






上个月著名的日本企业家稻盛和夫去世, 终年90岁,被各种惋悼软文鸡汤了一波, 除了最后的小广告, 内心还是被激荡了一把,碰巧最近在较为繁忙的时期(虽然很忙,但是项目感觉不赚钱…), 在一度思考是不是要重选方向的时候, 刷到了一篇个人非常认同的文章, 具体内容记不太精确了, 就记得那个观点,也非常认同, “一个人对待工作的态度,决定了他的人生走向.”
最近老是听着几位小朋友们议论班上的学霸数学靠多少分,英语多少分, 什么作文又被贴去全年级公示, 作为一位过来人(不要误会,我不是学霸,我意思是谁不曾是少年呢?), 大概也看透学霸的厉害之处并不是能拿多高的分数或者拿到多少的奖项, 对待学习的态度和专注,才是其能一直优,一直秀的内核.
厄, 喝了几口啤酒差点快忘了文章主题了, 先言归正传吧,哈哈. 有点想不出写什么了, 先上一张图撑一下篇幅吧.
据说能看清楚这张图的人, 基本就弄清楚分布式计算的核心问题了(可别真的放大来看了, 伤了眼睛不好), 一度怀疑是谁泄露了风声, 后面想起是自己在加班申请单上写了模块分布式改造的内容, 应该被领导关注到了, 所以忍不住要亲自给出批示指示, 非常感谢, 也澄清一下, 白板内容拍照是征求了同意, 并且所有内容都是我画的(领导的原话差不多是, 画成这样你都好意思给别人看…), 字丑鬼画符都是我的心病了, 跟领导的字风比起来确实遥不可及(居然大胆敢做对比)…
话说回来, 上次"<为什么要实现分布式计算(一) >"文中最后是留了一个问题, 估计没几个同学关心了吧, 感觉还是先回答一下, 就是那个While(true)里循环的问题,
//伪代码
//程序崩溃主要原因: while循环没做控制,会不停的从数据库把1000万的数据都查出来组装成对象, 以一定数量的形式放入到 executors线程池中多线程执行, 而当执行速度较慢的时候, 查出来的对象都堆积在线程池的待处理队列里, 也就是jvm内存里,而计算过程本身比较慢,还会产生大量的查询以及对象, 不出意外的话, 意外马上就会发生了, 本身只有8G内存的服务器瑟瑟发抖干脆就跪了...
while(true){
//所有数据都被查询到内存里了..
List list = jdbcTemplate.queryForList("分页查询sql");
//当查不到结果,终止循环.
if(list==null||list.size<=0){
