






 小米集团在数据智能领域展示了其社会责任感,通过声音识别技术,特别是环境音识别功能,帮助听障用户获取更多信息。文章详细描述了技术开发过程,包括模型训练、MobileNet和ViT的应用,以及无障碍设计的理念和应用效果。
小米集团在数据智能领域展示了其社会责任感,通过声音识别技术,特别是环境音识别功能,帮助听障用户获取更多信息。文章详细描述了技术开发过程,包括模型训练、MobileNet和ViT的应用,以及无障碍设计的理念和应用效果。

小米集团公益案例
本项目案例由小米集团投递并参与数据猿与上海大数据联盟联合推出的 #榜样的力量# 《2023中国数据智能产业最具社会责任感企业》榜单/奖项”评选。

数据智能产业创新服务媒体
——聚焦数智 · 改变商业
一直以来小米秉持着“和用户交朋友,做用户心中最酷的公司”的愿景,努力践行“始终坚持做感动人心、价格厚道的好产品,让全球每个人都能享受科技带来的美好生活”的公司使命。而"全球每个人“包含了不同肤色、信仰、地域、经济程度的所有人都应该拥有日常生活体验的平等,这自然也包括了不同类别、不同程度的障碍者。
小米在创立之初即是国产手机厂商中最早有意识地保留安卓原生Talkback读屏软件的公司之一。而在2013年MIUI论坛上收到了一封来自视障用户的6000多字建议信后,MIUI开始更加注重视障用户的反馈,并在“和用户交朋友”的愿景下,建立障碍用户反馈群,并将信息无障碍做为小米手机出厂的硬性标准。
在我国有超过2700万的听障人士,小米基于长期与障碍用户直接交流需求的积累下,率先关注到听障用户的沟通需求,于2019年率先发布了小米闻声,一款可以实现文字语音互转的系统软件,能够实时的语音和文字转译,对方说的话会实时以文字呈现;当你把想说的话以文字输入,也会直接转换成语音播报。小米闻声解决了听障用户面对面交流需求。然而,生活中除了与人交流以外,环境中各种声音也承载了大量的信息,仅有文本信息是不完整的,也会让人感到不安——比如听障用户在夜间关闭了助听器和耳蜗 ,就无法听见警报声或孩子哭声。
