







taobao.item_get_app 获得淘宝app商品详情原数据
API功能:通过商品id获取淘宝的商品详情页原数据,天猫商品也可以拿到。
请求参数
请求参数:num_iid=520813250866
参数说明:num_iid:淘宝商品ID
响应示例(部分)
item: {
brandValueId: "1927269016",
businessId: "default",
cartUrl: "https://h5.m.taobao.com/awp/base/cart.htm",
categoryId: "50012453",
commentCount: "0",
countMultiple: [ ],
exParams: [ ],
favcount: "171224",
h5ItemUrl: "https://new.m.taobao.com/detail.htm?id=678264636662&hybrid=true",
h5moduleDescUrl: "//mdetail.tmall.com/templates/pages/itemDesc?id=678264636662",
images: [
"//img.alicdn.com/imgextra/i3/3691886865/O1CN01CJeRJZ20aE18bUJCu_!!3691886865.jpg"
],
itemId: "678264636662",
moduleDescParams: {
f: "desc/icoss3493626717ab12aff0f7bb2462",
id: "678264636662"
},
moduleDescUrl: "//hws.m.taobao.com/d/modulet/v5/WItemMouldDesc.do?id=678264636662&f=icoss3493626717ab12aff0f7bb2462",
openDecoration: "false",
pcADescUrl: "//market.m.taobao.com/app/detail-project/desc/index.html?id=678264636662&descVersion=7.0&type=1&f=icoss!0678264636662!13367810860&sellerType=B",
rootCategoryId: "50014812",
skuText: "请选择颜色分类 ",
subtitle: "德国奥拉氟 科学分龄防蛀 温和不辣口",
taobaoDescUrl: "https://market.m.taobao.com/app/detail-project/desc/index.html?id=678264636662&descVersion=7.0&type=0&f=desc/icoss3493626717ab12aff0f7bb2462&sellerType=B",
taobaoPcDescUrl: "https://market.m.taobao.com/app/detail-project/desc/index.html?id=678264636662&descVersion=6.0&type=1&f=icoss!0678264636662!13367810860&sellerType=B",
title: "兔头妈妈高纯奥拉氟儿...",
tmallDescUrl: "//mdetail.tmall.com/templates/pages/desc?id=678264636662"
},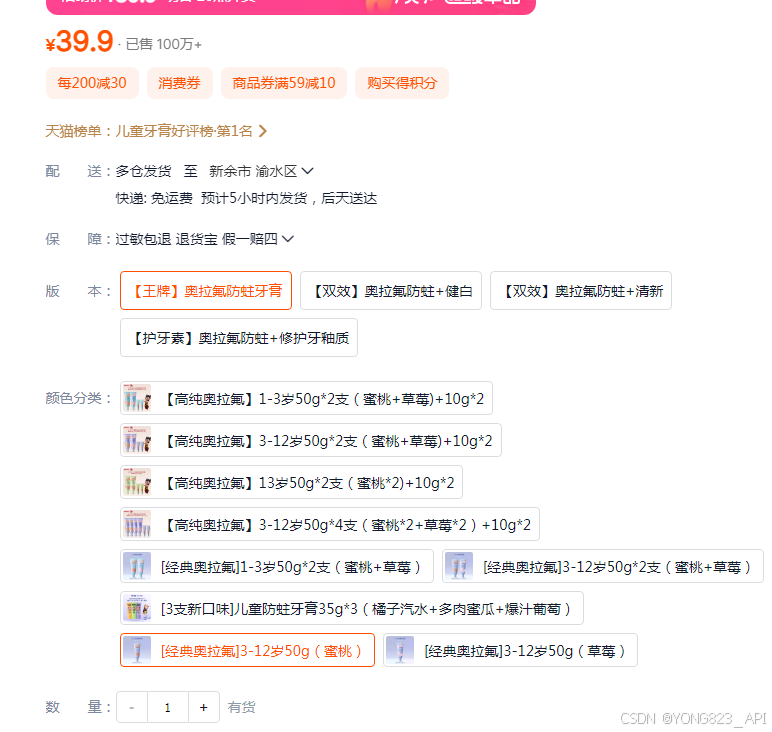
specification: [
{
pname: "颜色分类",
pid: "1627207",
values: [
{
sku_url: "http://img.alicdn.com/imgextra/i2/3691886865/O1CN01xDgMBi20aE16XHVSL_!!3691886865.jpg",
vname: "【高纯奥拉氟】1-3岁50g*2支(蜜桃+草莓)+10g*2",
vid: "36174313878"
},
{
sku_url: "http://img.alicdn.com/imgextra/i3/3691886865/O1CN010aAntH20aE175XJIV_!!3691886865.jpg",
vname: "【高纯奥拉氟】3-12岁50g*2支(蜜桃+草莓)+10g*2",
vid: "36174313879"
},
{
sku_url: "http://img.alicdn.com/imgextra/i2/3691886865/O1CN01HABHIh20aE163N2zj_!!3691886865.jpg",
