







前言
没有前言…
一、存储引擎
就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)。
1. 背景
🍕MySQL体系结构
![![[Pasted image 20230606213247.png]]](https://img-blog.csdnimg.cn/14aa2cda35cf46b3b442fc04282dd683.png)
🍕存储引擎:存储数据、建立索引、更新/查询数据等技术的实现方式。
基于表,而不是基于库
在一个数据库中的多张表可以选择不同的存储引擎,也被称为表类型, M y S Q L 5.5 MySQL5.5 MySQL5.5后,存储引擎默认版本为InnoDB
🍕指定方式:
creat table 表名{
字段1 字段1类型,
...
字段n 字段n类型
} engine = innodb;
show engines;查询当前数据库支持的存储引擎
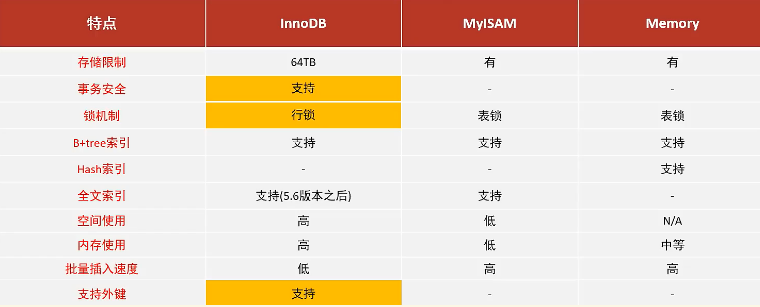
2. 存储引擎特点
2.1. innodb
🍕特点:DML操作(增删改)遵循ACID模型,支持事务、外键、行级锁(提高并发访问性能)
![![[Pasted image 20230607100927.png]]](https://img-blog.csdnimg.cn/a028648074874cb286a727ef47355c7f.png)
xxx.ibd:xxx代表的是表名, innoDB引擎的每张表都会对应这样一个表空间文件 ,存储该表的表结构(frm、sdi)、 数据和索引
2.2. MyISAM
🍕特点:不支持事务、外键、行锁,支持表锁,访问速度快
🍕文件:xxx.sdi:存储表结构信息、xxx.MYD:存储数据、xxx.MYI:存储索引
2.3.Memory
🍕介绍:Memory引擎的表数据时存储在内存中的,由于受到硬件问题、或断电问题的影响,只能将这些表作为临时表或缓存使用。
🍕特点:内存存放,访问速度很快、拥有hash索引
- 文件:xxx.sdi:存储表结构信息
innodb与myisam的区别是什么?
3.存储引擎的选择
🍕innodb:innodb支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致,数据操作除了插入和查询之外,还包含很多的更新、删除操作(唯一支持事务,用的最多)
🍕myisam:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高(电商中足迹、评论等数据处理时用)
🍕memory:数据保存在内存中,访问速度快,通常用于临时表及缓存。缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性
二、MySQL安装(Linux版)
mysqld是服务,mysql是客户端
mysqld其实是SQL后台程序(也就是MySQL服务器),它是关于服务器端的一个程序,mysqld意思是mysql daemon,在后台运行,监听3306端口,如果你想要使用客户端程序,这个程序必须运行,因为客户端是通过连接服务器来访问数据库的。你只有启动了mysqld.exe,你的mysql数据库才能工作
🍕下载MySQL8.0.34
# 卸载mariadb
rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64
# 下载最新的mysql下载到指定目录/usr/local/mysql/下
wget -P /usr/local/mysql/ https://cdn.mysql.com//Downloads/MySQL-8.0/mysql-8.0.34-1.el7.x86_64.rpm-bundle.tar
# 解压
tar -xvf mysql-8.0.34-1.el7.x86_64.rpm-bundle.tar
# 安装
rpm -ivh mysql-community-common-8.0.34-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-8.0.34-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-client-8.0.34-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-server-8.0.34-1.el7.x86_64.rpm --nodeps --force
# root用户下需要初始化
mysqld --initialize --user=mysql
# 设置免密登录,最后一行加入
vim /etc/my.cnf
skip-grant-tables
# 重启MySQL服务
systemctl restart mysqld
# 登录MySQL
mysql
use mysql;
update user set authentication_string='' where user='root';
# 回到/etc/my.cnf,注释掉skip-grant-tables,重启MySQL
systemctl restart mysqld
ALTER USER 'root'@'localhost' IDENTIFIED BY 'lovexw999';
FLUSH PRIVILEGES;
遇到
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)怎么办!!
重新加上skip-grant-tables,进入MySQL后将密码设置为空use mysql ; update user set authentication_string='' where user='root';,再把它注释掉,登录即可修改密码~
三、索引(提高检索效率)
1. 索引概述
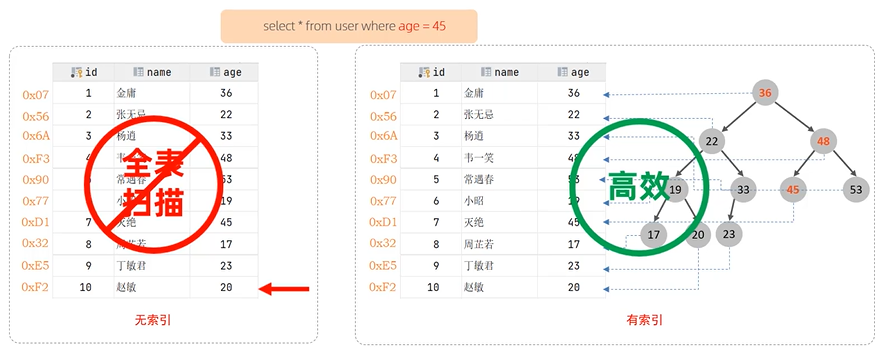
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引
🍕演示(select效率嘎嘎提升):
🍕优缺点:

2. 索引结构
🍕MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含以下几种:

🍕各引擎对索引的支持情况:
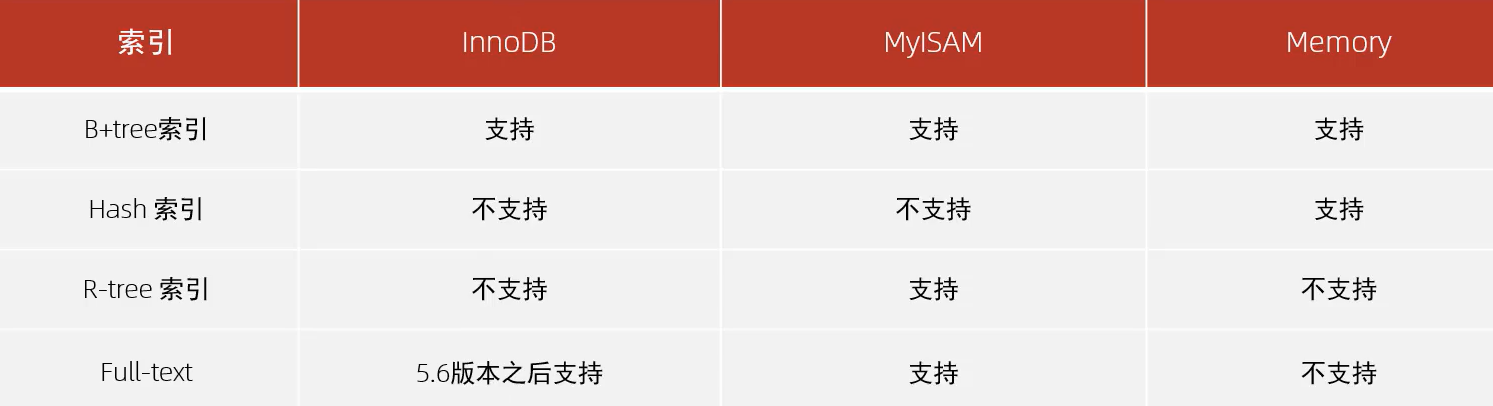
我们平常所说的索引,如果没有特别指明,都是指B+树结构组织的索引
🍕二叉树:

二叉树缺点:顺序插入时,会形成一个链表,查询性能大大降低。大数据量情况下,层级较深,检索速度慢
红黑树:大数据量情况下,层级较深,检索速度慢
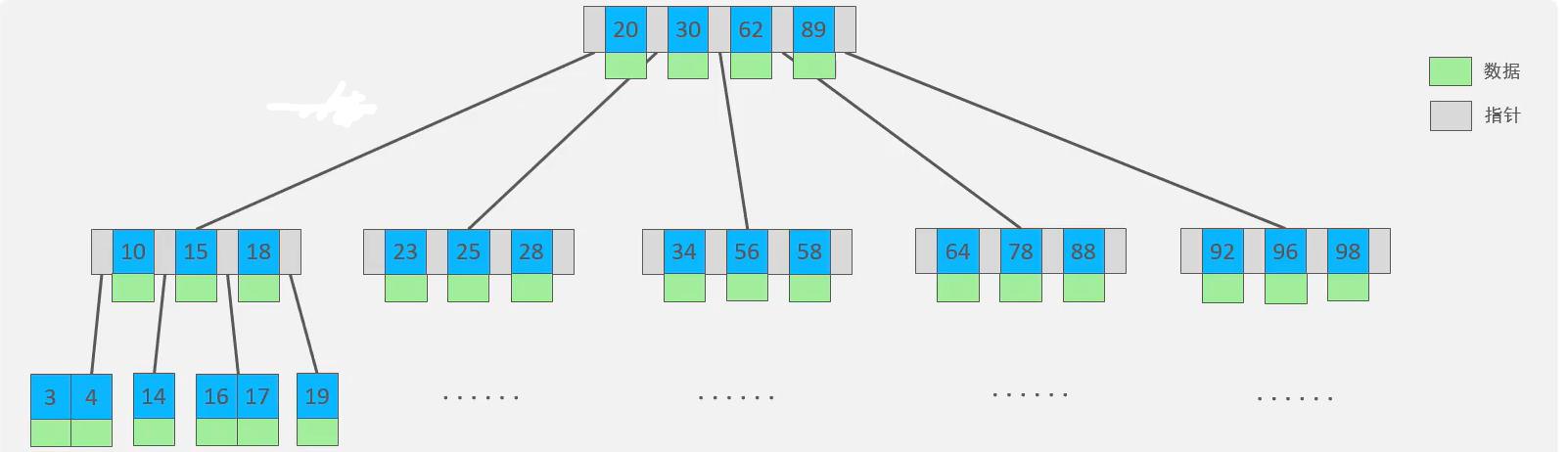
🍕B-tree(多路平衡查找树),以一颗最大度数(一个节点的子节点个数)为5(5阶)的b-tree为例(每个节点最多存储4个key划分成5个区域,5个指针):
🌰动态演示:点此👉前往q(≧▽≦q)
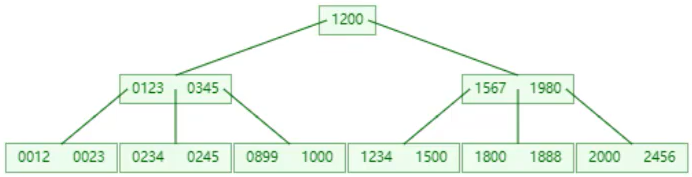
一个节点通过一个磁盘块或者叫一页来存放,一页的大小是固定的16K,我们发现B-tree每个节点都要存放数据,而下面的B+tree的分支点不存放数据,那么一页中能够存放的键值key和指针就会增多,最终在相同数据量的情况下,B+tree的层级就会更少
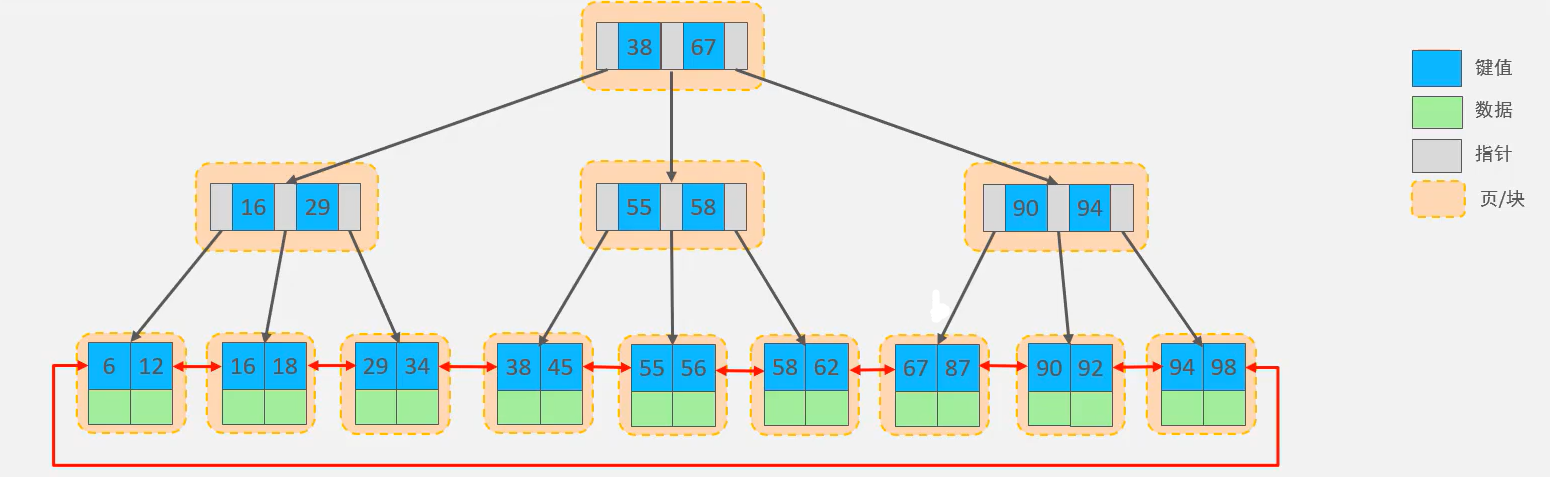
🍕B+tree,以一颗最大度数(一个节点的子节点个数)为4(4阶)的b+tree为例:
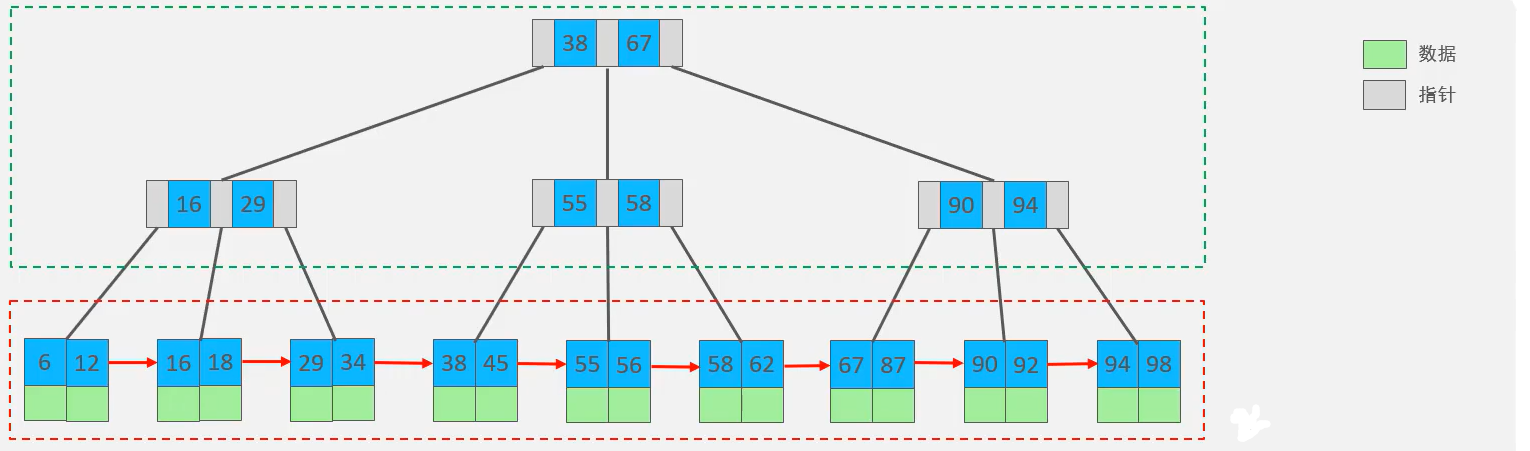
特点:
- 非叶子节点起到索引作用不存数据,叶子节点包含了所有插入的元素和数据
- B+Tree中所有叶子结点(所有元素)形成了一个单向链表
🌰动态演示:点此👉前往q(≧▽≦q)
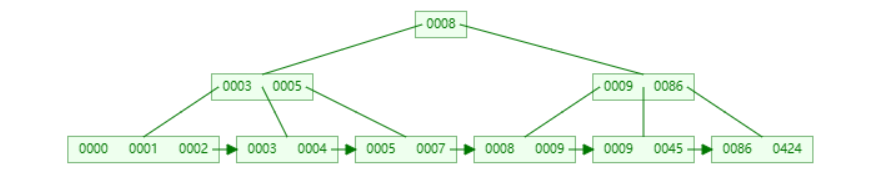
🍕MySQL中的B+tree:MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的双向链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能(也支持范围查询)
🍕Hash:哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中,如果两个(或多个)键值,映射到一个相同槽位上,他们就产生了hash冲突,可以通过链表来解决
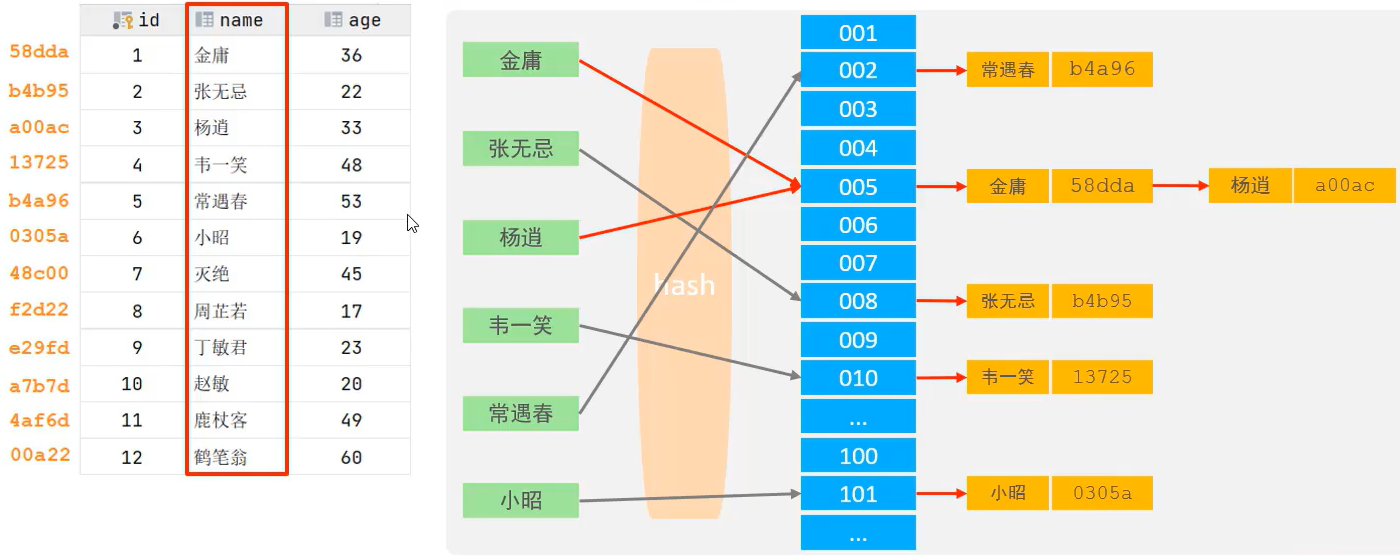
特点:
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,<,…)
- 无法利用索引完成排序操作
- 查询效率高,通常只需要一次检索就可以了(不出现hash冲突的情况下),效率通常要高于B+tree索引
在MysQL中,支持hash索引的是Memory引擎,而innoDB中具有自适应hash功能,是根据B+Tree索引在指定条件下自动构建hash索引
3. 索引分类

