






数据简介
官网
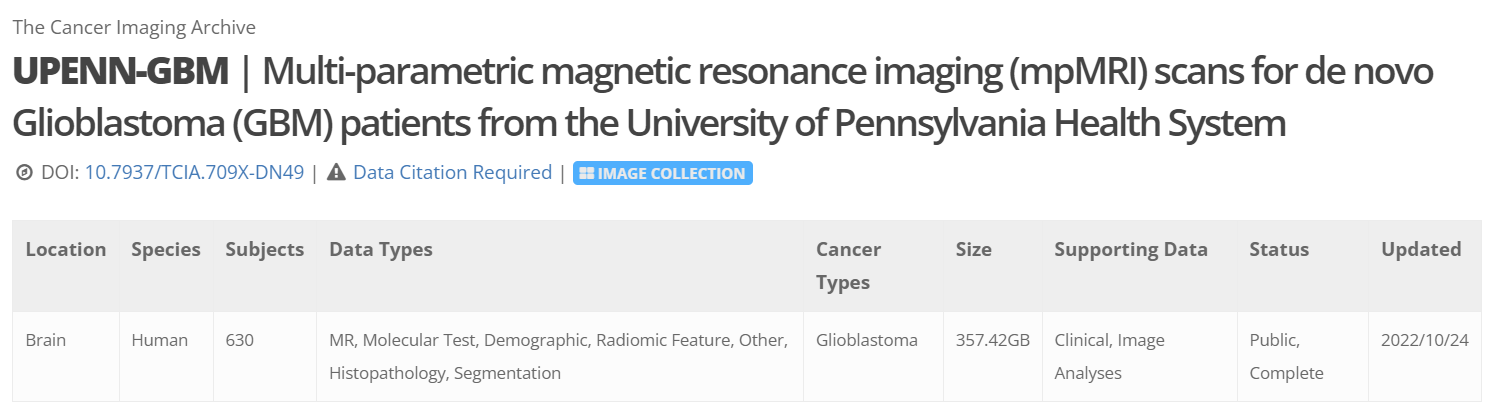
该数据集包含来自宾夕法尼亚大学的胶质母细胞瘤(GBM)患者的多参数磁共振成像(mpMRI)扫描,结合患者的人口统计信息、临床结果(例如,总生存期、基因组信息、肿瘤进展),以及多个组织学上不同的肿瘤亚区域的计算机辅助和手动修正的分割标签、整个大脑的计算机辅助和手动修正的分割、丰富的放射组学特征以及其对应的NIfTI格式。数据为DICOM格式,3D数据,颅骨在原始DICOM数据中保留,没有去除。每个病人的数据中包含了T1加权,T2加权,T1加权对比度增强和T2 FLAIR四种图像数据。有些病人的四种数据并不完整,缺失部分数据。T1加权3D数据大约300左右,T2加权数据大约100左右,T2-FLAIR 数据大约100个。
