






前言
做了多年技术之后,技术更新换代太快,从我入行时候从单体架构到后面分布式SOA,再到微服务,从后端再到全栈。期间涉及的技术一大堆,有的仍然在用,有的却已经沉没在历史的海洋里了。不过这么多年数据库常用的还是那几种,对于未来的AI时代,可能会有变革,但是数据依然是一切的基础,所以学好数据库还是很重要的。既然行业很卷,人心都很浮躁,那就专注的学学数据库吧,从了解数据库结构开始到应用再到优化,最后再利用对数据库的了解,学会数据分析,或许也不失为一条走向商业的路。 这一篇就来给大家聊聊MySQL的逻辑结构。
一、一条查询的SQL是如何执行的
大家经常见到这样的SQL:
SELECT * FROM Table WHERE ID = 11;
我们只是输入了一个SQL,看到的也只是返回的一个结果。却不知道他在MySQL内部运行的过程。
所以我们今天要把这个SQL拆解一下,看看MySQL到底为这条查询语句做了什么事情。这样当我们遇到MySQL异常或者问题时,就能直戳本质,更快的定位解决问题。
为此我画了一个MySQL的结构思维导图:
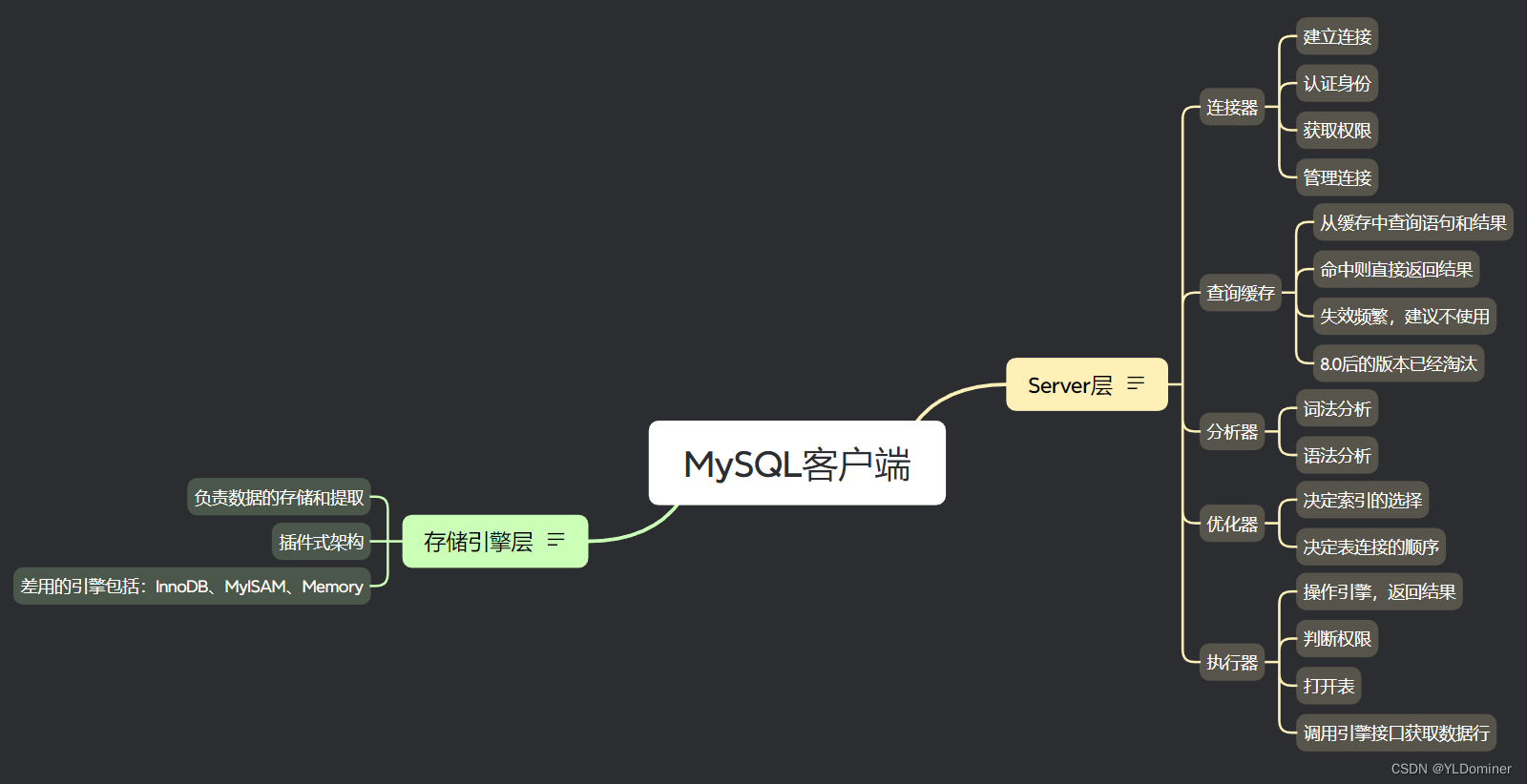
我们平时用的就是MySQL客户端,它可以分为Server层和存储引擎层两部分。
Server层包括连接器、查询缓存、优化器、执行器等。除此之外还涵盖了内置函数(日期、时间、数学和加密函数等),还有存储过程、触发器、视图都在这一层实现。
存储引擎则主要是负责数据的存储和提取。是插件式的架构,支持各InnoDB、MyISAM、Memory 等多个存储引擎。其中5.5.5版本之后InnoDB就成为了默认引擎。
前文所述的SQL是一条查询语句,自然而然的也会经过我们上述的各个“零件”。下面就给大家讲讲每个“零件”在查询过程中提供了什么服务。
二、MySQL的“零件”们
1.连接器
在Linux上或者Windows的cmd上操作过的朋友肯定熟悉这个命令:
mysql -h$ip -P$port -u$user -p
这个是连接MySQL数据库的命令,按照这个命令输入用户名密码。连接器就是负责跟客户端建立连接、获取权限、维持和管理连接。
2.查询缓存
建立完连接之后,就开始执行SELECT语句了。这时候就回来到查询缓存。
MySQL收到查询请求之后,会到查询缓存中找,看看是否执行过这个语句。之前执行过的语句会被当做key-value的键值对形式缓存在内存中。key是查询语句,value是返回的结果。如果在缓存中找到了这个key,就会直接返回value。熟悉java里map的小伙伴应该挺熟悉这个缓存原理。
如果缓存中没有这个key,就会继续后面的阶段。执行完成后会再把结果存入查询缓存中。
