







前言
大数据解决的无非是海量数据的采集、存储、计算,Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。flume能保证数据的可靠性,但不能保证数据的重复性
一、Flume概述
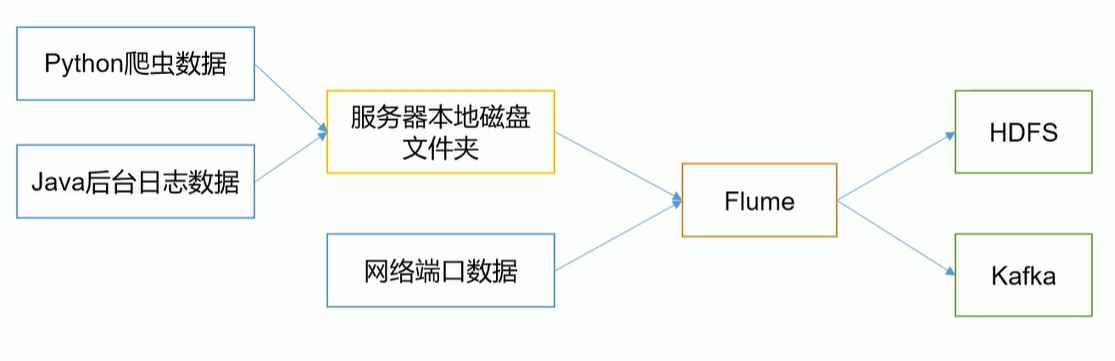
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS
Flume基础架构
🍠Flume组成架构如下图所示:
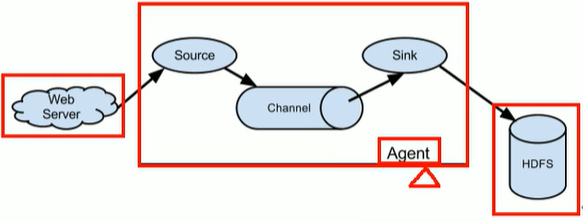
👉架构解读:
Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。Agent主要有3个部分组成,Source、Channel、SinkSource
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacyChannel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。Flume自带两种Channel:Memory Channel和File Channel
1️⃣
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失
2️⃣File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据,但是慢
-
Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义 -
Event
将数据封装成传输单元,Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地。 Event由可选的header和载有数据的一个byte array 构成。Header是容纳了key-value字符串对的HashMap
二、Flume-1.9.0安装➕入门案例
官方详细文档.👉点击查看,后面的配置文件要根据自身情况酌情修改避免出bug!
1. 下载1.9.0解压
# 下载
cd /opt/software;wget https://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
# 解压
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/module/;cd /opt/module/;ll
# 改名
mv apache-flume-1.9.0-bin/ flume-1.11.0;ll