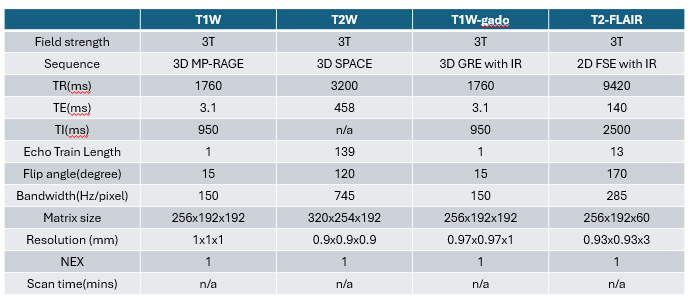
数据采集 protocol(dicom header)
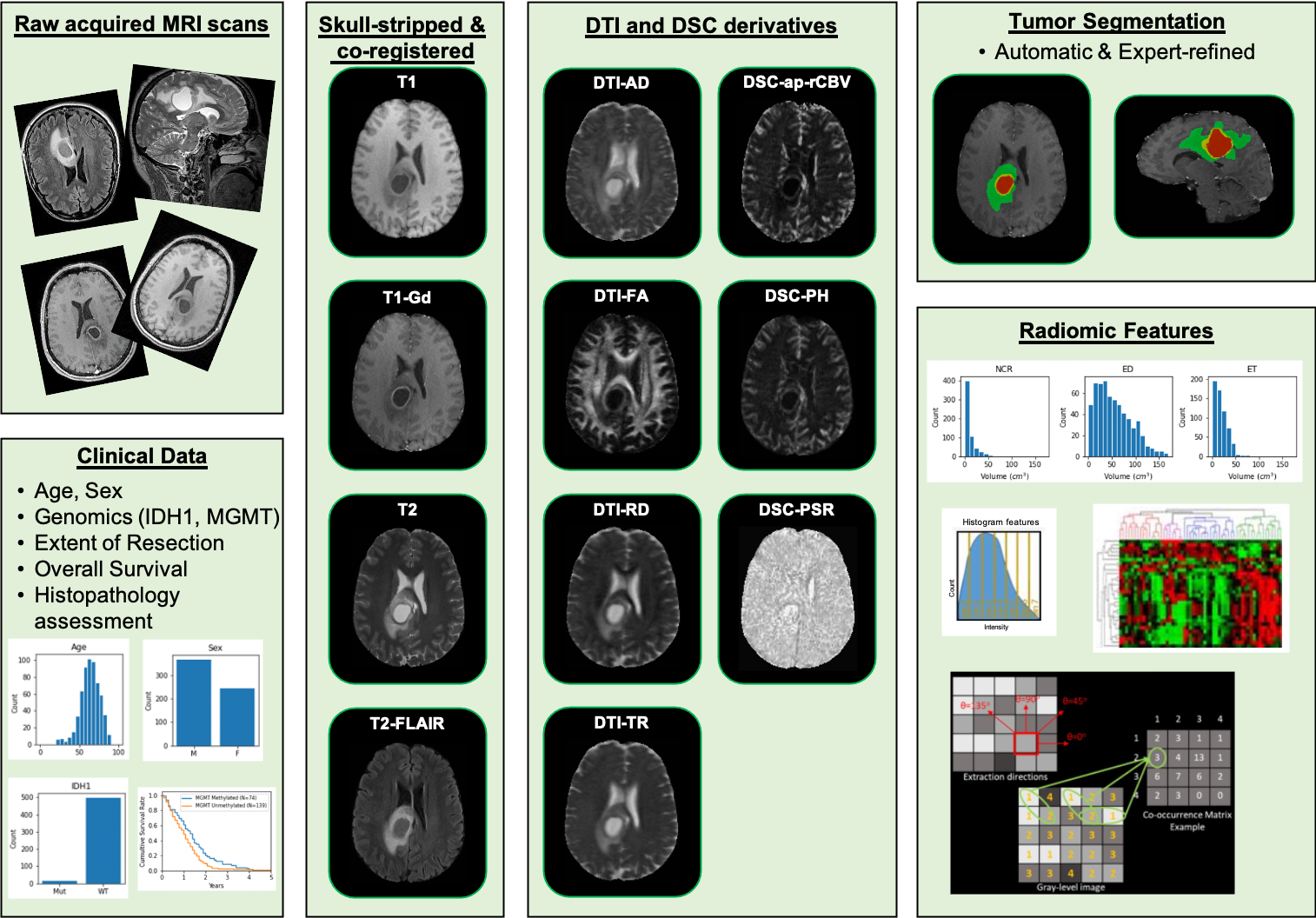
数据样本可视化
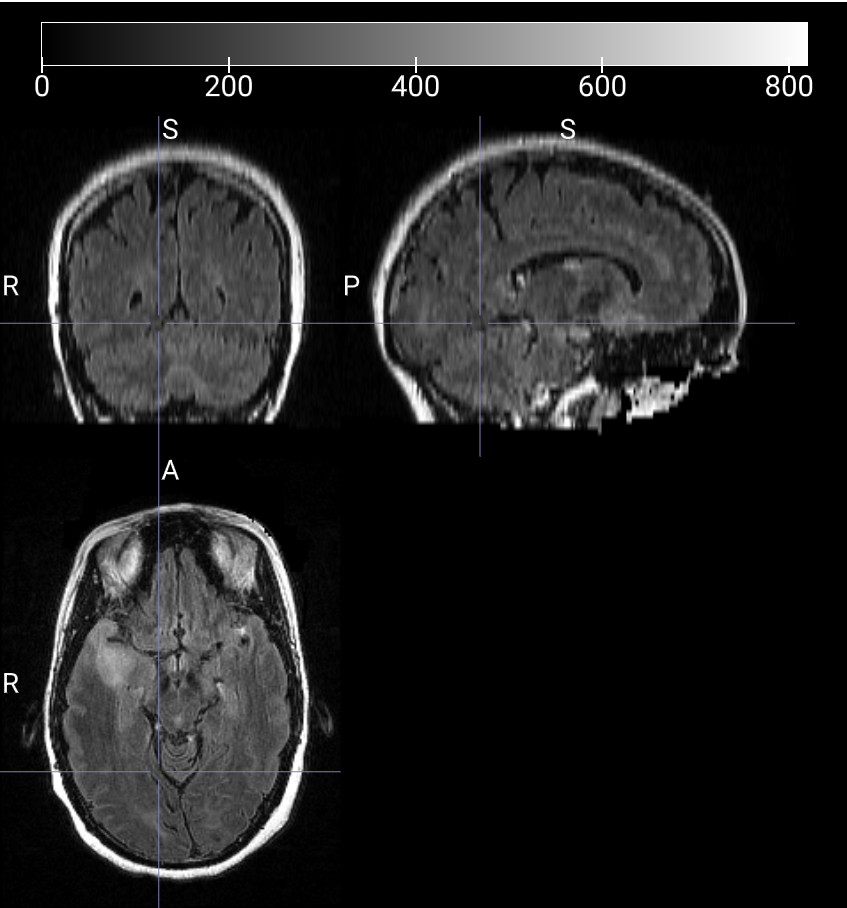
T1W 3D 图像
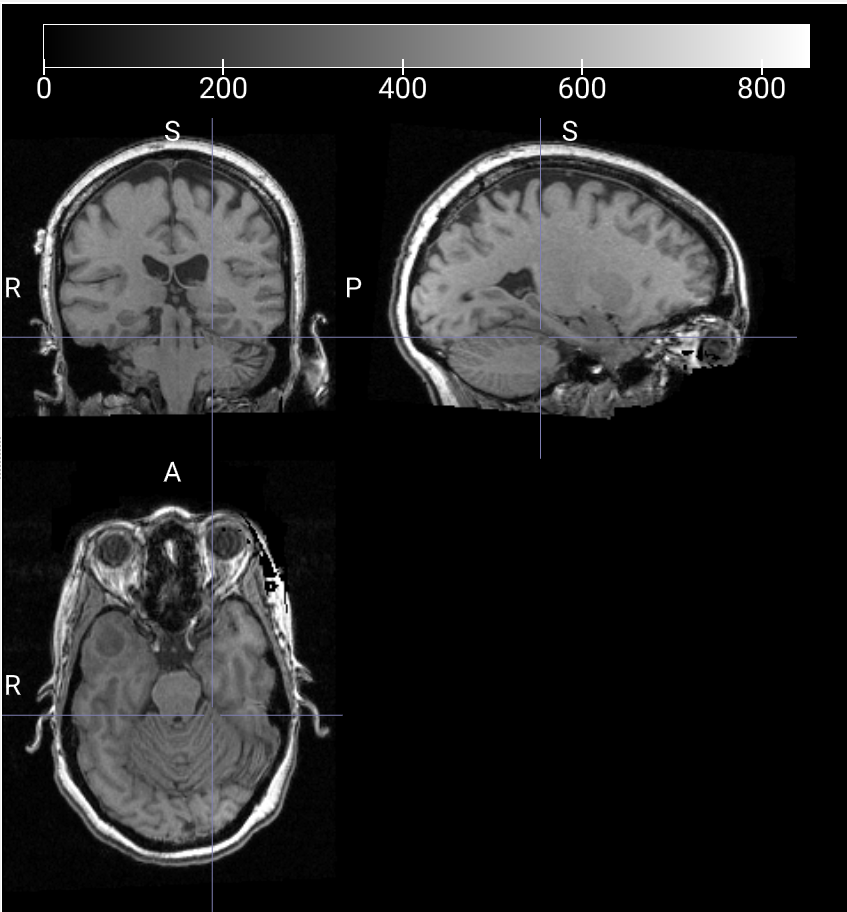
T1W 3D 对比度增强图像
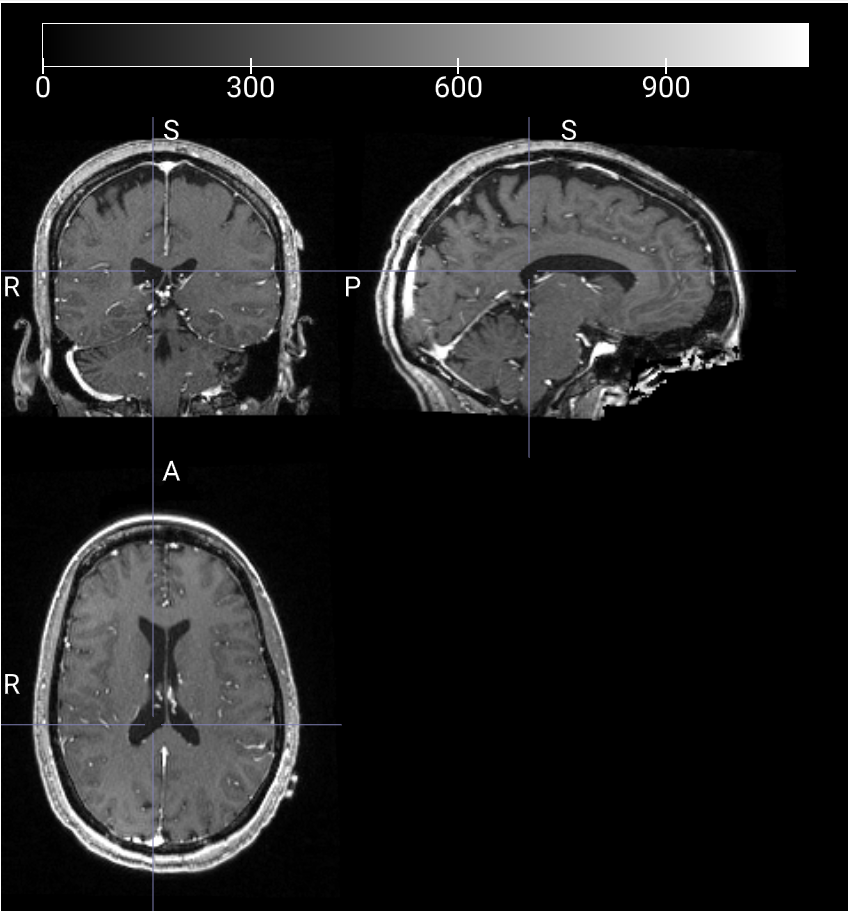
T2W 3D 图像
