






第二章 数仓分层与规范定义
数仓分层与规范定义
一、数仓分层
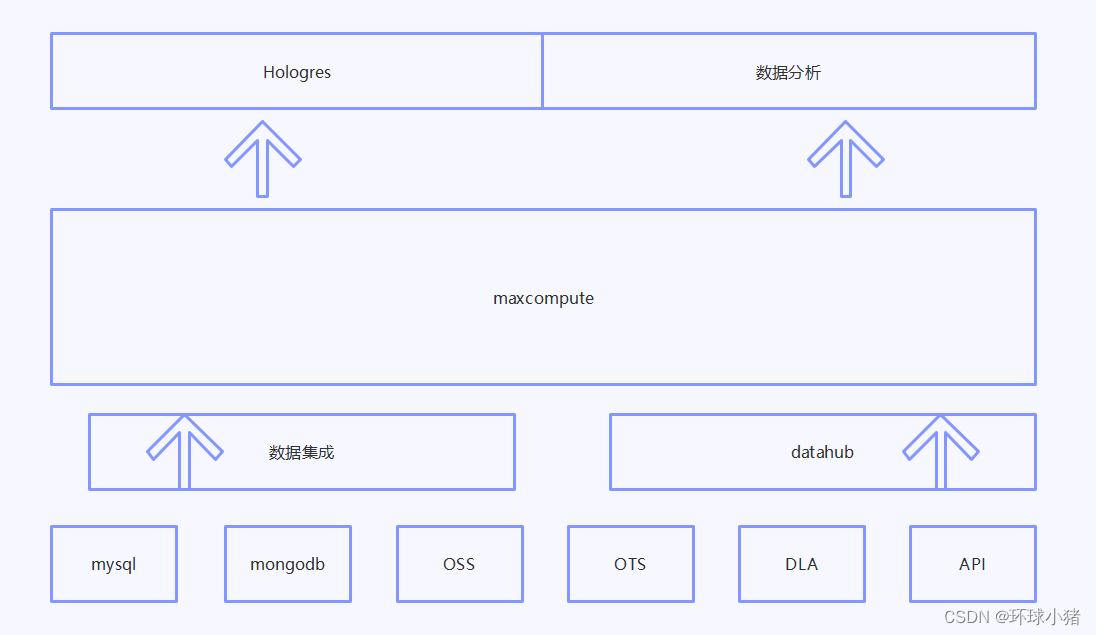
现在数仓的技术选型主要有两种:
一种是自建的CDH集群,基于hive来搭建离线数仓,基于flink的搭建实时部分。
一种是基于阿里云的dataworks这种一站式大数据开发与治理平台。
个人感觉dataworks比较好
二、设计规范
1 公共规范
1.1 数据划分及命名空间约定
请根据业务划分数据并约定命名,建议针对业务名称结合数据层次约定相关命名的英文缩写,这样可以给后续数据开发过程中,对项目空间、表、字段等命名做为重要参照。
- 按业务划分:命名时按主要的业务划分,以指导物理模型的划分原则、命名原则及使用的ODS
project。例如,按业务定义英文缩写,阿里的“淘宝”英文缩写可以定义为“tb”。 - 按数据域划分:命名时按照CDM层的数据进行数据域划分,以便有效地对数据进行管理,以及指导数据表的命名。例如,“交易”数据的英文缩写可定义为“trd”。
- 按业务过程划分:当一个数据域由多个业务过程组成时,命名时可以按业务流程划分。业务过程是从数据分析角度看客观存在的或者抽象的业务行为动作。例如,交易数据域中的“退款”这个业务过程的英文缩写可约定命名为“rfd_ent”。
1.2 公共字段定义规范
- 数据统计日期的分区字段按以下标准:
- 按天分区:ds(YYYYMMDD)。
- 按小时分区:hh(00~23)。
- 按分钟:mi(00~59)。
- is_{业务}:表示布尔型数据字段。以Y和N表示,不允许出现空值域。
- 原则上不需要冗余分区字段。
- 含业务含义字段默认值:
涉及金额字段默认值:0.00
涉及数量字段默认值:0
涉及数字型字段默认值:-9
字符类字段默认值: -
date型默认值:1970-01-01
timestamp型默认值:1970-01-01 00:00:00.000
| mysql数据类型 | hive数据类型 | MaxCompute数据类型 | |
|---|---|---|---|
| 整型 | bigint | BIGINT | BIGINT |
| 整型 | int | BIGINT | BIGINT |
| 整型 | smallint | BIGINT | BIGINT |
| 整型 | tinyint | BIGINT | BIGINT |
| 浮点型 | decimal | decimal | decimal |
| 浮点型 | double | DOUBLE | DOUBLE |
| 浮点型 | float | DOUBLE | FLOAT |