# 删除guava-11.0.2.jar用来兼容Hadoop
cd lib;rm -rf flume-1.9.0/lib/guava-11.0.2.jar
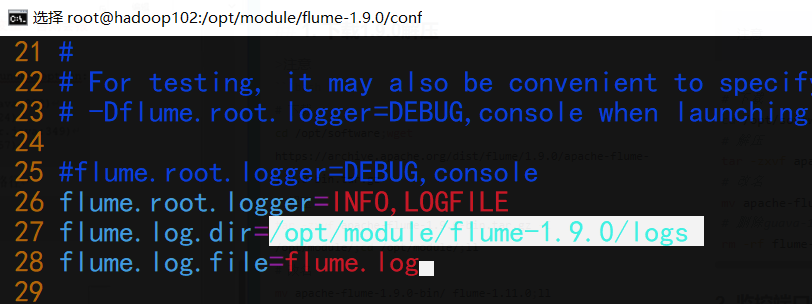
# 修改文件,如下图
cd ../conf; vim log4j.properties
mv flume-env.sh.template flume-env.sh
vim flume-env.sh

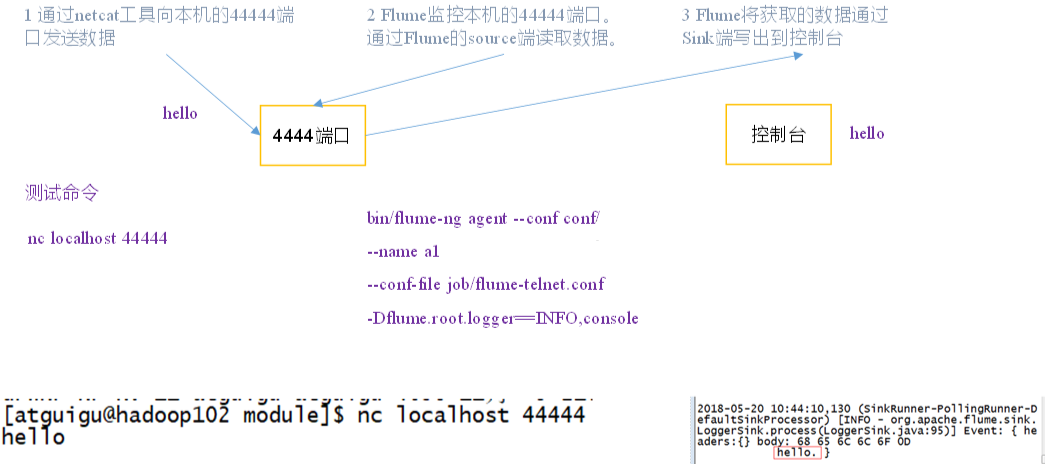
2. 监控端口数据官方案例
🍠案例详情如下图:
# 安装netcat工具
yum install -y nc
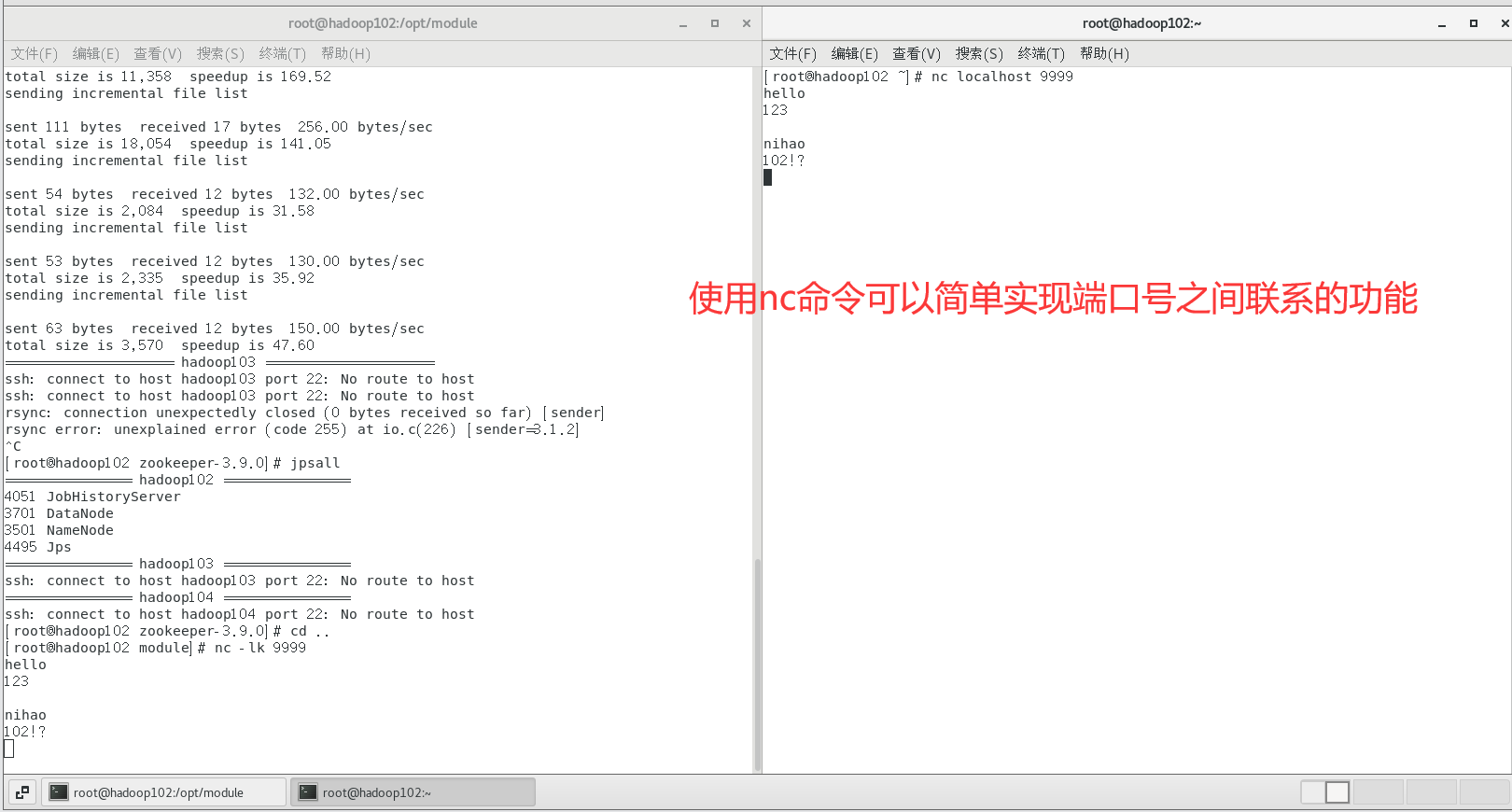
# 轻量的通讯工具,使用nc命令开启服务端
nc -lk 9999
# 再开一个终端开客户端,即可实现通讯
nc localhost 9999
netstat命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息
| netstat [选项] | 描述 |
|---|---|
| -t / –tcp | 显示TCP传输协议的连线状况 |
| -u / –udp | 显示UDP传输协议的连线状况 |
| -n / –numeric | 直接使用ip地址,而不通过域名服务器 |
| -l / –listening | 显示监控中的服务器的Socket |
| -p / –programs | 显示正在使用Socket的程序识别码(PID)和程序名称 |
# 判断44444端口是否被占用
netstat -tunlp | grep 44444
# 创建Flume Agent配置文件flume-netcat-logger.conf(flume目录下)
mkdir job;cd job;vim flume-netcat-logger.conf
🍠添加以下内容:
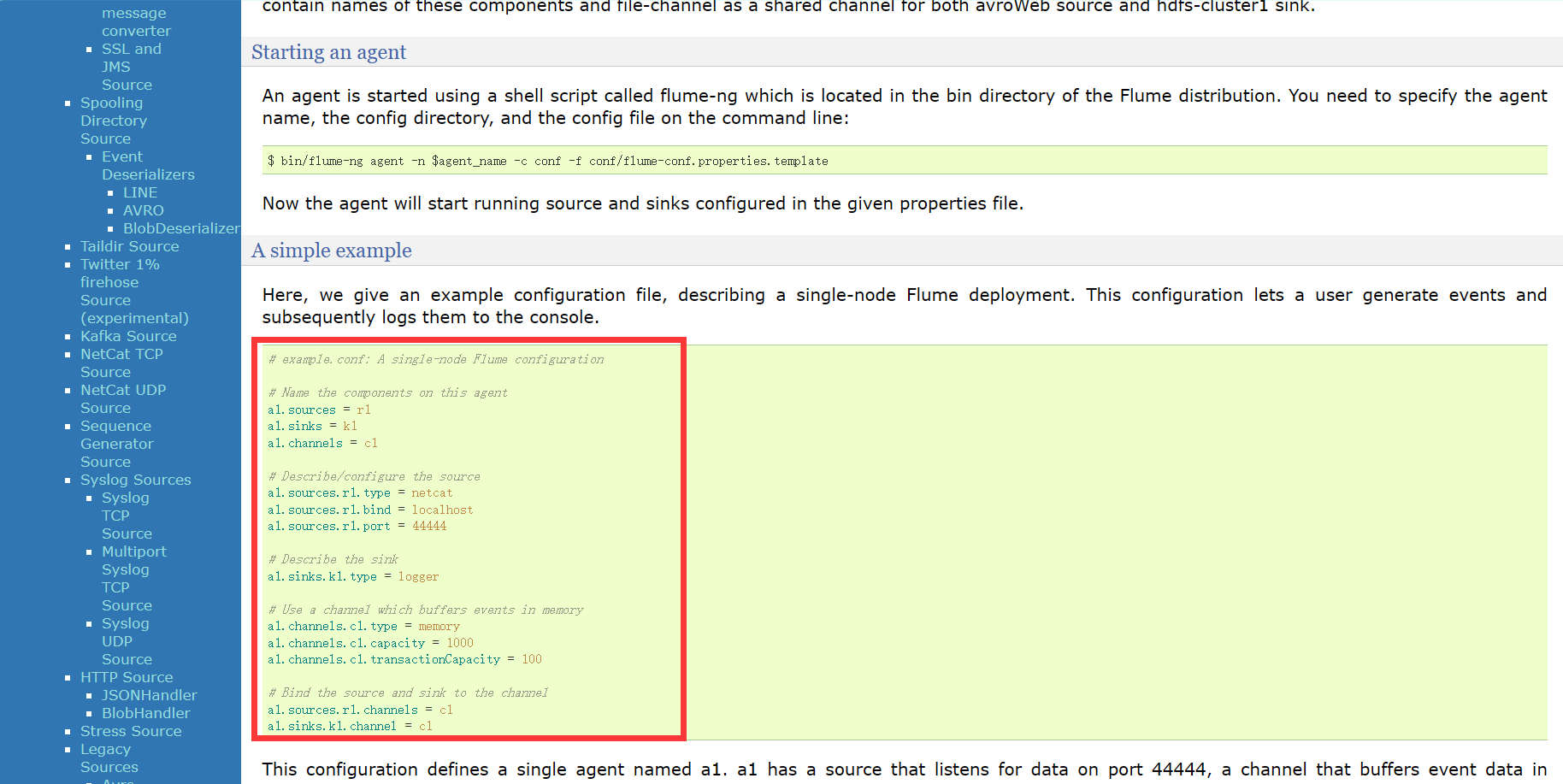
# Name the components on this agent(a1)
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

# 开启flume监听端口
bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
# 使用netcat工具向本机的44444端口发送内容
nc localhost 44444