因此,小米推出声音识别功能(环境音识别),可以监测14种重要的环境音,包含火警、婴儿啼哭、 烧水壶声等等,并进行文字通知,让听障用户亦可平等的获取环境中的声音信息。
项目开发起止时间:
开始时间:2021年9月
截止时间:至今
服务周期:服务中
应用场景
小米声音识别功能搭载关注于环境中的非语言信息,目前小米声音识别功能首先搭载于小米手机中,可以监测14种重要的环境音,包含火警、婴儿啼哭、烧水壶声等等,并在手机通知栏进行推送,同时小米手环上也可以同步显示通知,随时随地不怕错过重要信息。
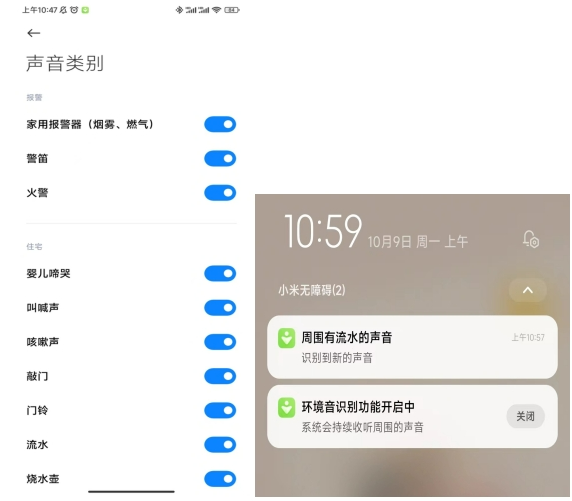
除了手机,亦逐步搭载至更多智能家居设备。例如在米家摄像头上,宝宝哭声监测的功能,就是在检测到宝宝哭声的时候,实时向用户的手机推送通知;Xiaomi Sound音箱近期也上线环境音识别功能,能够识别家用报警器、婴儿啼哭、火警、流水、猫叫、狗叫六种在家居环境下用户关心的声音。
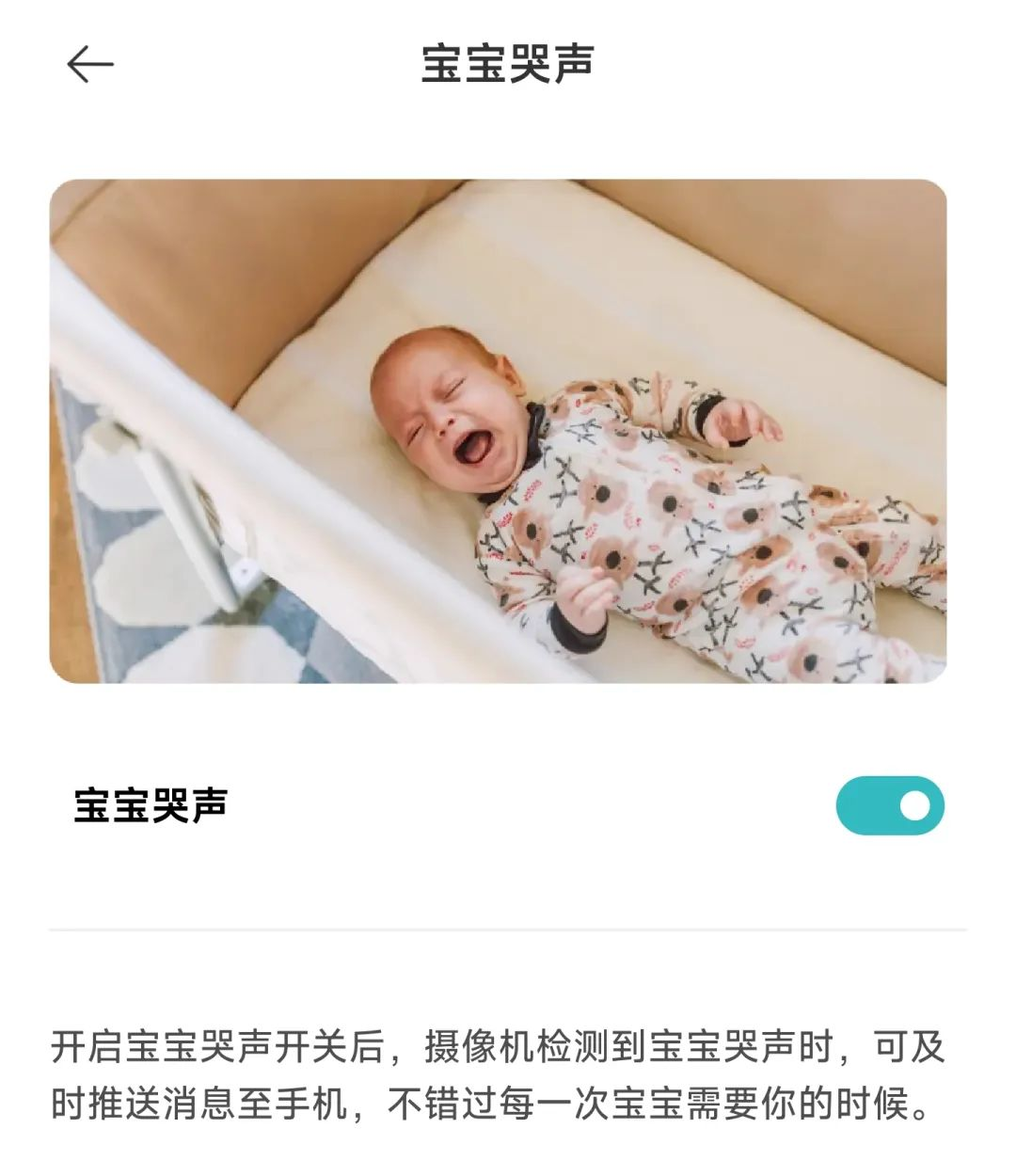
当听障用户在无法、不方面佩戴助听器时,也能“看到”周围的声音情况;与此同时,该功能对于非障碍人群来说,对于年长退化听损、佩戴耳机忽略周遭环境声音时,亦成发挥其辅助与提醒的作用。
面临挑战
首先,数据是声音识别功能开发的重要基础。我们需要大量的数据来训练我们的声音识别模型,并不断改进和优化该功能。由于这是一个新的领域,我们缺乏现成的数据可供参考。获取和整理这些数据是一项庞大而复杂的任务,需要我们投入大量的时间和资源。
其次,技术难度也是这个项目所面临的一个挑战。声音识别是一个涉及到信号处理、机器学习和人工智能等多个领域的复杂技术。我们需要不断地研究和创新,以解决声音识别中的各种难题。这包括了提高识别准确率、降低误识率、提升实时性等方面的技术挑战。我们需要攻克这些技术难关。
