







 本文详细分析了使用MapReduce实现WordCount的步骤,包括创建Maven项目,编写MyMapper类,以及重写map函数。在map函数中,读取1.txt文件的每一行,将单词拆分并映射输出。通过继承Mapper类,实现了分布式并行处理的功能,使用Hadoop的序列化处理,确保数据在集群间传输。
本文详细分析了使用MapReduce实现WordCount的步骤,包括创建Maven项目,编写MyMapper类,以及重写map函数。在map函数中,读取1.txt文件的每一行,将单词拆分并映射输出。通过继承Mapper类,实现了分布式并行处理的功能,使用Hadoop的序列化处理,确保数据在集群间传输。
由上篇blog可知,Mapreduce架构处理问题过程中,需要map()函数和reduce()函数即可同时再添加驱动程序进行实现,本文根据老师上课所讲,对WordCount实例进行分析整理,为学习笔记,有不对的地方欢迎指正。
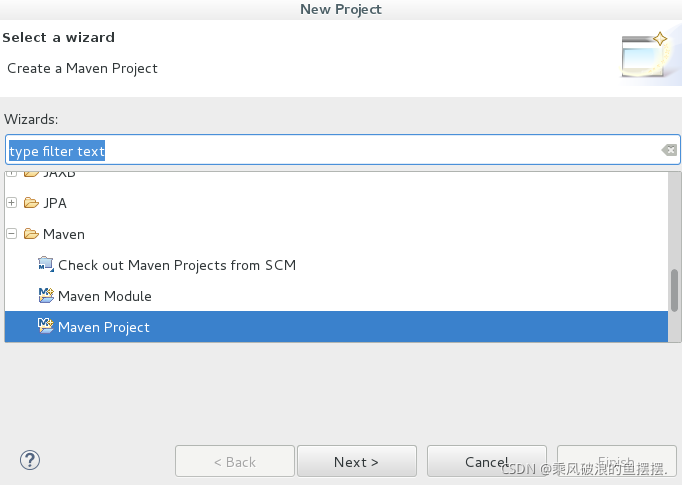
1.创建Maven项目
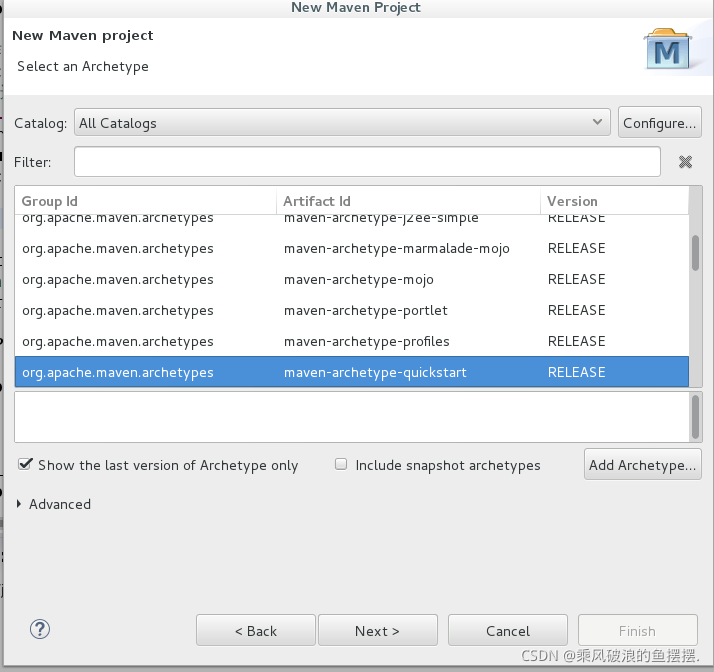
首先通过右键new-project-Maven-Maven Project(如下图所示),之后一直执行Next,进行骨架选择,选择maven-archetype-quickstart骨架,之后并进行命名,本项目命名为hadoop01,并在src/main/java下建立package名为com.qst.test。之后在其下创建MyMapper类。
2.MyMapper类
(1)map函数功能
写map函数将1.txt文件中的每一行文本读取出来,针对每一行将单词拆分&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2524
2524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