🤯如果你也报错,slf4j冲突!(hive也有这个问题出现过)

💡解决方案:

参数说明:
1️⃣–conf conf/:表示配置文件存储在conf/目录
2️⃣–name a1:表示给agent起名为a1
3️⃣–conf-file job/flume-netcat.conf:flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件。
4️⃣-Dflume.root.logger==INFO,console:-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error

3. 实时读取本地文件(hive.log)到HDFS案例
实时监控Hive日志,并上传到HDFS中(先启动Hdfs)

# 检查Hadoop、java环境变量/etc/profile.d/my_env.sh是否配置正确
# 创建job/flume-file-hdfs.conf文件
cd job;vim flume-file-hdfs.conf
# ===============添加如下内容=====================
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
# 端口号一定要和core-site.xml配置的相同
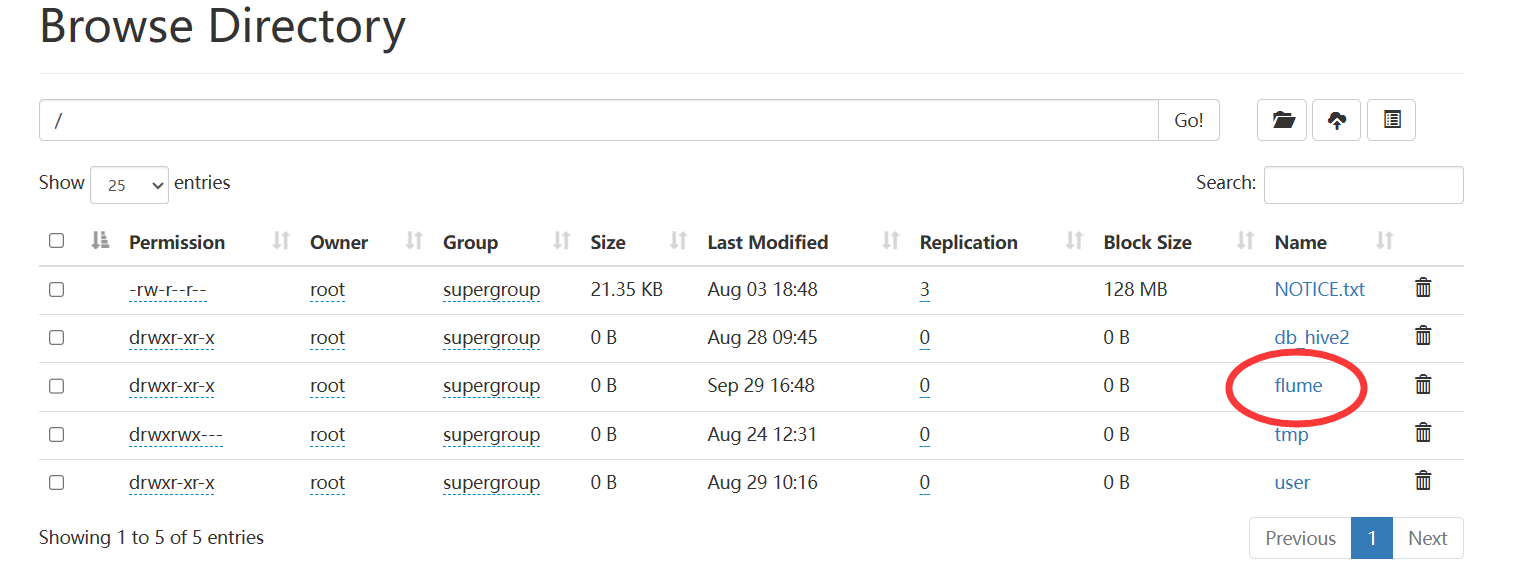
a2.sinks.k2.hdfs.path = hdfs://hadoop102:8020/flume/%Y%m%d/%H
# 上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
# 是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
# 多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
# 重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
# 是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
# 积攒多少个Event才flush到HDFS一次(设置1000会报错,不能超过transactionCapacity的值,否则hdfs不给出现flume目录)
a2.sinks.k2.hdfs.batchSize = 100
# 设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
# 多久生成一个新的文件(生产环境下3600s0)
a2.sinks.k2.hdfs.rollInterval = 60