此外,无障碍技术不能直接带来经济效益,这也是我们面临的挑战之一。但我们坚信,通过为听障人士 提供无障碍服务,我们能够体现出我们的社会责任,为听觉障碍人士带来福祉,让他们享受到更多的便利和平等的权益。这是我们的社会责任,也是我们始终追求的目标。
技术开发过程
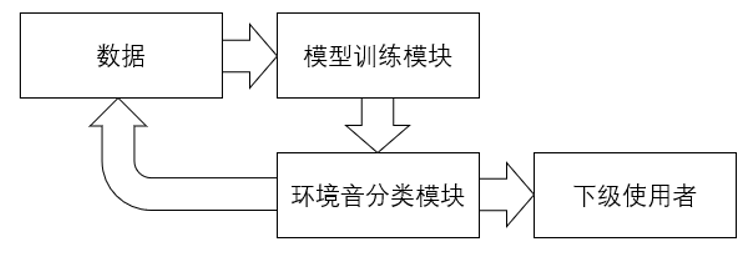
总体结构和模块接口设计
系统整体结构框架如下图所示:
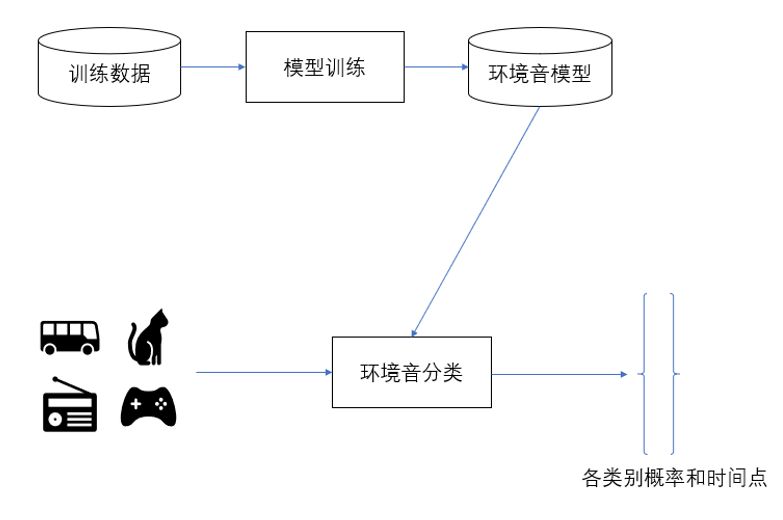
系统整体结构框架图
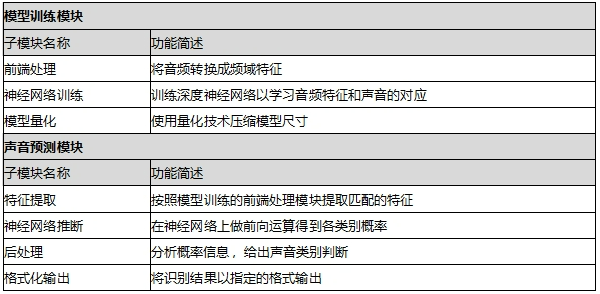
系统的主体模块包括模型训练和声音识别两部分。其中 ,模型训练的结构框图如下:
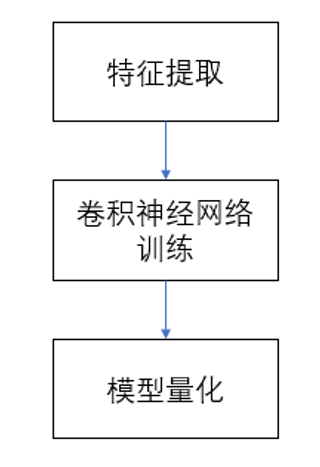
模型训练结构框架图
声音分类的结构框图如下
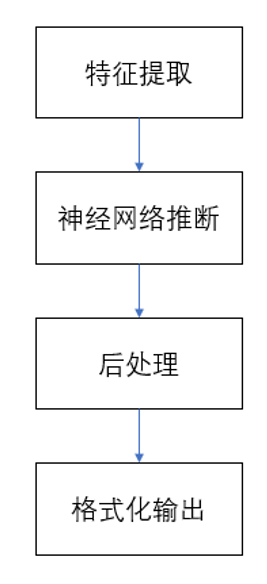
声音分类结构框架图
模块功能逻辑关系
模块内部关系结构如下图所示:
模型训练流程
声音技术的模型训练,通过收集大量的多标签弱监督标注的音频数据,通过提取符合人耳听觉特性的声学特征,经过神经网络模型的训练,完成声学模型的学习。其训练原理如下图所示:
训练原理图
图中提到了多标签和弱监督的概念。这里的多标签含义是,一条音频可以有多个标注标签 ,比如某音频片段标注为Speech、Cat和Music ,表示该音频中存在这三种音频类别。弱监督的含义是 ,不知道某声音类别在该音频片段中具体的时间点信息。
具体地,要训练声音模型,首先要收集大量的多标签弱监督的音频数据,并设计了多达几百类的音频标签种类。在声音训练的时候,将目标音之外的类别设计为filer类别。filer类别的设计,增强了模型的噪声抑制作用,大幅降低了模型的误识别率。
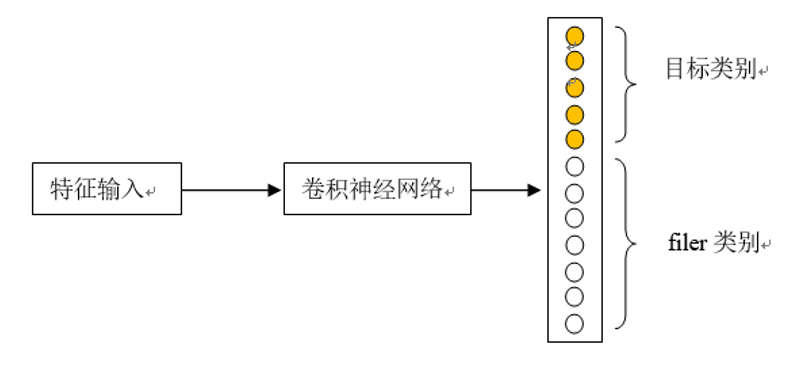