🍕在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:

聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
🍕图解聚集索引、二级索引:
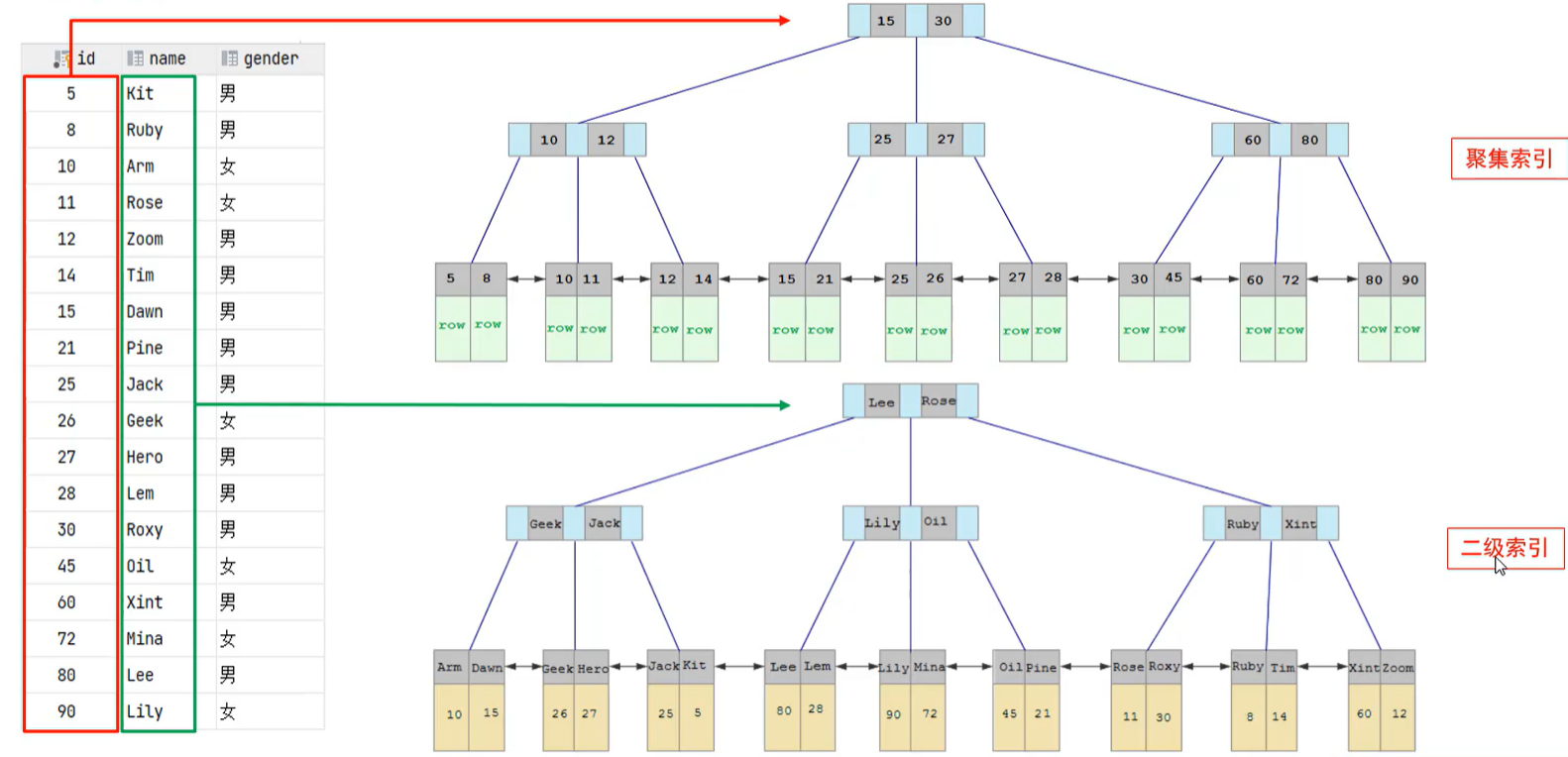
都是B+tree结构,不同的是聚集索引的叶子节点存放了这一行所有的数据,二级索引的叶子节点存放主键id值
回表查询:先从二级索引中找到对应的主键值,再根据主键值回到聚集索引拿到这一行的行数据
🍕lnnoDB主键索引的B+tree在不同数据量时的高度为多高呢?