# 设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
# 文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2

# 执行语句后即可监听
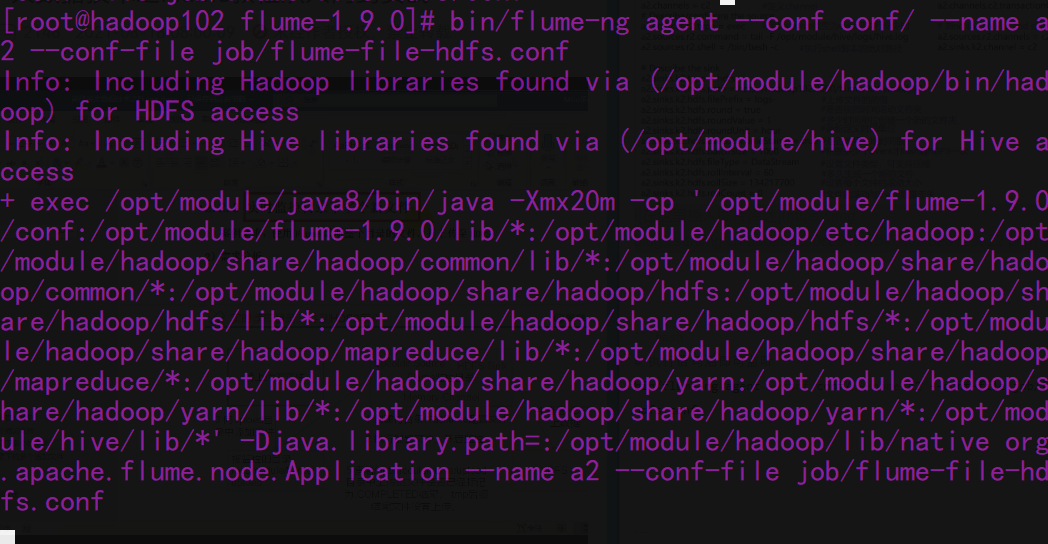
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf
4. 实时读取目录文件到HDFS案例
使用Flume监听整个目录的文件,并上传到hdfs
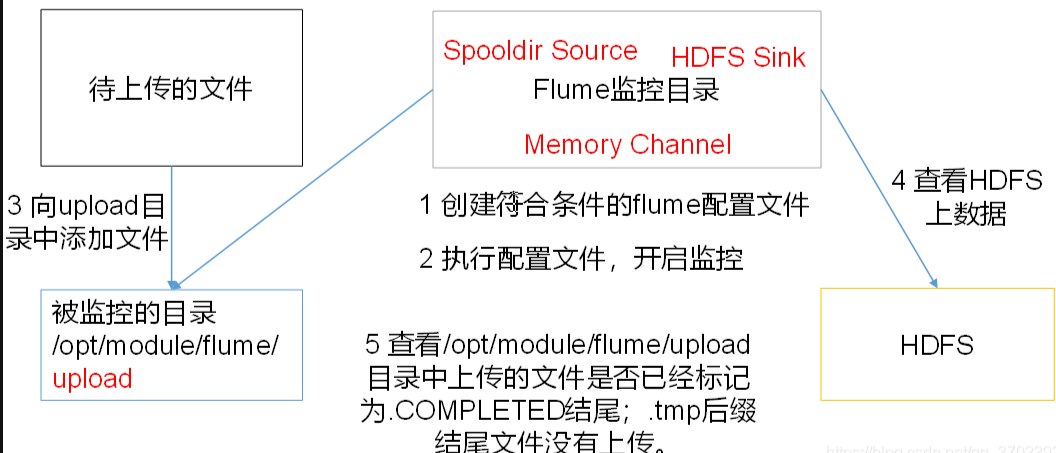
# 创建配置文件及监视目录
vim job/flume-dir-hdfs.conf
mkdir upload
# ===============添加如下内容=====================
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume-1.9.0/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp(以及.COMPLETED)结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop102:8020/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
# 是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
# 多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
# 重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
# 是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
# 积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
# 设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
# 多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3

bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf

不要传同一个名字的文件,不要在监控目录中创建并持续修改文件
5. 实时监控目录下多个追加文件
Exec source适用于监控一个实时追加的文件,不能实现断点续传;Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;而Taidir Source适合用于监听多个实时追加的文件,并且能够实现断点续传
🍠案例详情如下图:
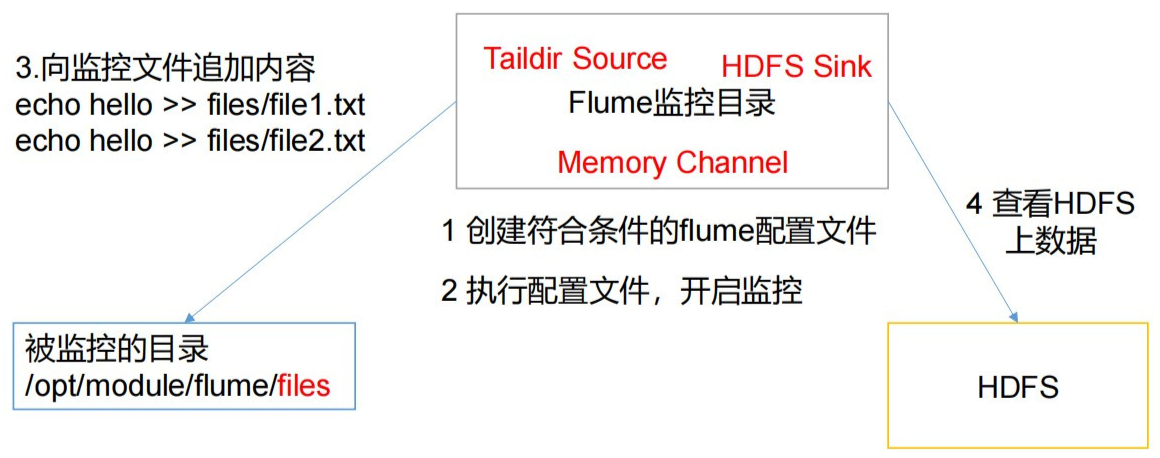
# 创建配置文件
vim job/flume-taildir-hdfs.conf
mkdir files files2
touch tail_dir.json
# ===============添加如下内容=====================
a3.sources = r3
a3.sinks = k3
a3.channels = c3
#configure the source
a3.sources.r3.type = TAILDIR
a3.sources.r3.positionFile = /opt/module/flume-1.9.0 /tail_dir.json
a3.sources.r3.filegroups = f1 f2
a3.sources.r3.filegroups.f1 = /opt/module/flume-1.9.0/files/.*file.*
a3.sources.r3.filegroups.f2 = /opt/module/flume-1.9.0/files2/.*log.*
#configure the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop102:8020/flume/test2/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = test-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
#configure the channel
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3

bin/flume-ng agent --name a3 --conf conf/ --conf-file job/flume-taildir-hdfs.conf
# 创建文本后在hdfs中查看实时改变的文本,超过一定时间后在hdfs后另外生成一个文件
cd files;vim file1.txt
echo hello > file1.txt