使用filer类别提升模型性能
第二步,利用弱标签数据,采用BCE Loss的训练准则,训练一个大的卷积网络模型作为Teacher模型。第三步,采用Teacher-Student模型蒸馏的方法,利用Teacher大模型学到的知识,指导小模型Student的学习。这样可以使得Student模型在小尺寸时,仍然能够学得充分,从而保持较好的模型性能。
针对移动端的部署需求,即使通过Teacher-Student蒸馏技术,往往也很难达到移动端对模型尺寸的要求。此时,通过模型量化技术,在保证模型性能的前提下,可以进一步压缩模型的尺寸。常用的量化有16bit量化,8bit量化以及混合量化技术等。在声音模型的量化中,主要采用混合量化方式将模型压缩了大约4倍,最终的上线模型尺寸<500k。
测试音频经过模型计算得到每个类别的分数,该分数实际已经表示了某类别发生概率的大小,但直接使用该分数判别模型误识别较大。通常,我们会经过复杂有效的后处理策略,来进一步提升模型的性能。具体的后处理策略如下图所示:
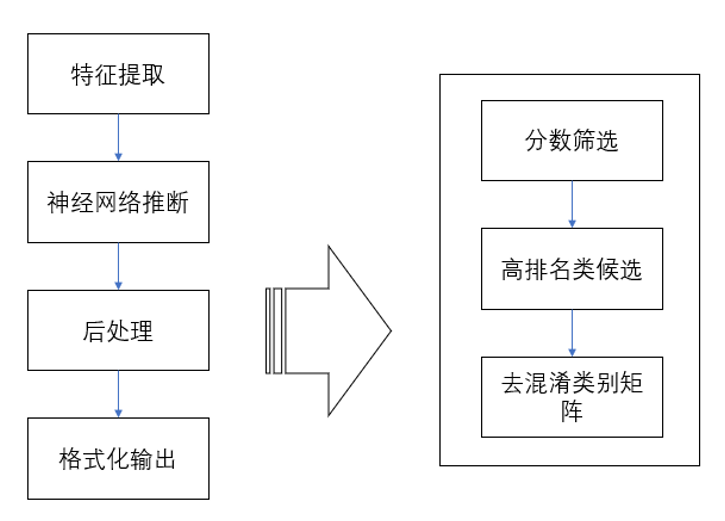
声音识别后处理模块
使用的一些训练技巧
声音识别的模型训练流程通常先要将音频提取fbank等声学特征,用指定时长的声学特征块作为输入,训练分类模型即可。对于声音识别任务,为了得到细粒度的时间点信息,输入时长不能过大。实践中,我们通常训练以两秒为输入时长的模型。
和分类模型大多使用cross-entropy(CE)作为损失函数不同,声音识别模型通常使用binary cross-entropy(BCE)作为损失函数。这是因为各种环境声音的发生并不是互斥的,同一时间可能有多种声音事件发生。
我们使用了如下的一些技术来改进模型训练:
Augmentation
对训练数据做扩增。包括对特征做时频扰动的SpecAug、对不同类型声音进行叠加以创造新数据的mix-up等。