4. 索引语法
🍕创建索引:create [unique | fulltext] index index_name on table_name (index_col_name,...);
# 建立 tb_user、tb_sku 两张表,从DG里面用show create table 表名 来复制建表语句来Linux中建表
# name字段为姓名字段,该字段的值可能会重复。为该字段创建索引(idx_...索引命名规范)
create index idx_user_name on tb_user(name);
# phone手机号字段的值,是非空,且唯一的,为该字段创建唯一索引
create unique idx_user_phone on tb_user(phone);
# 为profession/age/status创建联合索引(字段顺序有讲究)
create index idx_user_pro_age_sta on tb_user(profession,age,status);
🍕查看索引:show index from tale_name;
show index from tb_user;
🍕删除索引:drop index index_name on table_name;
drop index idx_user_name on tb_user;
5. SQL性能分析
🍕SQL执行频率:MySQL客户端连接成功后,通过show [session | global] status命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次
# 7个下划线
show global status like 'Com_______';
🌰查询结果如图:
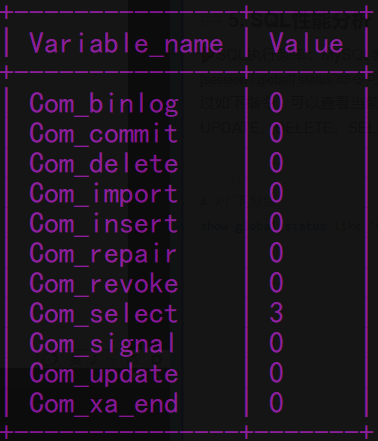
我们一般是select语句占大多数,那就要针对其优化,要对哪些语句进行优化要借助下面的慢查询日志
🍕慢查询日志:慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。MySQL的慢查询日志默认没有开启
# 查看慢查询日志是否开启
show Variables like '%show_query_log%';
# 开启My5QL查询慢日志
set global slow_query_log=on;
# 再创建一个Linux窗口
vim /etc/my.cnf
# 在[mysqld]下面加上,保证永久生效
slow_query_time=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2
🌰配置完毕之后,通过以下指令重新启动MySQL服务器进行测试service mysqld restart;在mysql中输入show variables like 'slow_%;查看慢日志文件中记录的信息,找到slow_query_log_file对应的value值(即路径),重新打开一个linux远程窗口,cat 该路径查看对应的慢查询日志
# 实时查看日志更新,查看到的内容(效率低的语句)就是需要优化的sql语句
tail -f 用户名-slow.log
🍕profile详情:show profiles能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。通过have_profiling参数,能够看到当前MySQL是否支持profile操作
select @@have_profiling;
默认profiling是关闭的,可以通过set语句在session/global级别开启profiling:
# 查看profiling开关是否打开
select @@profiling;
# 打开
set profiling = 1;
# 查看所有sql语句的执行耗时情况
show profiles;
# show profile for query query_id;
# 查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query 3;
# show profile cpu for query query_id;
# 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query 3;
🍕explain执行计划:EXPLAIN或者DESC命令获取MySQL如何执行SELECT语句的信息,包括在SELECT语句执行过程中表如何连接和连接的顺序。语法:
# 直接在select语句之前加上关键字explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件;
🍕查询到的执行计划各字段含义:

| 字段 | 含义 |
|---|---|
| id | select查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行) |
| select_type | 表示SELECT 的查询类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY (SELECT/WHERE之后包含了子查询)等 |
| table | 表名 |
| type | 表示连接类型,性能由好到差的连接类型为NULL、System、const、eq_ref、ref、range、index、all |
| possible_keys | 显示可能应用在这张表上的索引,一个或多个 |
| key | 实际使用的索引,如果为NULL,则没有使用索引 |
| key_len | 表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好 |
| ref | 查询普通索引去查的时候就是ref |
| rows | MySQL认为必须要执行查询的行数,在innodb引擎的表中,是一个估计值,可能并不总是准确的。 |
| filtered | 表示返回结果的行数占需读取行数的百分比,filtered的值越大越好 |
| Extra | 执行查询到过程中没有展示出来的值将会在这额外的展示 |
🌰例子:
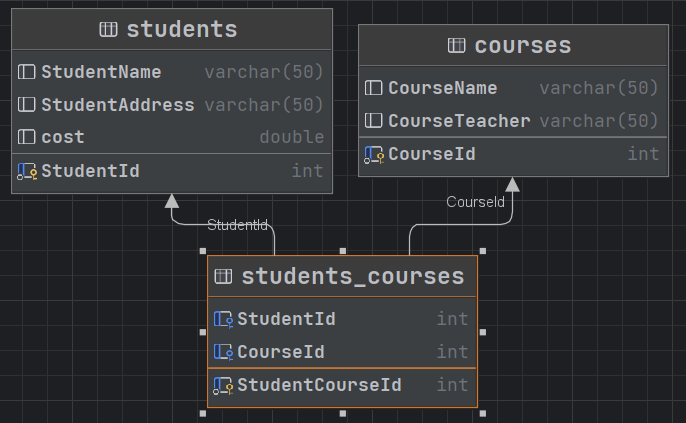
# 查询所有学生的选课信息,加\G列式查询
select s.*, c.* from students s, courses c,students_courses sc where s.StudentId = sc.StudentId and c.CourseId = sc.CourseId\G;
# 查询执行计划
explain select s.*, c.* from students s, courses c,students_courses sc where s.StudentId = sc.StudentId and c.CourseId = sc.CourseId\G;
6. 索引使用
6.1. 最左前缀法则
🍕指的是查询从索引的最左列开始(只要最左列存在,跟位置无关),并且不跳过索引中的列。如果索引了多列(联合索引),要遵守最左前缀法则,如果跳跃某一列,索引将部分失效(后面的字段索引失效)
🌰联合索引例子show index from tb_user;:

