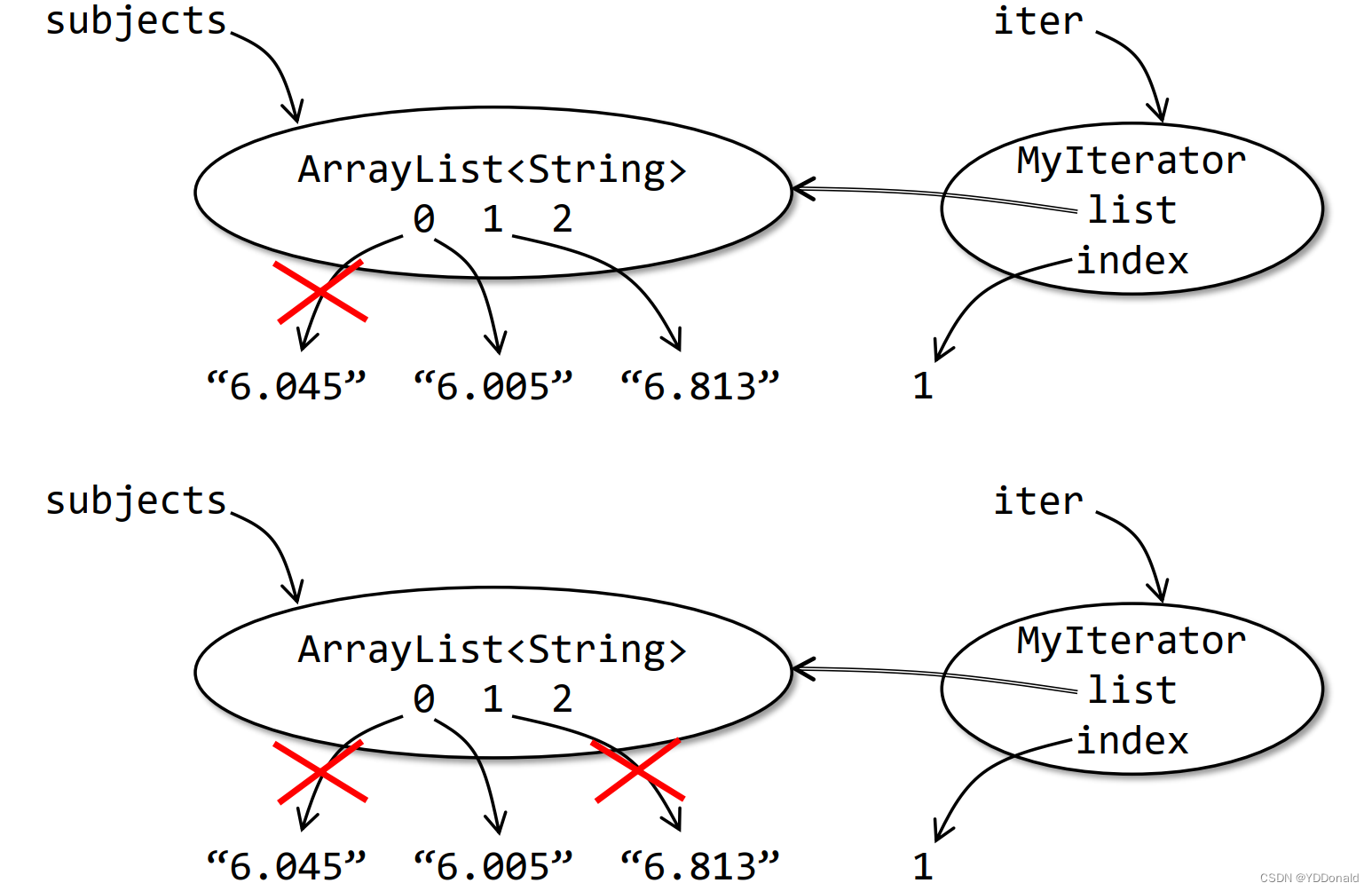
错误显而易见。
那么应该如何避免出现这样的问题呢?这时就不应该使用集合类的remove()方法,而是使用迭代器自带的remove()方法。因为迭代器的remove()方法会针对这种情况进行下标的调整:
Iterator iter = subjects.iterator();
while(iter.hasNext()){
String subject = iter.next();
if(subject.startsWith("6.")){
iter.remove();
}
}
这样程序就不会出错了。















 2248
2248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