Unsupervised Data Augmentation (UDA)
我们可能是最早将UDA用在声音识别领域的。UDA方法认为一个良好的模型在输入有微小扰动时,输出不应有过大变化,因此在模型训练时把输入有微小扰动后输出的变化加入到损失函数中。
Mean Teacher
这种方法把近几次训练得到的模型的平均作为teacher模型,用该模型去影响后面模型的训练。
Noisy Student
用预训练模型作为teacher来标注弱标签和无标签数据,生成的标签用来训练student模型。在训练student模型时加入一些噪声,包括在输入特征上、在模型参数上和在标签上。根据情况,可以考虑用新训练的student模型替换原teacher模型重新生成标签并重复上述过程。
模型结构
我们使用了两种模型结构 :MobileNet和ViT。
MobileNet将常规的卷积运算用depthwise卷积简化。Depthwise卷积,指每个卷积核都只对单一通道操作,这是计算量降低的关键。为了弥补这种简化导致的通道间信息损失 ,又对depthwise卷积的结果使用若干pointwise卷积,即1x1卷积整合通道间信息,如下图所示。
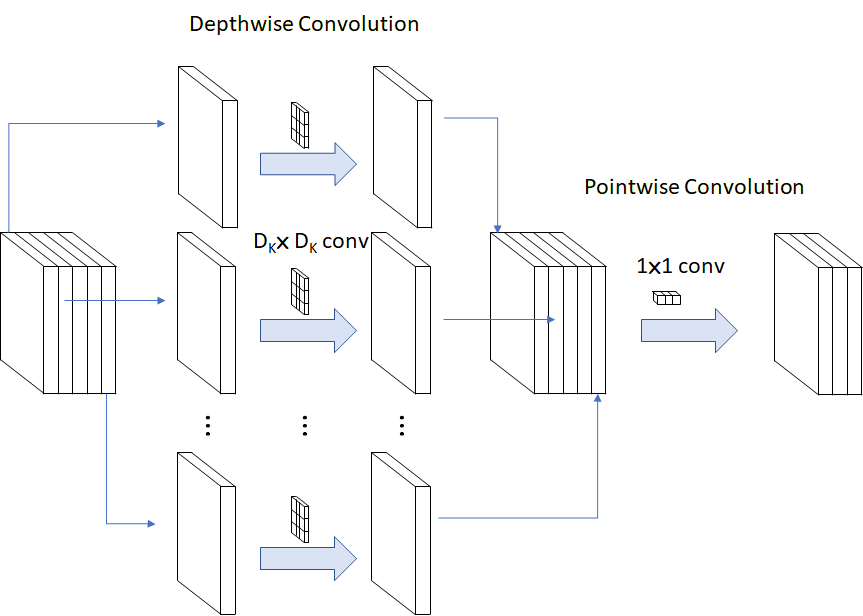
如此操作,计算量可降低到常规CNN的约十分之一。实验结果显示,模型性能和常规CNN相比并没有明显下降。由于MobileNet的低计算量,这种CNN结构非常适合在移动端部署。
在MobileNet提出约一年后,其改进形态MobileNetV2继而被Google提出,并得到了广泛应用至今。正如其论文标题MobileNetV2:InvertedResiduals andLinear Botlenecks所强调的,invert residuals和linear bottlenecks体现了MobileNetV2对前代的改进。MobileNetV2在depthwise卷积前,首先进行1x1卷积以增加通道个数,完成了depthwise卷积后,再合并降低通道个数。