mv file1.txt file2.txt
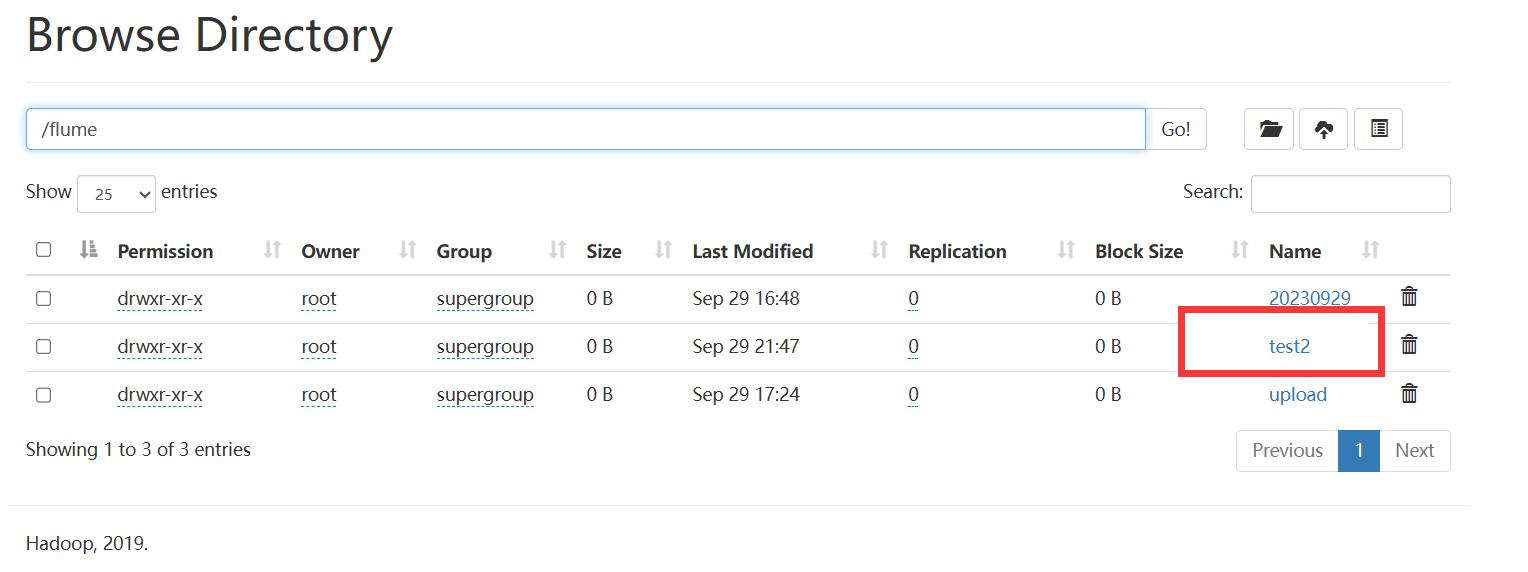

源码中通过
inode值以及file目录地址名来确定文件是否是同一文件,flume配置修改无法解决需求,那就修改源码更改判断逻辑,使数据合理易采集
三、flume-1.10.1版本安装及配置
1.1 Flume安装部署
1.1.1 安装地址
(1) Flume官网地址:http://flume.apache.org/
(2)文档查看地址:http://flume.apache.org/FlumeUserGuide.html
(3)下载地址:http://archive.apache.org/dist/flume/
1.1.2 安装部署
(1)将apache-flume-1.10.1-bin.tar.gz上传到linux的/opt/software目录下
(2)解压apache-flume-1.10.1-bin.tar.gz到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxf /opt/software/apache-flume-1.10.1-bin.tar.gz -C /opt/module/
(3)修改apache-flume-1.10.1-bin的名称为flume
[atguigu@hadoop102 module]$ mv /opt/module/apache-flume-1.10.1-bin /opt/module/flume
(4)修改conf目录下的log4j2.xml配置文件,配置日志文件路径
[atguigu@hadoop102 conf]$ vim log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<Configuration status="ERROR">
<Properties>
<Property name="LOG_DIR">/opt/module/flume/log</Property>
</Properties>
<Appenders>
<Console name="Console" target="SYSTEM_ERR">
<PatternLayout pattern="%d (%t) [%p - %l] %m%n" />
</Console>
<RollingFile name="LogFile" fileName="${LOG_DIR}/flume.log" filePattern="${LOG_DIR}/archive/flume.log.%d{yyyyMMdd}-%i">