- explain/desc查询profession、age字段(索引生效):
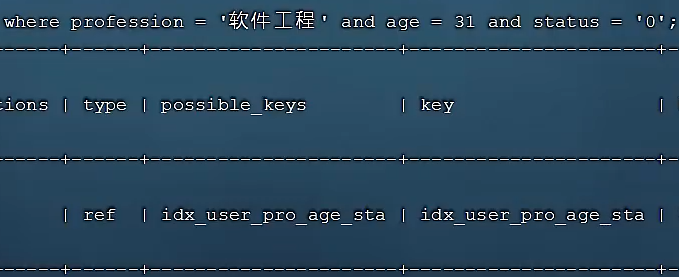
- explain/desc查询age、status字段(索引失效):
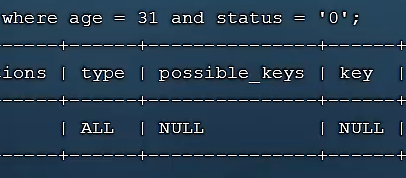
- explain/desc单查一个status字段(索引失效):
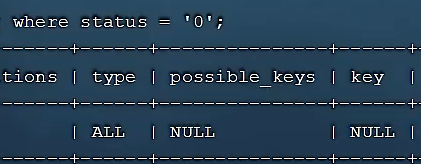
- explain/desc查询profession、status字段(索引部分失效,status没有age来连接故失效)
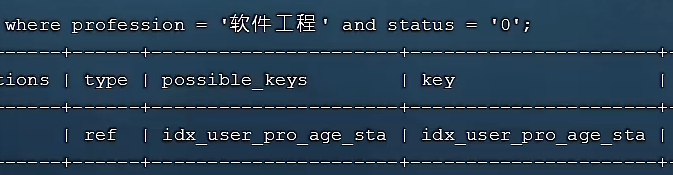
6.2. 范围查询
🍕联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效
🌰例子(上面用>右侧的status索引失效,下面用≥索引全生效):
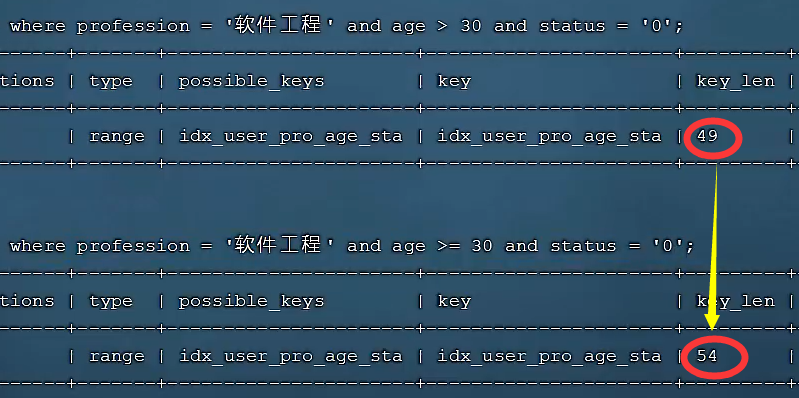 所以在允许的情况下有索引时尽量用
所以在允许的情况下有索引时尽量用≥≤
6.3. 索引列运算
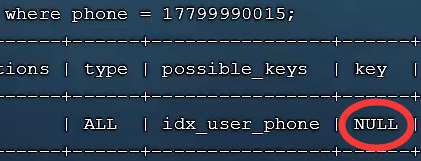
🍕不要在索引列上进行运算操作,索引将失效
🌰例子(运用函数运算phone索引失效):

6.4. 字符串不加引号
🍕字符串类型字段使用时,不加引号,索引将失效
🌰例子(索引失效):
6.5. 模糊查询
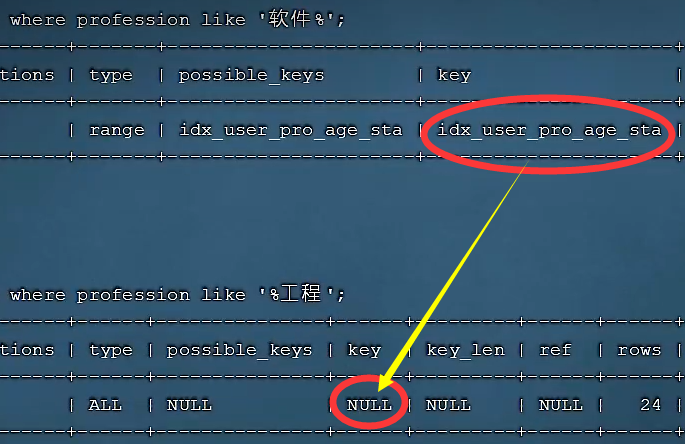
🍕如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效
🌰例子(前面加%模糊匹配变成全表扫描,索引失效):
6.6. or连接条件
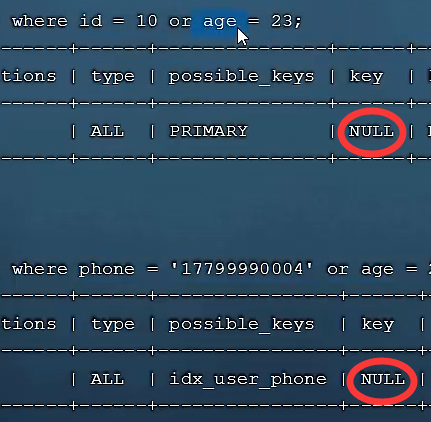
🍕用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到,两侧都有索引才生效
🌰例子:
6.7. 索引分布影响
🍕如果MySQL评估使用索引比全表扫描更慢,则不使用索引。取决于数据分布情况,MySQL自动调整
🌰例子(绝大多数phone≥‘17799990000’自动评估后使用全表扫描):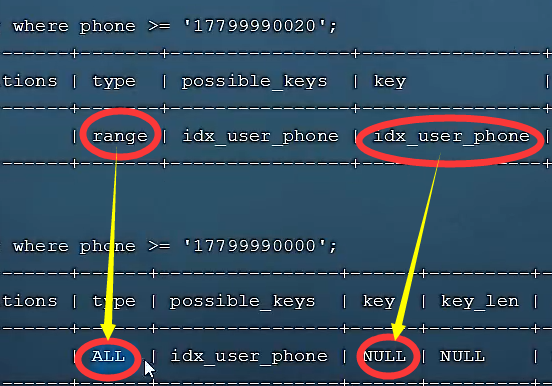
6.8. SQL提示
🍕SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的
| 提示 | 说明 |
|---|---|
| use index | 建议MySQL用这个索引 |
| ignore index | 告诉MySQL忽略这个索引 |
| force index | 强制MySQL必须用这个索引 |
🌰例子:

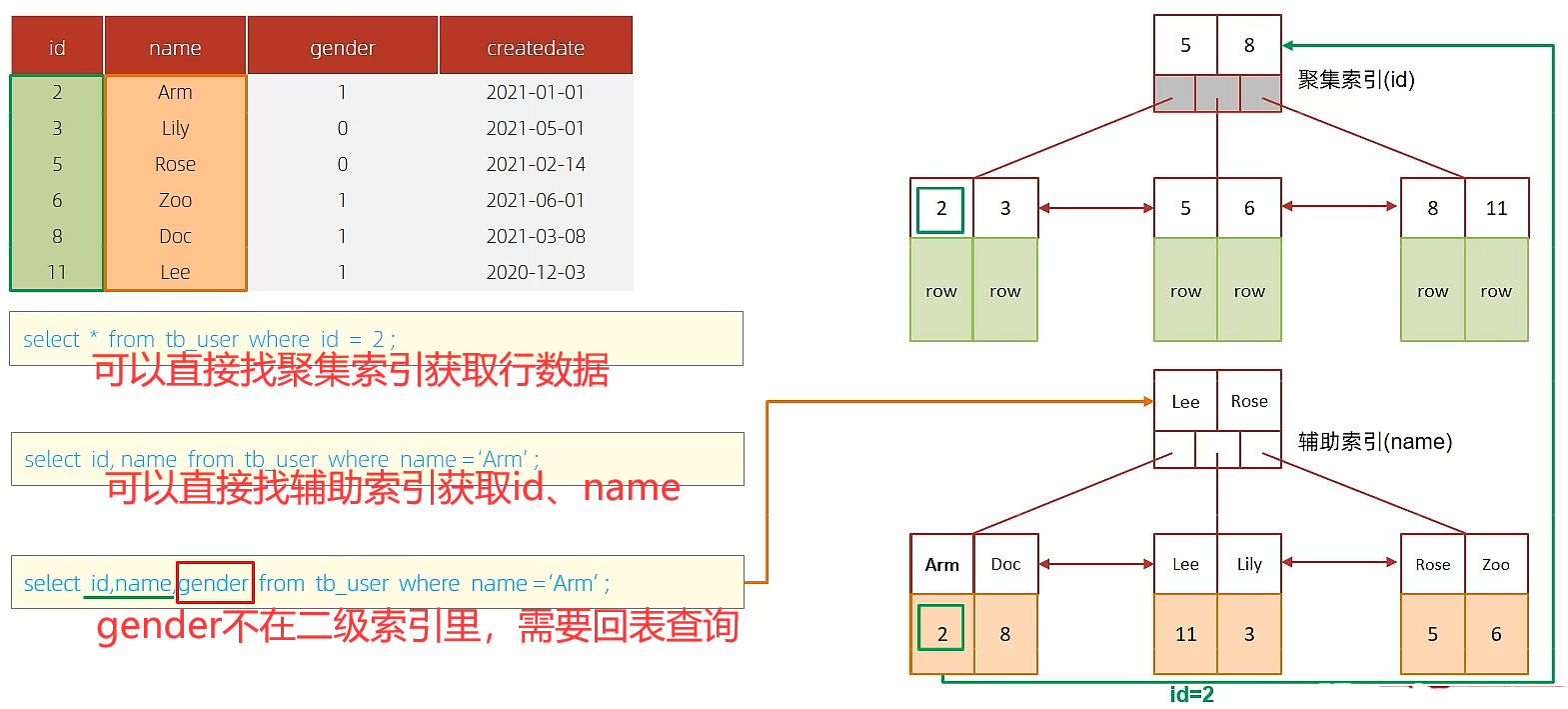
6.9. 覆盖索引
🍕尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到的),减少select *(避免回表查询)
🌰例子:explain select id, profession from tb_user where profession='软件工程' and age=31 and status = '0' ;

Extra解读:
using index condition:查找使用了索引,但是需要回表查询数据using where; using index:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
🌰思考:一张表,有四个字段(id, username, password, status),由于数据量大,需要对select id,username,password from tb_user where username = 'itcast'; 进行优化,该如何进行才是最优方案?
答:对username、password建立联合查询
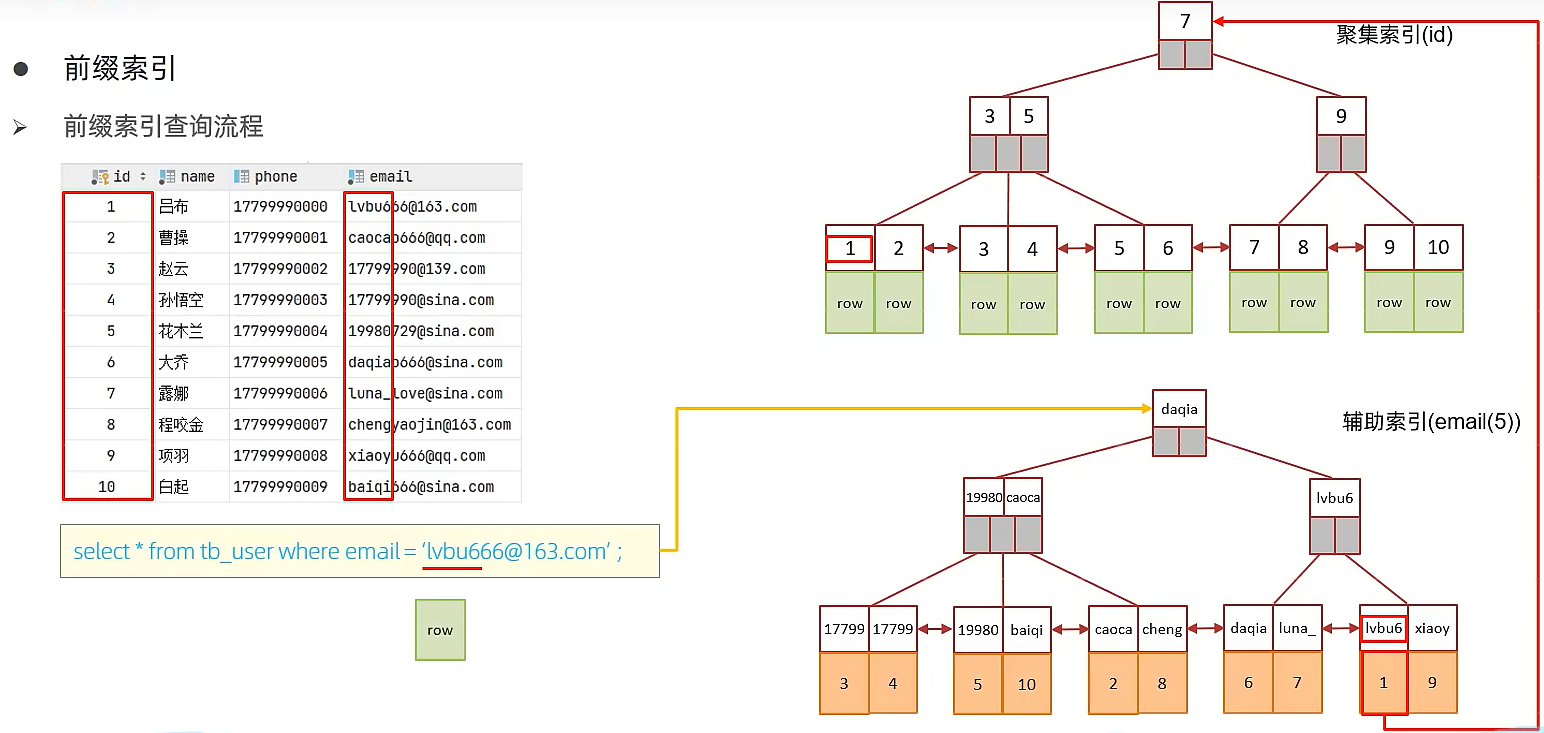
6.10. 前缀索引
🍕当字段类型为字符串(varchar, text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘lO,影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引的体积,从而提高索引效率,语法create index idx_xxx on table_name(column(n));
前缀长度n:可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的
# 查询email选择性的值,看看n=5时选择性如何,根据需要不断调整n的值
select count(distinct substring(email,1,5))/count(*) from tb_user ;
6.11. 单列索引和联合索引
🍕单列索引:即一个索引只包含单个列;联合索引:即一个索引包含了多个列。在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
🌰例子:
- 单列索引:

用的是phone索引只能找到id和phone,name字段就需要回表查询 - 建立联合索引后(无需回表查询):