一些常见的残差块是先降低通道个数,这里刚好相反,因此把这种结构称为是invert的。多个这样的块串联,就形成了若干bottlenecks,起到了对信息的压缩和提取作用。MobileNetV2比MobileNet的参数量更低,而性能更好。
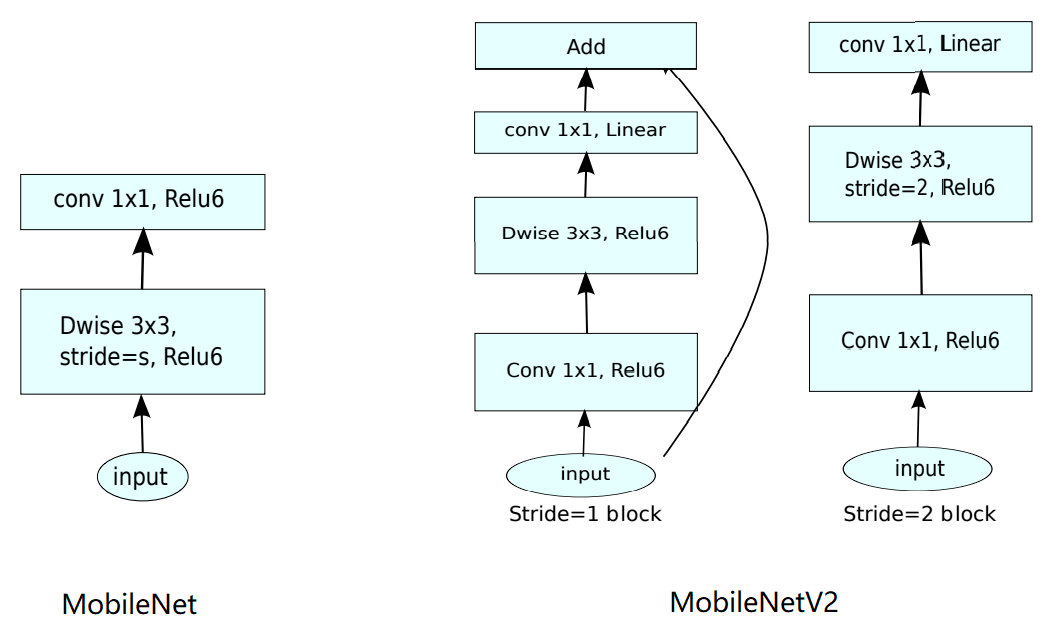
结合神经网络架构搜索(NAS)技术 ,Google进一步发展出了MobileNetV3、EfficientNet等模型结构。这些CNN结构是我们目前的主力模型结构,应用在小米手机、摄像头等各业务线上。
各个领域几乎都能取得更好的效果。尽管transformer最初只用来对序列建模,但Vision Transformer (ViT) 的提出及其优异的性能表现,使ransformer 也成了计算机视觉领域的主流模型结构。
ViT的思路是把图像识别问题转为序列识别问题。算法把固定大小的图片,切成若干小块(patch), patch的尺寸可以是16x16。将patch序列和表征位置的特征顺序送入到transformer encoder中得到编码结果 ,就可以用全连接层识别图像内容了。实验结果表明,相比于Resnet,ViT的性能更好 且模型尺寸更小、计算量更低。Transformer在经过大量数据预训练后表现尤为出色。用比ImageNet大得多的JFT-300M预训练后,ViT在图片分类上的性能可轻松超越基于CNN的模型。
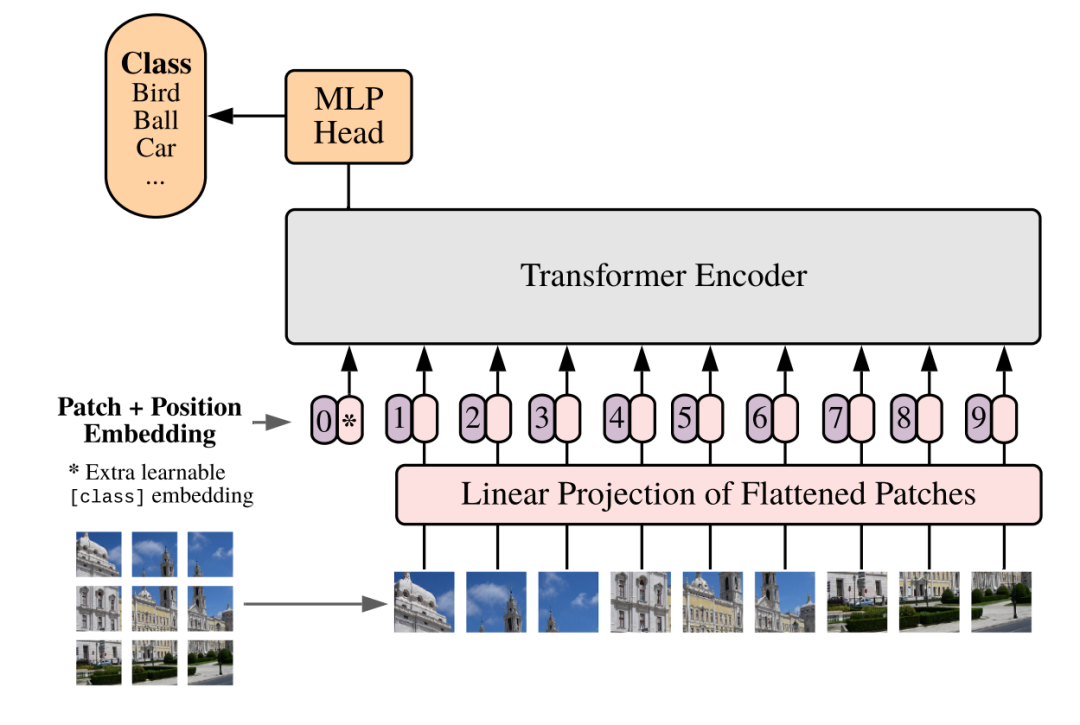
把ViT应用于声音识别是一个自然而然的想法 ,作为一种跨模态(cross-modality)学习方法,ImageNet数据被用作声音识别模型的预训练。由于有开源的用 ImageNet预训练完毕的ViT可直 接使用,基于这些模型进行声音识别的训练是非常方便的。在AudioSet测试集上,AST达到了45.9的mAP ,领先于当时所有基于CNN的方法。