break;
}
//是多线程,但是总数有限,效率一般,垃圾回收也没用,对象没变成垃圾前,不应该抛弃的,所以刚才查出来的数据对象都被堆到内存里了.
executors.execute(new Task(list));
}
当时发现了这个问题之后, 某汤同事做了调整, 就是在线程池的线程里做循环, 可以这么理解, 比如有100万个人要做核酸, 然后有10个核验窗口.
改造前就是100万人都塞到了广场上排队去了, 结果广场直接瘫痪了…
改造后就是, 还是那10个核验窗口, 但是这100万人都在家里(数据库)等通知, 每1000, 1000个的用大巴拉过去, 反正验完了就拉…不停的拉…拉拉拉…然后, 某薛同事说, 你们开发搞啥…一晚上只能算30万个主体, 我在数据库一会就跑完了…这次广场没事, 某汤同事瘫痪了…被鄙视得快瘫平了…
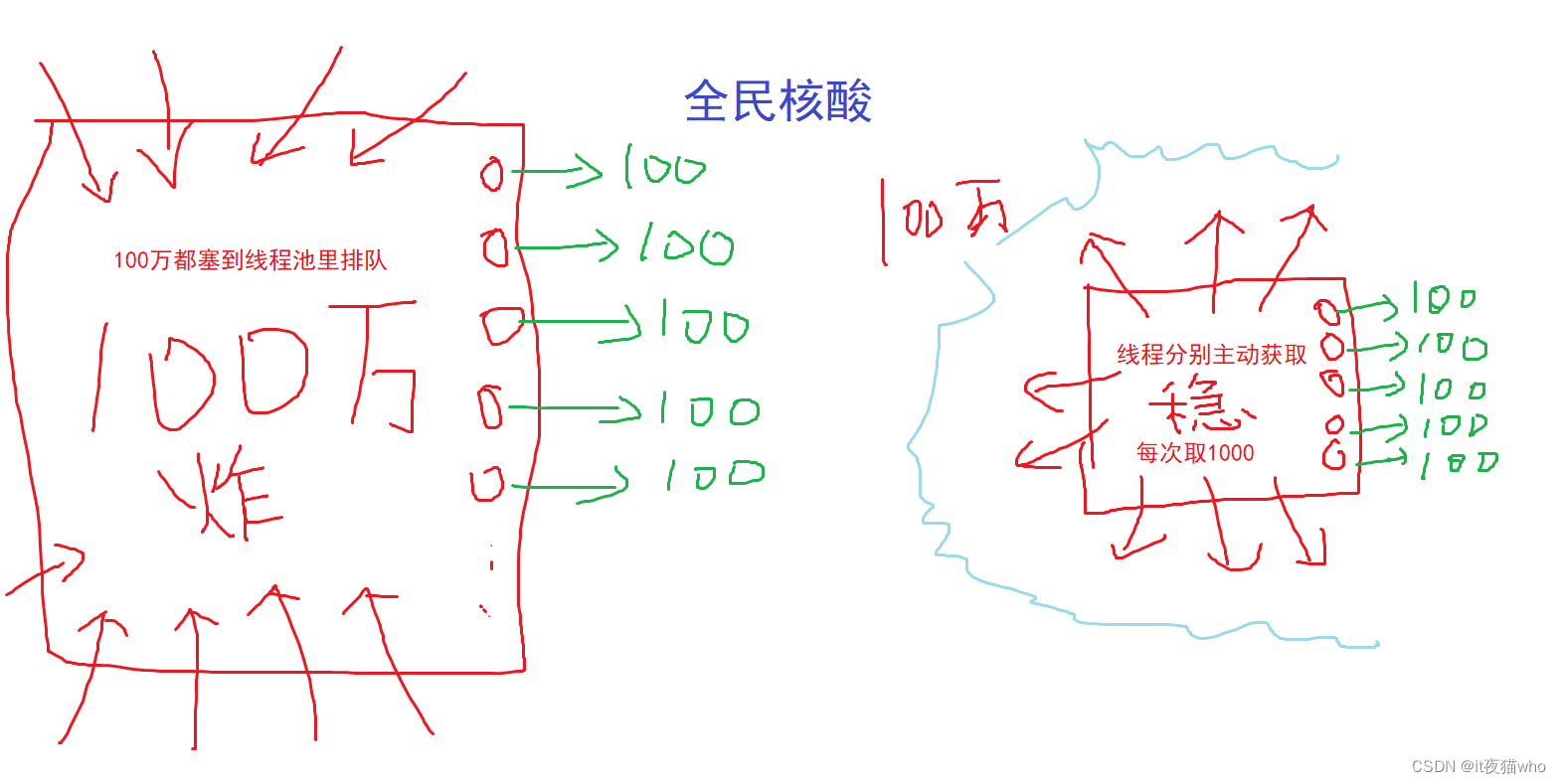
居然被数据组同事鄙视程序不行?! 作为开发怎么能忍?于是马上跟项目经理说明了情况短时间内还是先用着数据组的脚本结果, 确实没他们处理得好… 然后洗心革面重新检讨检查, 原来的单线程已经改为多线程版本了, 一分钟稳定计算量是20个…初判发现, 这才1台主机在跑, 线程数量什么的也没完全调优过, 结果也是一个一个commit保存的, 核心计算那里的递归也比较的复杂, 按照经验, 复杂的地方也会是问题大概率发生的地方之一.
说那么久, 终于要上分布式计算的内容了, 分布式计算实际也并没那么玄乎, 继续拿全民核酸的例子来说吧, 为了稳定, 每个广场,每次就大巴拉1000个人过去, 做完就下一批. 分布式计算相当于, 同样的广场和窗口, 多复制几份, 就是如下:

在硬件相对廉价的今天, 哪还有什么程序员去专门优化代码…单机不行, 那就数量取胜, 个人理解分布式计算实际就是用了资源空间换时间的概念, 把一个较大的计算任务解耦拆分到不同的计算节点上, 最后把结果汇集得出最终结果.
分布式计算真正要解决的复杂问题实际是最终结果一致性/计算稳定性的问题, 比如中途一大巴抛锚了… 两台大巴同时去了你家接你, 你刚做完核酸回到家, 又被另外一台大巴拉去了广场…每个广场每条队伍的进展情况如何啊…诸如此类. 所以分布式还是需要一个任务分发/汇聚中心的. 常规做法要么用数据库, 要么…用其他组件.