| 二进制 | binary | BINARY | STRING |
| 二进制 | varbinary | BINARY | STRING |
| 字符 | char | STRING | STRING |
| 字符 | varchar | STRING | STRING |
| 字符 | mediumtext | STRING | STRING |
| 字符 | text | STRING | STRING |
| 时间 | datetime | STRING | datetime |
| 时间 | time | STRING | STRING |
| 时间 | timestamp | STRING | STRING |
| 时间 | date | date | date |
2 设计规范
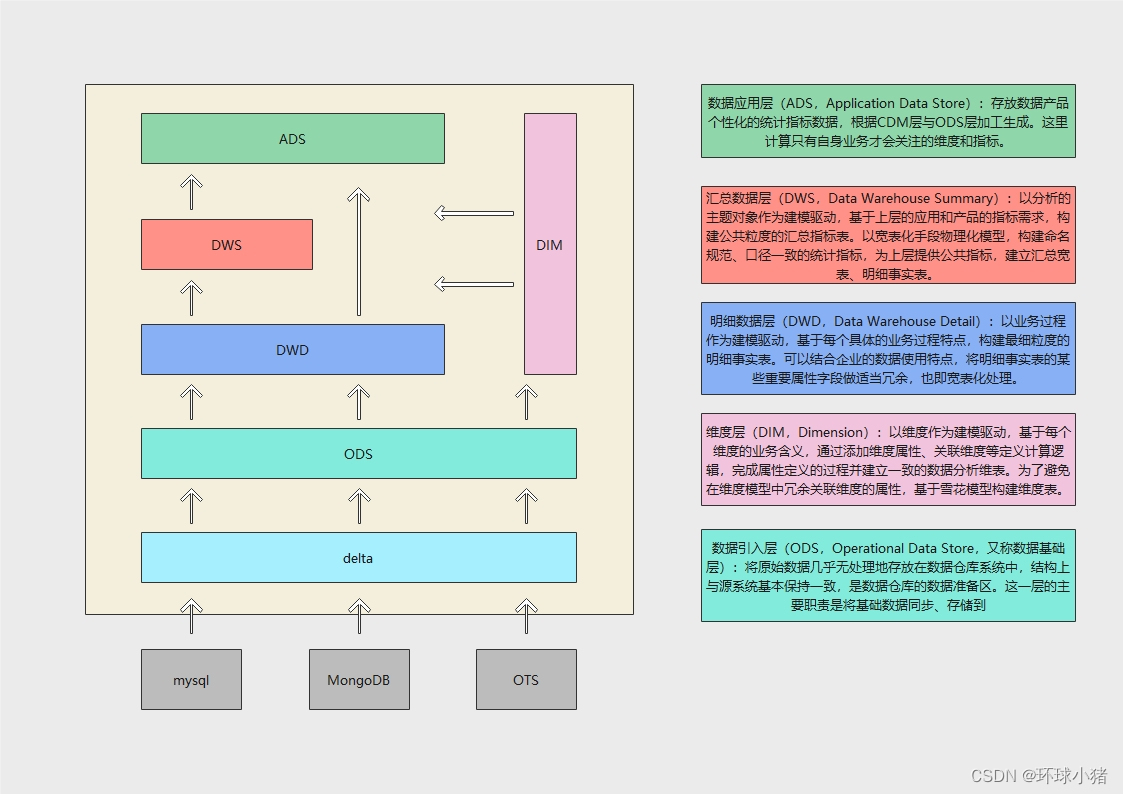
ods层
ODS(Operational Data Store)层存放您从业务系统获取的最原始的数据,是其他上层数据的源数据。业务数据系统中的数据通常为非常细节的数据,经过长时间累积,且访问频率很高,是面向应用的数据
-
表命名规范
表命名规则:{层次}下划线{源系统表名}下划线{保留位/delta与否}。- 增量数据:ods_{源系统表名}_delta。
- 全量数据:ods_{源系统表名}。
- ODS ETL过程的临时表:tmp_{临时表所在过程的输出表}_{从0开始的序号}。
- 按小时同步的增量表:ods_{源系统表名}__{delta}_{hh}。
- 按小时同步的全量表:ods_{源系统表名}_{hh}。
当不同源系统同步到同一个Project下的表命名冲突时,您需要给同步较晚的表名加上源系统的dbname以解决冲突。
-
字段命名规范
- 字段默认使用源系统的字段名。
- 字段名与关键字冲突时,在源字段名后加上col,即源字段名col。
dim层
公共维度汇总层(DIM)主要由维度表(维表)构成。维度是逻辑概念,是衡量和观察业务的角度。维表是根据维度及其属性将数据平台上构建的物理化的表,采用宽表设计的原则。因此,公共维度汇总层(DIM)首先需要定义维度。
设计维表的主要步骤如下:
- 初步定义维度。
保证维度的一致性。 - 确定主维表(中心事实表,本教程中采用星型模型)。
此处的主维表通常是数据引入层(ODS)表,直接与业务系统同步。例如,s_auction是与前台商品中心系统同步的商品表,此表即是主维表。 - 确定相关维表。
数据仓库是业务源系统的数据整合,不同业务系统或者同一业务系统中的表之间存在关联性。根据对业务的梳理,确定哪些表和主维表存在关联关系,并选择其中的某些表用于生成维度属性。以商品维度为例,根据对业务逻辑的梳理,可以得到商品与类目、卖家和店铺等维度存在关联关系。 - 确定维度属性。