自定声音事件:few-shot检测
允许用户自定义声音事件也会是一个很有用的特性。比如,用户如果把家里老旧洗衣机的完成提示音注册为自定义声音事件,并设置旁边的小爱音箱检测此事件,那么洗衣完成时小爱就可以提醒用户,这就把智能设备的特性引入到了旧的非智能设备中。
Few-shot learning是实现此功能的一个可行途径。其思想可能有些拗口:让模型不只学习如何分类,还要学习如何学习如何分类。不仅授模型以“鱼” ,还要授模型以“渔”。
具体到训练中,对每一次训练迭代,我们从数据集中随机取出比如5类样本,每类2个样本,把这个样本大小为5x2 =10的微型数据集称为本次迭代的support set。再从这个5类中随机选择一类,在数据集中寻找另外的该类样本,称为query。我们训练一个特征提取器,使query的嵌入式特征能够和support set中对应类别的嵌入式特征尽可能接近。如下图所示。

当用户注册一个新的声音事件时,用此特征提取器就可以得到新声音事件的特征向量。通过对比特征向量的距离,就可以判定某事件是否属于这种新注册的声音事件。
应用效果/社会价值
小米声音识别(环境音)功能上线后,受到了广大用户的好评,手机端搭载声音识别的软件日活数亦突破了2W。
随着应用的扩展,小米技术人员亦由此进行更深一步思考发现环境音技术与语音唤醒(KWS)技术的逻辑相当类似,经研究及大量实验发现,声音识别模型与小爱唤醒模型两个模型的合并是完全可行的,这项创新的成果已申请发明专利,并在2022年的语音技术顶会Interspeech上进行了发表。
同时我们也希望借由重新定义无障碍功能,对于障碍者来说,“被照顾”并不是他们真正的需要,如何利用现有技术,让他们享受到平等的人人交互、人机交互的权利,是设计上更应该考虑的课题。而提及无障碍功能,我们常常认为,这些功能只有障碍人士才需要使用。但实际上,日常生活中的每个人,或多或少都会遇到一些“情境性障碍”。试想一下,当我们带上耳机,外界的声音被隔绝时,我们对外界声音的感知被削弱。在驾驶汽车时,我们的双手被方向盘占用,无法继续操作手机。又或者在生病时, 我们因为喉咙肿痛而声音沙哑甚至失声。