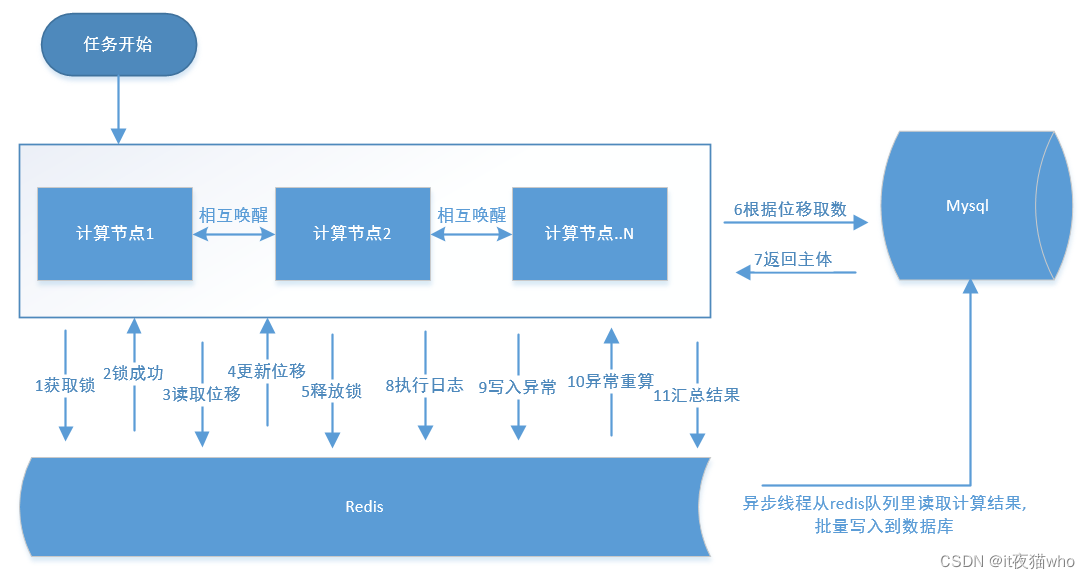
因为项目用了redis(内存数据库,分布式集群), 所以直接是用了redis作为任务的控制中心, 每台服务器启动时, 都先把自己注册到redis中, 某台应用定时任务启动时, 会先做一个唤醒其他应用启动计算的动作, 然后服务器基本就是按着下图的1~11顺序执行, 也是用了redis作为了中心控制器, 每次都会先去取一把锁, 锁获取成功再领取任务, 更新任务位置后释放锁, 避免多台应用同时获取到了相同的任务, 重复计算浪费资源不说, 还很有可能发生奇奇怪怪的问题. 图中表达的不是很好, 就是每个节点的计算结果也会放入一个redis队列中, 由应用的单个线程从队列里获取数据, 再批量的插入到数据库中, 减少了数据库网络连接的开销, 正常人都知道jdbc批量提交会比单个commit要快吧.
.
经过一顿猛如虎的操作之后…计算速度从每分钟的20提升到了每分钟6000…啊, 好高兴, 单机提升了300倍…看着提升数据挺爽, 实际问题呢? 是的…并没有解决, 每分钟6000. 双机就是12000. 要算完700万个主体. 那就是需要…自己算一下, 还是太漫长了. 依然会被某薛同事鄙视的. 问了下原来能被用来计算的机器貌似也只有3台. 那最多也就是18000个/分钟…略有提升但还是太慢了.
最终还是要对那段祖传代码下手. 原来的评价模型里面的每个指标实际是转化为一个查询语句, 而那段递归里面最终是通过叶子节点指标, 拿到查询sql, 执行数据库查询, 再根据模型里的指标权重进行得分计算汇总. 本身递归不慢的, 问题出在递归过程需要执行40个指标获取sql. 按照700万的主体, 那就是一个笛卡尔积, 要执行…好多遍sql. 已目前这个数据库的调优情况来看, 不挂都感觉可以喝一杯…
知道病症, 马上着手改了一下指标计算方式, 提前把40个指标sql获取到, 形成1个大的查询sql, 直接发送给数据, 再把数据结果给模型计算函数进行计算. 性能从每分钟计算6000, 提升到了40000… 单机继续提升了7倍. 对比原始版本, 提升有2000+倍. 双机的话, 1个小时计算完还是勉强能接受的, 毕竟还是有网络传输和IO的制约, 达不到查几个脚本花几分钟就完成计算这么夸张的效率. 但是灵活程度还是会比纯脚本要好…
计划下一步试一下批量获取指标结果, 再进行批量运算, 进一步压缩数据传输和网络次数…

快写完的时候, 群里发来了某领导的友情提醒…突然想起一句话"我真的会谢"(我真的会感谢的意思), 要不还是别计划了, 马上动手是不是更合适? 大晚上不睡觉不好, 还是去吃口夜宵吧.
















 5029
5029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