vname: "【高纯奥拉氟】13岁50g*2支(蜜桃*2)+10g*2",
vid: "36174313880"
},
{
sku_url: "http://img.alicdn.com/imgextra/i1/3691886865/O1CN01tZ2jep20aE18ZjLye_!!3691886865.jpg",
vname: "【高纯奥拉氟】3-12岁50g*4支(蜜桃*2+草莓*2)+10g*2",
vid: "36174313881"
},
{
sku_url: "http://img.alicdn.com/imgextra/i3/3691886865/O1CN019FaGeE20aDyadWKvo_!!3691886865.png",
vname: "[经典奥拉氟]1-3岁50g*2支(蜜桃+草莓)",
vid: "36174313883"
},
{
sku_url: "http://img.alicdn.com/imgextra/i2/3691886865/O1CN01zBRTSq20aDsVJg8XD_!!3691886865.jpg",
vname: "[经典奥拉氟]3-12岁50g*2支(蜜桃+草莓)",
vid: "36174313882"
},
{
sku_url: "http://img.alicdn.com/imgextra/i4/3691886865/O1CN01fUvGVi20aE0O2CfyU_!!3691886865.jpg",
vname: "[3支新口味]儿童防蛀牙膏35g*3(橘子汽水+多肉蜜瓜+爆汁葡萄)",
vid: "36184330639"
},
{
sku_url: "http://img.alicdn.com/imgextra/i2/3691886865/O1CN01BToo1s20aDqfRUIxU_!!3691886865.jpg",
vname: "[经典奥拉氟]3-12岁50g(蜜桃)",
vid: "36174313884"
},
{
sku_url: "http://img.alicdn.com/imgextra/i4/3691886865/O1CN01nrhGJh20aDqjwDSMK_!!3691886865.jpg",
vname: "[经典奥拉氟]3-12岁50g(草莓)",
vid: "36174313885"
}
]
}
], 
字段解析
Version: Date:2022-04-04
| 名称 | 类型 | 必须 | 示例值 | 描述 |
|---|---|---|---|---|
| item | item[] | 1 | 宝贝详情数据 | |
| num_iid | Bigint | 1 | 520813250866 | 宝贝ID |
| title | String | 1 | 三刃木折叠刀过安检创意迷你钥匙扣钥匙刀军刀随身多功能小刀包邮 | 宝贝标题 |
| desc_short | String | 0 | 商品简介 | |
| promotion_price | Int | 0 | 优惠价 | |
| price | Float | 1 | 25.8 | 价格(当商品价格为0时,当前值为-1),价格来自于未登入的划线价格,会有个别商品价格无法与页面匹配 |
| total_price | Float | 0 | 0 | |
| suggestive_price | Float | 0 | 0 | |
| orginal_price | String | 0 | 25.80 | 原价 |
| nick | String | 0 | 欢乐购客栈 | 掌柜昵称 |
| num | Int | 0 | 3836 | 库存(没有精确,是模糊值) |
| min_num | Int | 0 | 0 | 最小购买数 |
| detail_url | String | 0 | http://item.taobao.com/item.htm?id=520813250866 | 宝贝链接 |
| pic_url | String | 1 | //gd2.alicdn.com/imgextra/i4/2596264565/TB2p30elFXXXXXQXpXXXXXXXXXX_!!2596264565.jpg | 宝贝图片 |
| brand | String | 0 | 三刃木 | 品牌名称 |
| brandId | Int | 0 | 8879363 | 品牌ID |
| rootCatId | Int | 0 | 50013886 | 顶级分类ID |
| cid | Int | 1 | 50014822 | |
| crumbs | Mix | 0 | [] | 导航菜单 |