所以当我们把“障碍”,拆解成一个个不方便的场景,针对每个场景去设想解决方案,无障碍设计就不只是一个专门为障碍人士设计的功能。而所有设计的开始,该思考的不只是我的产品是给谁用,更应该去思考“这个功能能否让所有人便捷地使用” ,让产品本身更加包容,从使用体验本身上做到无障碍, 真的从可操作的层面实现“让全球每个人都可以享受科技带来的美好生活”。
关于企业
·小米集团
小米集团成立于2010年4月,2018年7月9日在香港交易所主板挂牌上市(1810.HK),是一家以智能 手机、智能硬件和IoT平台为核心的消费电子及智能制造公司。
胸怀“和用户交朋友,做用户心中最酷的公司”的愿景,小米致力于持续创新,不断追求极致的产品服务体验和公司运营效率,努力践行“始终坚持做感动人心、价格厚道的好产品,让全球每个人都能享受科技带来的美好生活”的公司使命。
小米目前是全球领先的智能手机品牌之一,截至2022年底,智能手机全球出货量稳居全球前三,全球MIUI月活跃用户达到5.82亿。同时,小米已经建立起全球领先的消费级AIoT物联网平台,AIoT平台已连接的IoT设备(不包括智能手机及笔记本电脑和平板)数达到5.89亿。集团业务已进入全球逾100个国家和地区。2022年8月,小米集团连续四年进入《财富》“世界500强排行榜 ”(Fortune Global 500) ,位列第266名,是四年来排名上升最快的中国科技公司。点击文末“阅读原文”链接,还可了解更多详情信息。



















 7020
7020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