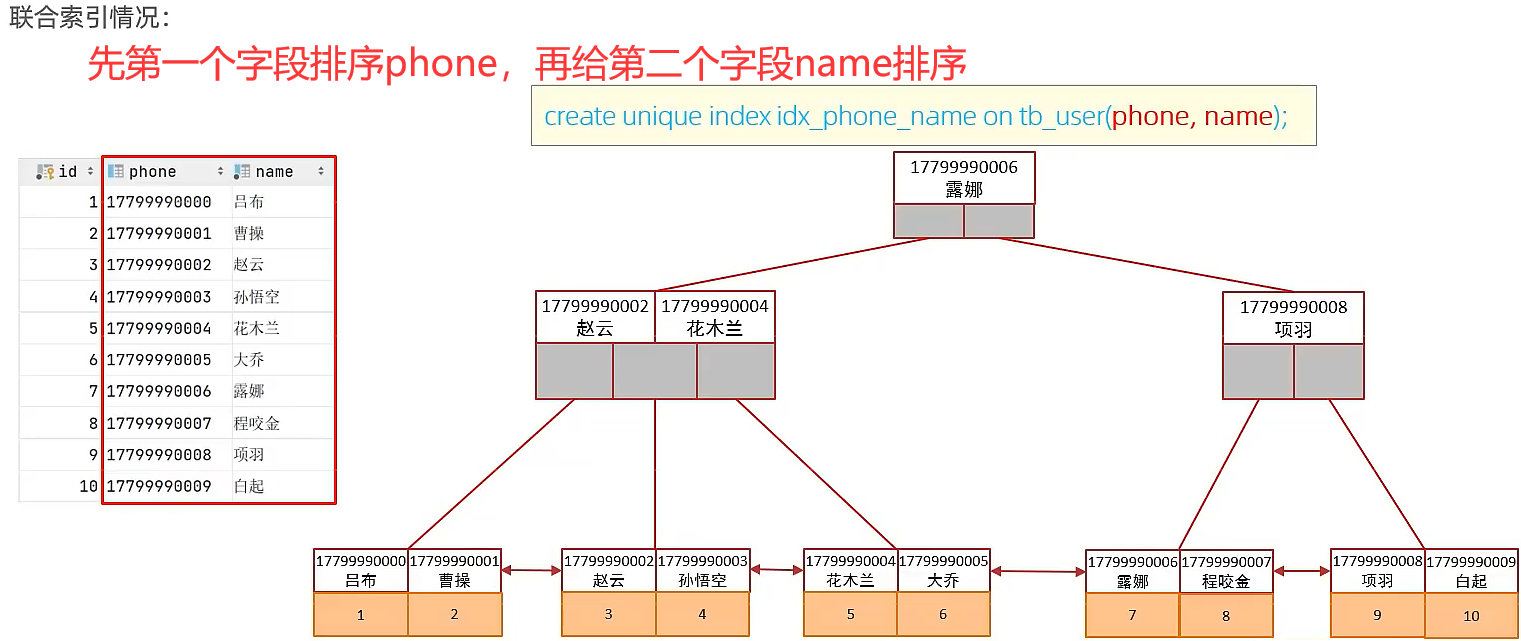
创建联合索引时要考虑字段顺序,用的多字段放前面,因为要遵循最左前缀法则,避免索引失效
7. 索引设计原则
- 针对于数据量较大(>100万),且查询比较频繁的表建立索引
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询
四、SQL优化
1. 插入数据
🍕insert优化:
- 批量插入(1000条以内):
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'jerry'); - 手动提交事务:
start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'jerry');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'jerry');
insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'jerry');
commit;
- 主键顺序插入:
(1,'Tom'),(2,'Cat'),(3,'jerry')
🍕大批量插入数据:如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。操作如下:
# 客户端连接服务端时,加上参数 --local-infile
mysql --local-infile -u root -p
# 查看全局参数local_infile是否开启
select @@local_infile;
# 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
# 我们再开一个cmd
sftp root@Linux主机名
# 上传数据put,下载get
put F:\a.sql
# 回到MySQL执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/a.sql' into table 'tb_user' fields terminated by ',' lines terminated by '\n';
主键顺序插入性能高于乱序插入
2. 主键优化
🍕数据组织方式:在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table, lOT)
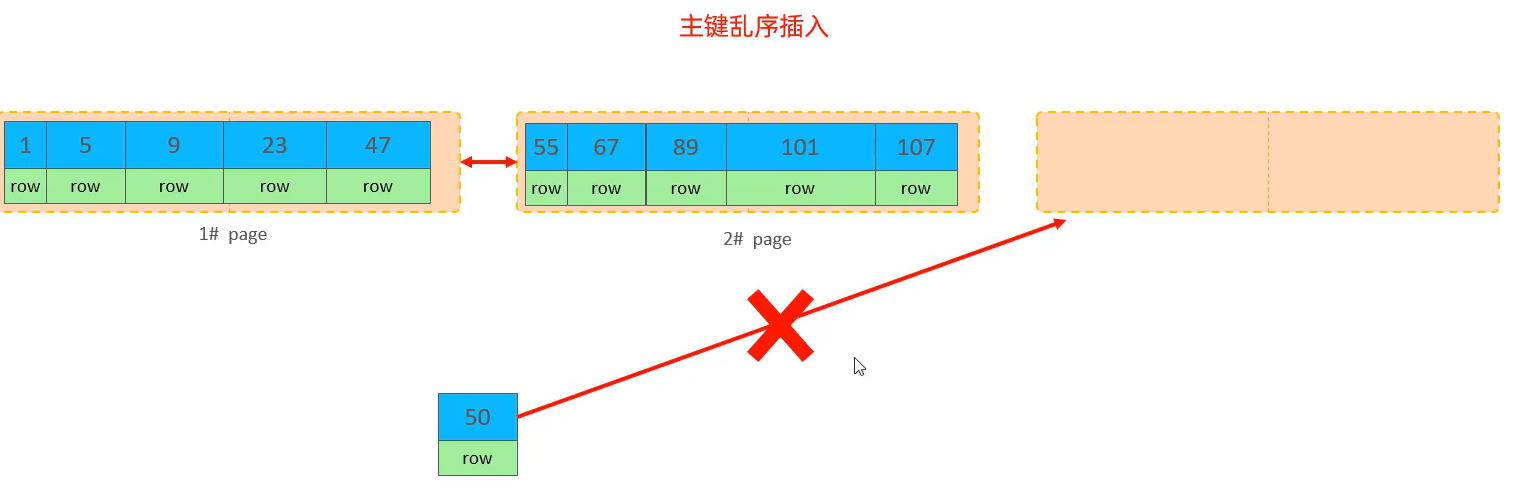
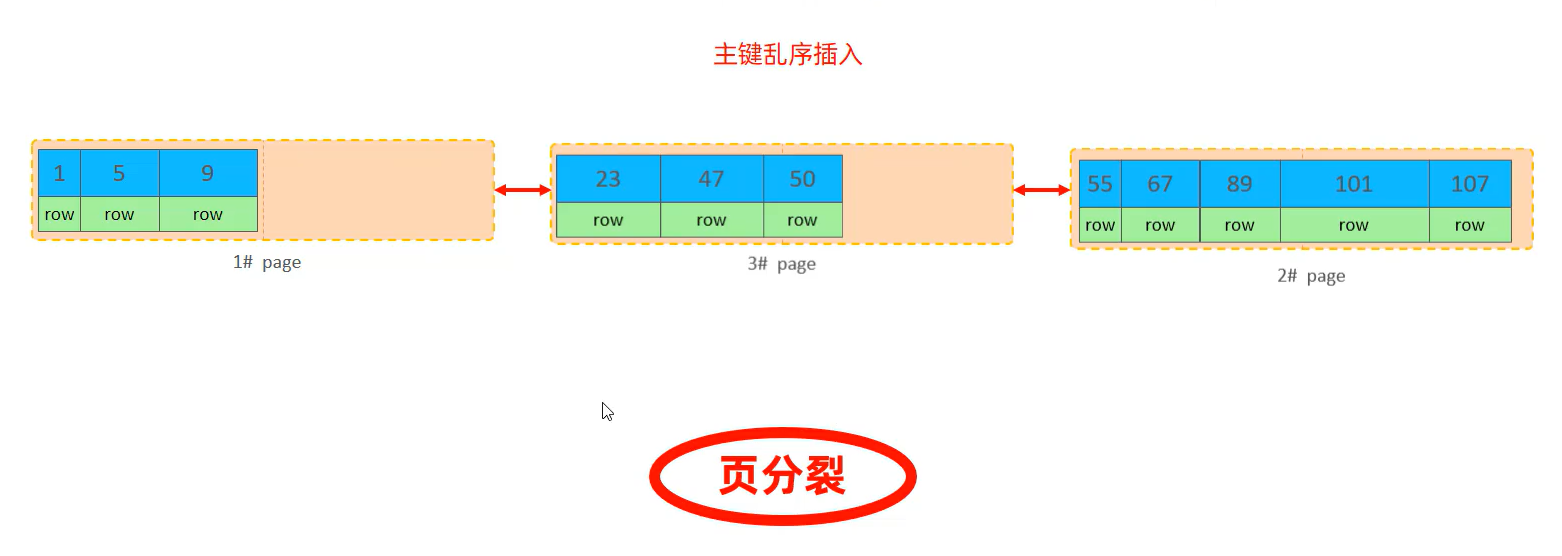
🍕页分裂:页可以为空,也可以填充一半,也可以填充100%。每个页包含了2到N行数据(如果一行数据过大,会行溢出),根据主键排列
🌰图例说明:

🍕页合并:当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用,当页中删除的记录达到MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用
🌰图例说明:
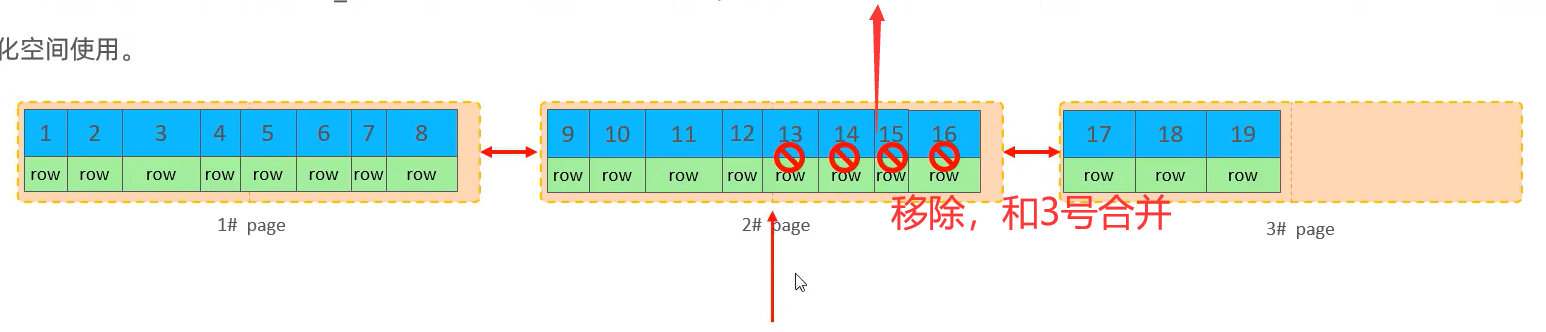

MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定。
🍕主键设计原则:
- 满足业务要求的情况下,尽量降低逐渐的长度(因为二级索引叶节点中存储的是主键数据)
- 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键
- 尽量不要使用UUID做主键或者是其他自然主键,如身份证号
- 业务操作时,避免对主键的修改
3. order by优化
🍕Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫FileSort排序(优化对象)
🍕Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高(目标)
需要注意的几点:
- 对要使用
order by来排序的字段,建立索引前Extra显示Using filesort效率低下,我们创建索引后变成Using index,通过索引返回有序数据,性能更高- 字段排序顺序跟联合索引顺序有关,不一致就会出现
Using filesort- 优化排序时,创建索引最好也指定一下升降序,例:
create index idx_user_age_pho_ad on tb user(age asc , phone desc);,否则默认升序,排序时升降序不一致会出现Using filesort- 优化的前提是使用了覆盖索引
- 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小 sort_buffer_size(默认256k)
4. group by优化
🍕优化目标:Using temporary➡Using index
在分组操作时,可以通过索引来提高效率,索引的使用也是满足最左前缀法则的
因为也是利用索引优化,故注意事项同SQL优化部分,上去复习!
5. limit优化
一个常见又非常头疼的问题就是limit 2000000,10,此时需要MySQL排序前2000010记录,仅仅返回2000000至2000010的记录,其他记录丢弃,大数据量时查询排序的代价非常大
🍕优化思路:一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引➕子查询形式进行优化。
# 查询sku表中 2000000-2000010 数据
explain select s.* from tb_sku t , (select id from tb_sku s order by id limit 2000000,10) a where t.id = a.id;
6. count优化
前提是没有where条件的情况下(不然都慢😅):
MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高
InnoDB引擎就麻烦了,它执行count(*)的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数
🍕优化思路:自己计数😅
🍕count的几种用法:
| 用法 | 说明 |
|---|---|
| count() | 是一个聚合函数,对于返回的结果集,一行行地判断,如果count 函数的参数不是NULL,累计值就加1,否则不加,最后返回累计值 |
| count(*) | 查询表中总记录数 |
| count(主键) | 依旧是总记录数,主键必非空 |
| count(字段) | 查询非空字段数 |
| count(1) | 会统计表中的所有的记录数,包含字段为null 的记录 |
按照效率排序的话,count(字段)< count(主键id)< count(1) ≈ count(*),所以尽量使用count(*)。
7. update优化
🍕InnoDB的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁
想要优化,update的对象得加索引,不加索引的字段会有表锁,锁住整张表使得性能下降,加索引即行锁,可并发update多个对象
总结
学习了引擎、索引(重点)、SQL优化,多复习基础篇知识,边温故边学新
上面用了一个sftp,SFTP(SSH File Transfer Protocol,也称 Secret File Transfer Protocol),是一种安全的文件传输协议,一种通过网络传输文件的安全方法;它确保使用私有和安全的数据流来安全地传输数据。 SFTP传输文件的过程,如下图:
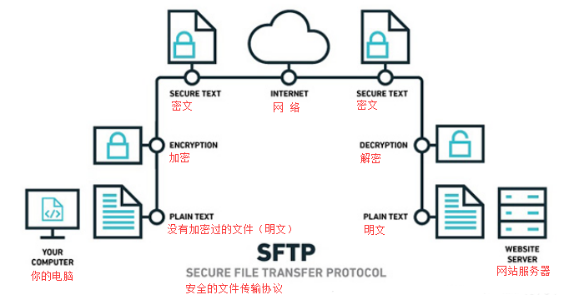
SFTP要求客户端用户必须由服务器进行身份验证,并且数据传输必须通过安全通道(SSH)进行,即不传输明文密码或文件数据。它允许对远程文件执行各种操作,有点像远程文件系统协议。SFTP允许从暂停传输,目录列表和远程文件删除等操作中恢复。
下一站视图/存储过程/触发器、锁🔒















 934
934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