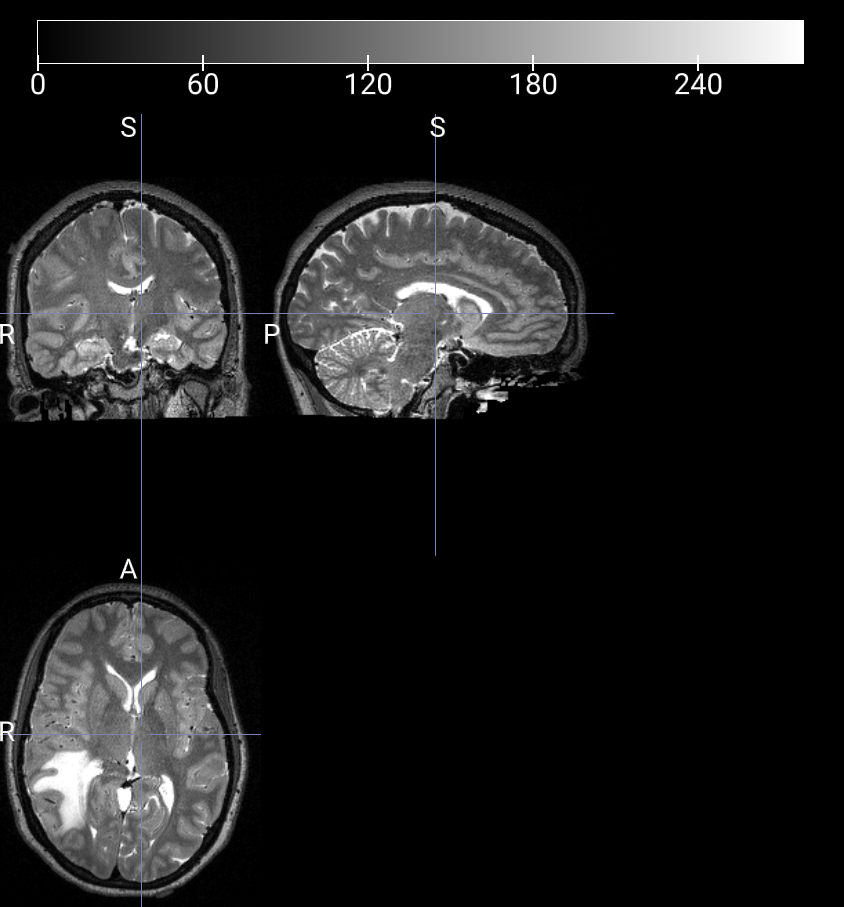
T2-FLAIR 2D 图像
参考文献
Bakas, S., Sako, C., Akbari, H., Bilello, M., Sotiras, A., Shukla, G., Rudie, J. D., Flores Santamaria, N., Fathi Kazerooni, A., Pati, S., Rathore, S., Mamourian, E., Ha, S. M., Parker, W., Doshi, J., Baid, U., Bergman, M., Binder, Z. A., Verma, R., … Davatzikos, C. (2021). Multi-parametric magnetic resonance imaging (mpMRI) scans for de novo Glioblastoma (GBM) patients from the University of Pennsylvania Health System (UPENN-GBM) (Version 2) [Data set]. The Cancer Imaging Archive. UPENN-GBM - The Cancer Imaging Archive (TCIA)


















 96
96

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