<PatternLayout pattern="%d{dd MMM yyyy HH:mm:ss,SSS} %-5p [%t] (%C.%M:%L) %equals{%x}{[]}{} - %m%n" />
<Policies>
<!-- Roll every night at midnight or when the file reaches 100MB -->
<SizeBasedTriggeringPolicy size="100 MB"/>
<CronTriggeringPolicy schedule="0 0 0 * * ?"/>
</Policies>
<DefaultRolloverStrategy min="1" max="20">
<Delete basePath="${LOG_DIR}/archive">
<!-- Nested conditions: the inner condition is only evaluated on files for which the outer conditions are true. -->
<IfFileName glob="flume.log.*">
<!-- Only allow 1 GB of files to accumulate -->
<IfAccumulatedFileSize exceeds="1 GB"/>
</IfFileName>
</Delete>
</DefaultRolloverStrategy>
</RollingFile>
</Appenders>
<Loggers>
<Logger name="org.apache.flume.lifecycle" level="info"/>
<Logger name="org.jboss" level="WARN"/>
<Logger name="org.apache.avro.ipc.netty.NettyTransceiver" level="WARN"/>
<Logger name="org.apache.hadoop" level="INFO"/>
<Logger name="org.apache.hadoop.hive" level="ERROR"/>
# 引入控制台输出,方便学习查看日志
<Root level="INFO">
<AppenderRef ref="LogFile" />
<AppenderRef ref="Console" />
</Root>
</Loggers>
</Configuration>
总结
✍出bug多看看flume目录下的flume`.log文件查看错误信息,问问al轻松解决!