| created_time | String | 0 | ||
| modified_time | String | 0 | ||
| delist_time | String | 0 | ||
| desc | String | 0 | 商品详情 | |
| desc_img | Mix | 0 | [] | 商品详情图片 |
| item_imgs | Mix | 0 | item_imgs[] | 商品图片 |
| item_weight | String | 0 | ||
| item_size | String | 0 | ||
| location | String | 0 | 发货地 | |
| express_fee | Float | 0 | 0.00 | 快递费用 |
| ems_fee | Float | 0 | EMS费用 | |
| post_fee | Float | 0 | 物流费用 | |
| shipping_to | String | 0 | 发货至 | |
| has_discount | Boolean | 0 | false | 是否有优惠 |
| video | video[] | 0 | 商品视频 | |
| is_virtual | String | 0 | ||
| is_promotion | Boolean | 0 | false | 是否促销 |
| props_name | String | 0 | 1627207:1347647754:颜色分类:长方形带开瓶器+送工具刀卡+链子;1627207:1347647753:颜色分类:椭圆形带开瓶器+送工具刀卡+链子; | 商品属性名。格式为pid1:vid1:name1:value1;pid1:vid2:name2:value2。 |
| prop_imgs | prop_imgs[] | 0 | 商品属性图片列表 | |
| property_alias | String | 0 | 20509:9974422:36;1627207:28326:红色;20509:9975710:38;1627207:28326:红色;20509:9981357:40;1627207:28326:红色 | 销售属性值别名。格式为pid1:vid1:alias1;pid1:vid2:alia2。 |
| props | Mix | 0 | [{ "name": "产地","value": "中国" }] | 商品属性 |
| total_sold | Int | 0 | ||
| skus | skus[] | 0 | 商品规格信息列表 | |
| seller_id | Int | 0 | 2844096782 | 卖家ID |
| sales | Int | 0 | 138 | 销量 |
| shop_id | Int | 0 | 151372205 | 店铺ID |
| props_list | Mix | 0 | {20509:9974422: 尺码:36} | 商品属性 |
| seller_info | seller_info[] | 1 | 卖家信息 | |
| tmall | Boolean | 0 | false | 是否天猫 |
| error | String | 0 | 错误信息 | |
| warning | String | 0 | 警告信息 | |
| url_log | Mix | 0 | [] | |
| favcount | Int | 0 | 0 | |
| fanscount | Int | 0 | 0 | |
| method | String | 0 | item_tmall:pget_item | |
| promo_type | String | 0 | ||
| props_img | Mix | 0 | 1627207:28326": "//img.alicdn.com/imgextra/i2/2844096782/O1CN01VrjpXt1zyCc9DvERE_!!2844096782.jpg | 属性图片 |
| shop_item | Mix | 0 | [] | |
| relate_items | Mix | 0 | [] |
测试步骤
1、注册测试账号获取key和密钥
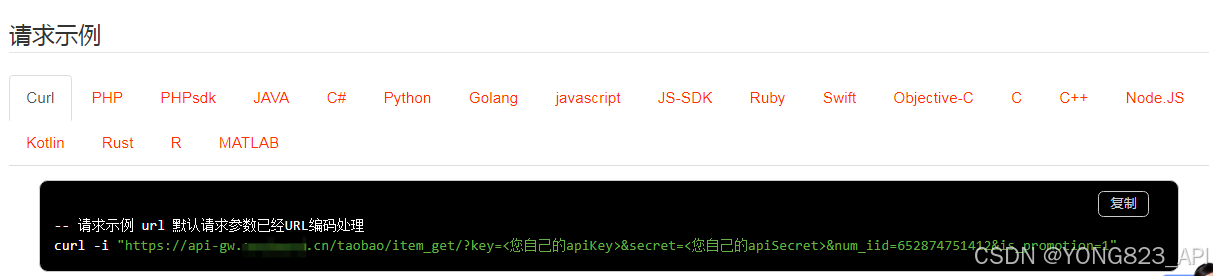
2、查看API文档请求示例
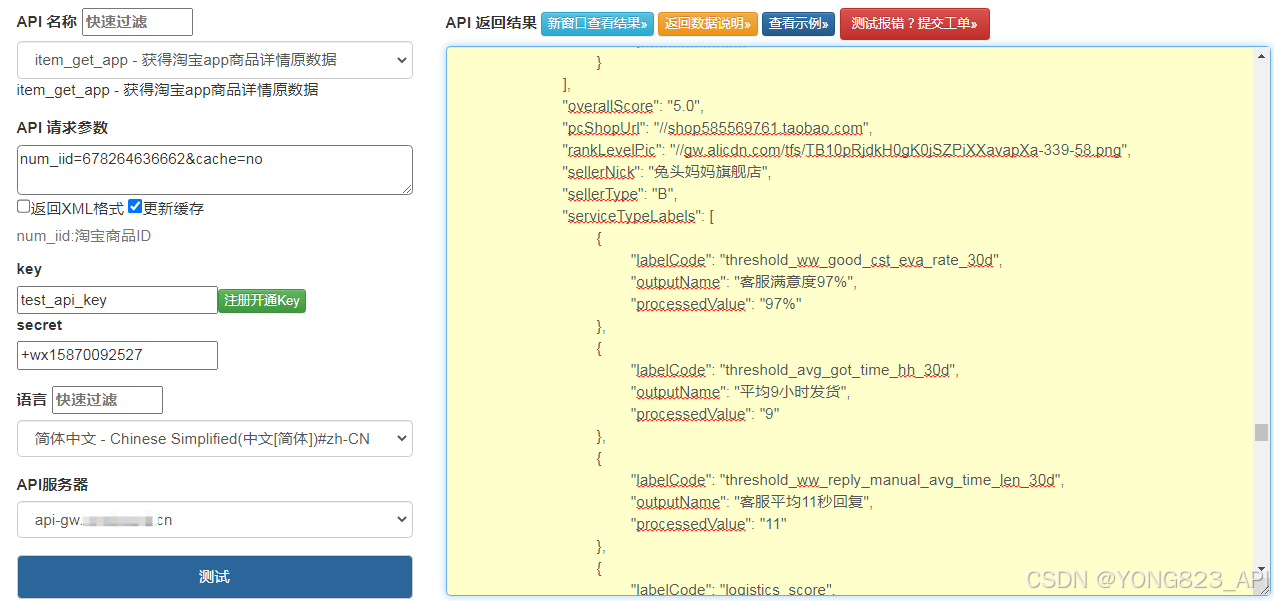
3、进入API测试页或者自行测试

















 1677
1677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