但是查询缓存的失效非常的频繁,只要有一个表更新,相关的所有查询缓存都会清空。
注:MySQL8.0版本后就没有这个功能了。
3.分析器
如果没有在查询缓存中找到对应的value。那么sql就会来到分析器中。MySQL需要先分析你这条SQL想要做什么,知道你的需求才能为你实现。
而分析器会先做“词法分析”,识别SQL里的字符串分别代表什么,把字符串“Table”识别为表名,把“ID”识别为列名是“ID”的那一列。
识别完了词法,接下来会识别“语法”。会根据你的SQL语句与MySQL的语法规则进行对比,如果不满足语法规则,就会得到下面的错误提醒。
“You have an error in your SQL syntax”
4.优化器
分析完了你想利用MySQL做什么,便会在执行你的需求之前进行前置的处理。
优化器会负责评估多种可能的执行计划,并选择最优的一种。它考虑多种因素,如索引的使用、数据的分布、连接操作的顺序等,以确定最有效的查询执行计划。
转换查询:当一个查询被转成另一种查询时,其结果是一样的,这被称为语句转化。例如,查询SELECT … WHERE 5 = a可以被转化成SELECT … WHERE a = 5。
使用索引:为了提高查询效率,是否正确使用了索引是一个关键因素。索引是数据库中用于加速数据*检索的数据结构。优化器会评估使用索引的利弊,并决定是否使用索引。
调整查询计划:优化器还会考虑多种因素,如数据的分布、查询的结构等,以确定最有效的查询执行计划。
5.执行器
当MySQL知道了你需要做什么之后,就会开始执行你的SQL语句。
开始执行的时候,要先判断一下你对这个表有没有执行查询的权限,如果没有,就会返回没有权限的错误。
以最开始的SQL为例
SELECT * FROM Table WHERE ID = 11;
执行流程是这样的:
(1)调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 11,如果不是则跳过,如果是则将这行存在结果集中;
(2)调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
(3)执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。
总结
一条SQL查询语句的执行会经过一系列的流水线。连接器用来关联连接,权限验证。查询缓存提交查询效率。分析器做词法和语法分析。优化器执行计划生成、索引选择。执行器操作引擎返回结果。引擎层则存储数据,提供读写接口。其中每个环节都是比较重要的部分。















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