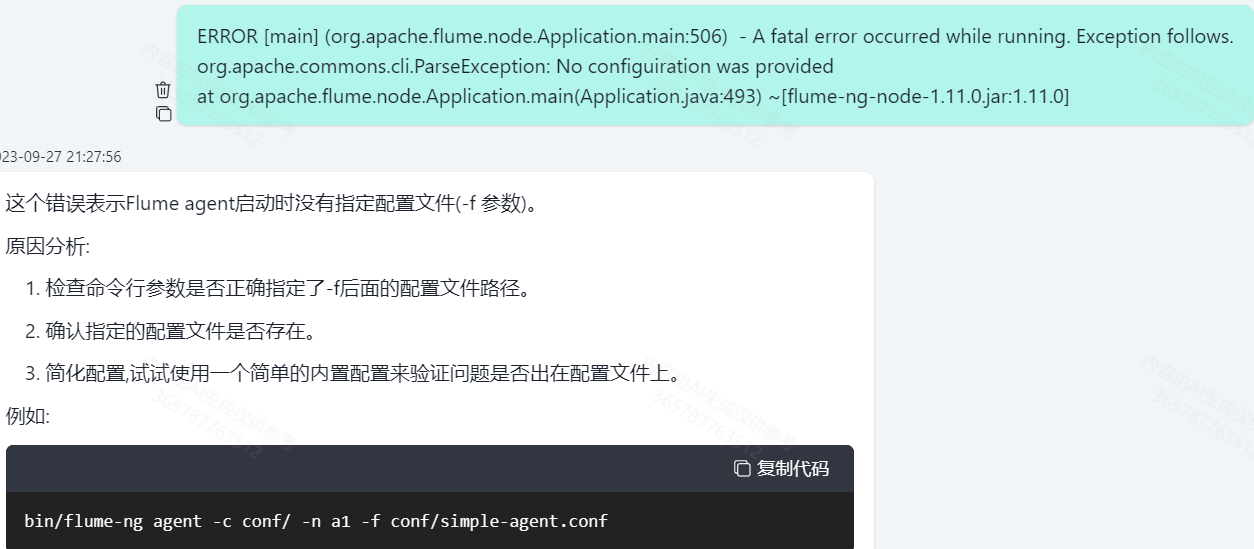
👇罪魁祸首(-f)!

✍Flume日志数据采集:Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
Flume可以采集文件,socket数据包、文件、文件夹、kafka等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中
一般的采集需求,通过对flume的简单配置即可实现
Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
✍flume不同source介绍:
-
Exce Source:这个source的功能是可以使用一条Linux命令,来动态获取一个文件中的数据。
适用场景:适用于监控一个实时追加的文件
缺点:不能实现断点续传(宣告了不使用它) -
Spooling Directory Source:这个source的功能是可以动态的监听一个目录,如果目录中产生新的文件,就会将新的文件进行采集,被采集的文件会被打上一个标记,之后文件再发生变化时不会再进行同步。
适用场景:适用于会产生多个文件的情况,且文件后续不会再发生变化
缺点:不适合实时追加文件的监听 -
TailDir Source(用的多)
这个source可以实时监控一批文件,并记录每个文件的最新的消费问题,宕机重启后不会有重复消费问题。
适用场景:监控多个数据源,可以是目录,可以是文件,每个数据源中的每个文件都可以动态变化。且可以实现断点续传,不会出现重复消费问题。
其中,taildir_position.json这个文件保证了不会出现重复采集的功能。 -
avro Source
这个source主要用于网络协议,监听端口,实现采集端口的数据 -
kafka Source
这个source主要用于输入源是Kafka的情况 -
现在一般情况下,除去一些特殊的输入源,一般都使用TailDir Source这个类型
✍下一节,flume事务!















 1698
1698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