主要包括两个阶段。第一个阶段是从主维表中选择维度属性或生成新的维度属性;第二个阶段是从相关维表中选择维度属性或生成新的维度属性。以商品维度为例,从主维表(s_auction)、类目、卖家和店铺等相关维表中选择维度属性或生成新的维度属性。维度属性的设计需要注意:- 尽可能生成丰富的维度属性。
- 尽可能多地给出富有意义的文字性描述。
- 区分数值型属性和事实。
- 尽量沉淀出通用的维度属性。
公共维度汇总层(DIM)维表命名规范: dim_{业务板块名称/pub}{维度定义}[{自定义命名标签}],pub是与具体业务板块无关或各个业务板块都可公用的维度。例如,时间维度;
dwd层
明细粒度事实层DWD(Data Warehouse Detail)以业务过程驱动建模,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。您可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。
通常您需要遵照的命名规范为:dwd_{业务板块/pub}{数据域缩写}{业务过程缩写}[_{自定义表命名标签缩写}] _{单分区增量全量标识},pub表示数据包括多个业务板块的数据。单分区增量全量标识通常为:i表示增量,f表示全量。例如: dwd_asale_trd_ordcrt_trip_di(A电商公司航旅机票订单下单事实表,日刷新增量)及dwd_asale_itm_item_df(A电商商品快照事实表,日刷新全量)。
dws层
公共汇总粒度事实层DWS(Data Warehouse Summary)以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求构建公共粒度的汇总指标事实表。公共汇总层的一个表至少会对应一个派生指标。
公共汇总事实表命名规范:dws_{业务板块缩写/pub}{数据域缩写}{数据粒度缩写}[{自定义表命名标签缩写}]{统计时间周期范围缩写}。
关于统计实际周期范围缩写,缺省情况下,离线计算应该包括最近一天(_1d),最近N天(_nd)和历史截至当天(_td)三个表。如果出现_nd的表字段过多需要拆分时,只允许以一个统计周期单元作为原子拆分。即一个统计周期拆分一个表,例如最近7天(_1w)拆分一个表。不允许拆分出来的一个表存储多个统计周期。















 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









