







6个元字符:. * [ \ ^ $
第一个例子:
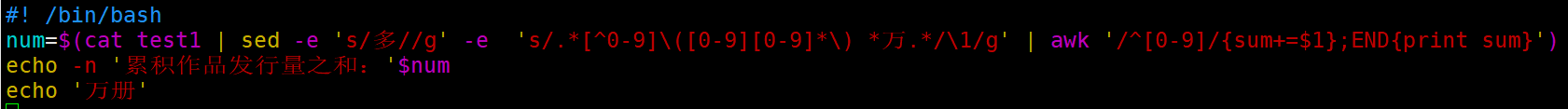
cat test1 先连接文件,并通过管道输出,后面的命令用来筛选
sed(stream editor)是一种流编辑器
选项-e:以选项中的指定后面的script来处理输入的文本文件
s/多//g 将‘多’字替换成空,也就是去掉‘多’字
后面的g表示global,全局替换,把一行所有需要替换的都替换了
无g – 只替代每行第一个
s/.*[^0-9]\([0-9][0-9]*\) *万.*/\1/g
表达式 .* 就是单个字符匹配任意次,就是匹配任何内容
[^0-9]表示非数字
\1 表示将前面/和/之间的内容替换成\)和\)之间的内容
可以看一个例子理解一下:

这条指令大概就是在一行中找到‘万’前面的数字,并提取,‘万’前面有空格就忽略
第二个例子:

tr ‘;:,.?-"()\047’ ’ ’ 将一些符号替换成空格
单引号’用八进制\047表示是考虑到这些符号是放在一对单引号里的,直接用单引号会有错误
tr ’ ’ ‘\012’ 将空格换成换行符
grep 命令用于查找符合条件的字符串
-v选项 : 显示不包含匹配文本的所有行
grep -v ‘^ *$’ 表示消去所有空行
sort 默认按照字符的ASCII值升序排序
具体点说:sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出
-r选项是降序
-n选项是按照数值排序
uniq 用来筛选文中的重复行
-c选项:将相同的项合并并且计数同样的行出现的次数
tail用于显示文件尾部的内容
-n Number 显示最后Number行
















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











